ncread
netCDF データ ソース内の変数からデータを読み取る
構文
説明
例
example.nc netCDF ファイルから peaks という名前の変数を読み取り、プロットします。
peaksData = ncread("example.nc","peaks"); whos peaksData
Name Size Bytes Class Attributes peaksData 50x50 5000 int16
peaksData をプロットして、タイトルを追加します。
surf(peaksData)
title("Peaks Data")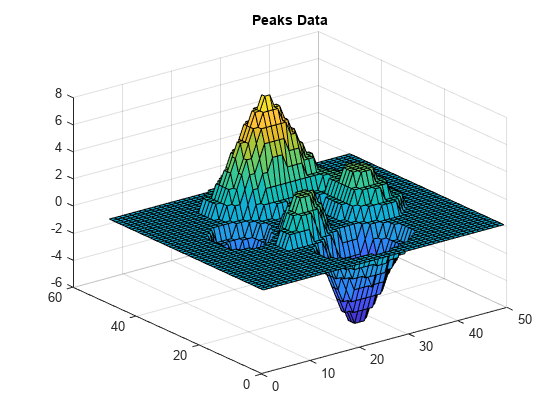
peaks 変数データのうち、位置 [25 17] から各次元の末尾までの部分のみを読み取ってプロットします。
start = [25 17]; % Start location along each coordinate count = [Inf Inf]; % Read until the end of each dimension peaksData = ncread("example.nc","peaks",start,count); whos peaksData
Name Size Bytes Class Attributes peaksData 26x34 1768 int16
データをプロットします。
surf(peaksData)
title("Peaks Data Starting at [25 17]")![Figure contains an axes object. The axes object with title Peaks Data Starting at [25 17] contains an object of type surface.](../../examples/matlab/win64/ReadVariableStartingAtSpecifiedCoordinatesExample_01.png)
データを読み取ってプロットします。ここで、データは各次元に沿って、指定された変数インデックス間の間隔でサンプリングされます。start の位置から開始し、stride で指定された間隔で変数データを読み取ります。stride の値が 1 の場合、対応する次元内の隣接する値にアクセスします。値が 2 の場合、対応する次元内の値に 1 つおきにアクセスし、以降同様に繰り返されます。
start = [1 1]; count = [10 15]; stride = [2 3]; sampledPeaksData = ncread("example.nc","peaks",start,count,stride); whos sampledPeaksData
Name Size Bytes Class Attributes sampledPeaksData 10x15 300 int16
データをプロットします。
surf(sampledPeaksData)
title("Peaks Data Subsampled by [2 3]")![Figure contains an axes object. The axes object with title Peaks Data Subsampled by [2 3] contains an object of type surface.](../../examples/matlab/win64/SubsampleVariableDataExample_01.png)
入力引数
出力引数
詳細
ヒント
MATLAB はデータを列優先として解釈しますが、netCDF C API はデータを行優先として解釈します。netCDF C API の多次元データは、MATLAB で示される順序の逆順で次元を示すため、結果として転置されて表示されます。