matrixProfile
構文
説明
行列プロファイルは、時系列内の非常によく似たサブシーケンスか大きく異なるサブシーケンスを特定することで異常動作を検出する距離ベースの手法です。
同様のサブシーケンス ("モチーフ") は、多くの場合、時系列内の通常動作を表します。特異なサブシーケンス ("不一致") は、異常の可能性を示します。アルゴリズムにより、各サブシーケンス ペアの z 正規化ユークリッド距離を計算することで、時系列内のすべてのサブシーケンスが同じ長さの他のすべてのサブシーケンスと比較されます。それらの間の最小距離をもつサブシーケンス ペアを "最近傍" と呼びます。matrixProfile は、それらの最小距離 (小さいものから大きいものの順) とプロファイル内の対応する最近傍のインデックスを含むベクトルまたは行列を返します。
行列プロファイルを返す
MP = matrixProfile(X,len)X の "行列プロファイル" を返します。行列プロファイルは、X の長さ len の各サブシーケンスとそれに最も近い近傍との間の最小の z 正規化ユークリッド距離のベクトルです。
Xがベクトルの場合、単一チャネルとして扱われます。Xが行列の場合、各列について行列プロファイルが別々に計算されます (多変量解)。
matrixProfile には、計算を実行するためのアルゴリズムが 2 種類あります。
STAMP アルゴリズム (Scalable Time series Anytime Matrix Profile) は、随時および並列の計算をサポートしており、単変量と多変量のどちらのデータ セットでも機能します。"随時" の機能では、完了前にアルゴリズムを停止することができ、それでも許容できる精度の解が得られます。これは、完全な解の計算にかなりの時間がかかる場合に特に便利です。計算をいつ停止するかは、名前と値の引数
MaxIterationで決まります。STOMP アルゴリズム (Scalable Time series Ordered Matrix Profile) は、STAMP アルゴリズムよりも約 log2(n) 倍高速です。これは、GPU があり、随時の機能は必要がない場合の単変量時系列に便利です。
MP の上位の不一致およびモチーフの位置は、関数 findDiscord および findMotif を使用して検出できます。
[___] = matrixProfile(___,Name=Value) は、前述の構文の引数に加えて、1 つ以上の名前と値の引数を使用してオプションを指定します。たとえば、並列処理を使用するには、UseParallel を true に設定します。
行列プロファイルのプロット
matrixProfile(___) は、行列プロファイルの対話型プロットを表示します。この構文は、前述の任意の入力引数の組み合わせで使用できます。
例
T1 で構成されるデータを読み込みます。T1 は、劣化する DC モーターの電機子電流の測定値を含む timetable です。
load matrix_profile_data T1
時系列変数 X を T1.MotorCurrent、クエリ セグメントの長さを 100 と指定します。
X = T1.MotorCurrent; len = 100;
行列プロファイルを計算します。
[MP,MPI] = matrixProfile(X,len);
行列プロファイルをプロットします。
matrixProfile(X,len)
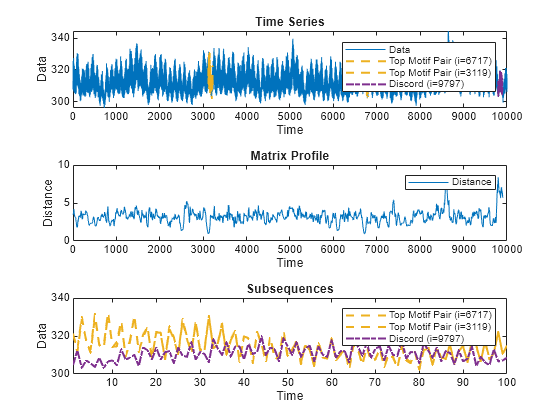
プロファイルに上位のモチーフ ペア (近傍と最も整合するセグメント) が 2 つ示されており、その位置は 6717 と 3119 です。これらの位置は行列プロファイル プロットの最小値と一致しています。
さらに、位置 9797 に不一致が 1 つ示されています。このサブシーケンスは、その長さの大部分でモチーフのサブシーケンスから明らかに逸脱しています。
findDiscord を使用して不一致をさらに検出します。これは、近傍からの距離が最も離れているセグメントの位置です。上位 4 つの位置を表示します。
locs = findDiscord(MP,MPI); toplocs = locs(1:4)
toplocs = 4×1
9797
9800
9802
9792
対応する距離を表示します。
topdist = MP(toplocs)
topdist = 4×1
8.3894
8.2062
8.1517
7.9777
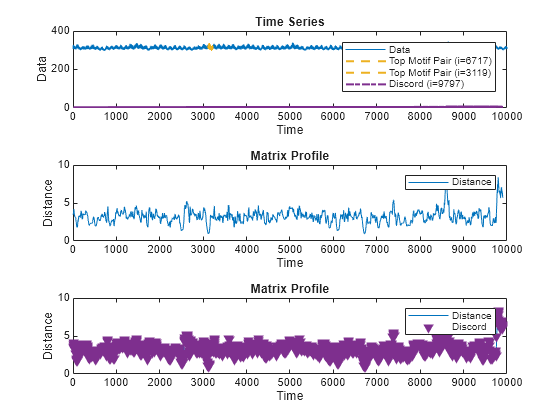
findDiscord の結果をプロットします。
figure findDiscord(MP,MPI)
互いに近くにある不一致は同じ異常の一部と考えられます。そのようなセグメントについては、不一致を 1 つだけ特定する必要があります。セグメントの間隔を改善し、不一致の数を 10 個までに制限します。
findDiscord(MP,MPI,MinSeparation=40,MaxNumDiscords=10)
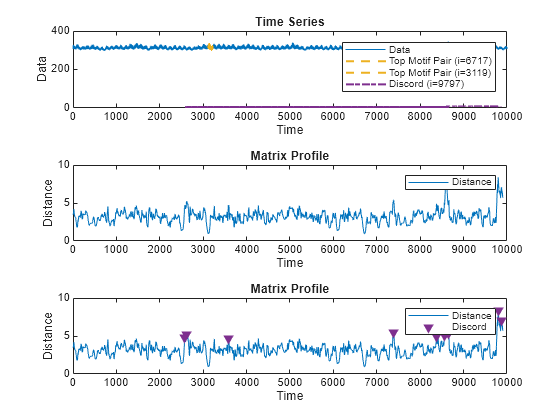
元の行列プロファイルで示されているように、最も高い不一致の位置は 9797 です。それ以外の位置の有意な不一致もプロットに示されています。
入力引数
名前と値の引数
出力引数
参照
[1] Yeh, Chin-Chia Michael, et al. “Matrix Profile I: All Pairs Similarity Joins for Time Series: A Unifying View That Includes Motifs, Discords and Shapelets.” 2016 IEEE 16th International Conference on Data Mining (ICDM), IEEE, 2016, pp. 1317–22. DOI.org (Crossref), https://doi.org/10.1109/ICDM.2016.0179.
[2] Zhu, Yan, et al. “Matrix Profile II: Exploiting a Novel Algorithm and GPUs to Break the One Hundred Million Barrier for Time Series Motifs and Joins.” 2016 IEEE 16th International Conference on Data Mining (ICDM), IEEE, 2016, pp. 739–48. DOI.org (Crossref), https://doi.org/10.1109/ICDM.2016.0085.