このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
similarityDistance
構文
説明
[___] = similarityDistance( は、x,y,EndPoints=outputLengths)x がサブシーケンスの途中で終わっている場合に出力ベクトルの長さをどのように扱うかを指定します。
この構文は、前述の構文の入力引数および出力引数のいずれかと一緒に使用します。
例
T1 および T2 で構成されるデータを読み込みます。T1 は、劣化する DC モーターの電機子電流の測定値を含む timetable です。T2 は、既知の故障したモーターから収集されたデータを含む timetable です。
load matrix_profile_data T1 T2
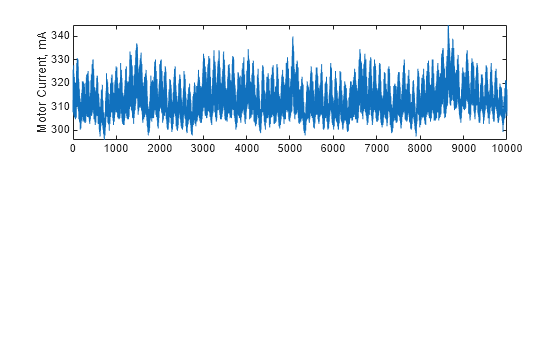
x を T1 の MotorCurrent 変数に設定します。x をサブプロットにプロットします。
x = T1.MotorCurrent; subplot(211) plot(x) ylabel("Motor Current, mA") hold on
T2 の位置 3000 から始まる長さが 100 のセグメントに異常状態のデータがあります。このデータをターゲット セグメント y として抽出します。
len = 100; loc = 3000; iy = loc:loc+len-1; y = T2.MotorCurrent(iy);
x のモーター データ内のサブシーケンスに対するターゲット異常セグメント y の類似度距離を計算します。
[d,i] = similarityDistance(x,y);
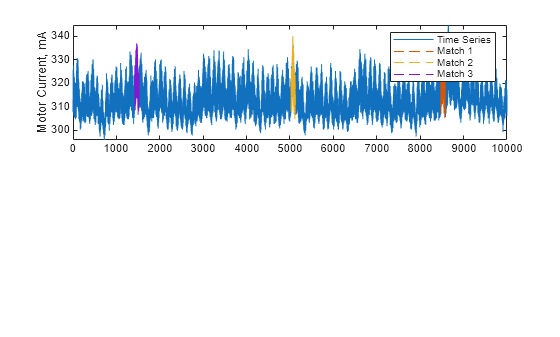
i の最初の 3 つのインデックスを使用して、最も一致度の高い 3 つのサブシーケンスをプロットします。これらの一致は、y の異常に潜在的に類似した異常を示しています。
for k = 1:3 id = i(k):i(k)+len-1; plot(id,x(id),"--"); hold on end legend({"Time Series", "Match 1", "Match 2", "Match 3"}) hold off
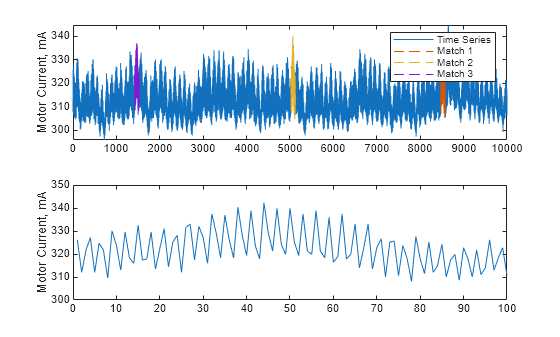
比較のために、ターゲット異常シーケンスをプロットします。
subplot(212) plot(y); hold on ylabel("Motor Current, mA")
3 つの一致するサブシーケンスのデータをターゲット異常と共にプロットします。
for k = 1:3 id = i(k):i(k)+len-1; plot(x(id),"--"); hold on end legend({"Target Anomaly", "Match 1", "Match 2", "Match 3"}) hold off
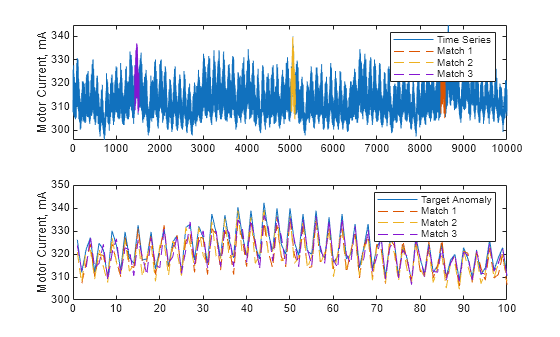
一致するサブシーケンスがターゲット異常に類似しているように見えます。
入力引数
出力引数
参照
[1] Abdullah Mueen, Sheng Zhong, Yan Zhu, Michael Yeh, Kaveh Kamgar, Krishnamurthy Viswanathan, Chetan Kumar Gupta, and Eamonn Keogh, The Fastest Similarity Search Algorithm for Time Series Subsequences Under Euclidean Distance, 2022. https://www.cs.unm.edu/%7Emueen/FastestSimilaritySearch.html
拡張機能
バージョン履歴
R2024b で導入