MapReduce 入門
データ収集デバイスの数とタイプが年々増えているため、収集されるデータのサイズそのものと収集の速度は急速に拡大しています。これらのビッグ データ セットは、ギガバイトまたはテラバイトのデータを含み、毎日メガバイトまたはギガバイトの単位で増加するものもあります。このような情報の収集により、本質を理解する機会が生まれますが、多くの課題も提起します。ほとんどのアルゴリズムは、妥当な時間内または妥当なメモリ量でビッグ データ セットを処理するようには設計されていません。MapReduce を使用すると、これらの課題の多くを解決して大規模なデータ セットから貴重な洞察を得ることができます。
MapReduce とは
MapReduce とは、メモリに収まらないデータ セットを解析するプログラミング手法です。Hadoop® MapReduce はよく知られており、これは Hadoop 分散ファイル システム (HDFS™) で機能する、広く使用されている実装です。MATLAB® は、mapreduce 関数を使用して、MapReduce 手法を若干異なる形で実装しています。
mapreduce は、データストアを使用して、メモリに個別に収まる小さいブロックごとにデータを処理します。各ブロックは Map フェーズを経ますが、そこでは処理されるデータの書式設定を行います。次に、中間データ ブロックが Reduce フェーズを経て中間結果を集計し、最終結果が生成されます。Map フェーズと Reduce フェーズは、"map" 関数および "reduce" 関数によってエンコードされています。これらが mapreduce への主な入力となります。データを処理するための map 関数と reduce 関数の組み合わせは無限にあるため、この方法は柔軟かつ非常に強力に、大規模データ処理タスクに対処できます。
mapreduce は、いくつかの環境で実行できるように拡張できます。これらの機能の詳細については、その他の製品を使用した MapReduce の高速化と展開を参照してください。
mapreduce 関数の有用性は、大規模なデータ コレクションに対して計算を実行できる機能にあります。したがって、mapreduce は、コンピューターのメモリに直接読み込む従来の方法で解析できるような "通常の" サイズのデータ セットの計算には適していません。そうではなく、メモリに収まらないデータ セットの統計的または解析的計算を実行するために、mapreduce を使用します。
mapreduce による、map 関数または reduce 関数の各呼び出しは、他のすべてのものから独立しています。たとえば、map 関数の呼び出しは、map 関数への以前の呼び出しの入力や結果に依存することはできません。このような計算は、mapreduce の複数の呼び出しに分割するのが最適です。
MapReduce のアルゴリズム フェーズ
mapreduce では、入力データストア内のデータの各ブロックがいくつかのフェーズを経た後、最終出力に到達します。次の図に、mapreduce のアルゴリズムのフェーズの概要を示します。
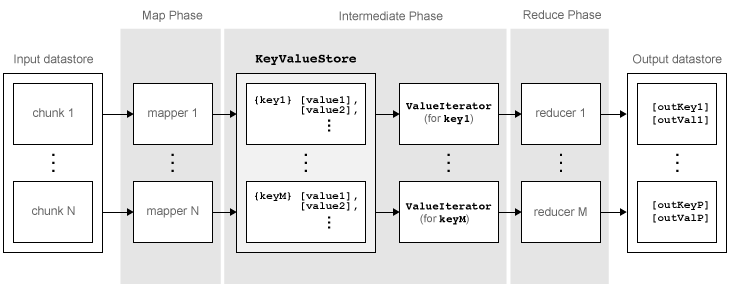
アルゴリズムには次のステップがあります。
mapreduceは、[data,info] = read(ds)を使用して入力データストアからデータのブロックを読み取り、次に map 関数を呼び出してそのブロックを処理します。map 関数はデータのブロックを受け取り、整理または前処理となる計算を実行してから、
add関数とaddmulti関数を使用してキーと値のペアをKeyValueStoreという中間データ ストレージ オブジェクトに追加します。mapreduceが map 関数を呼び出す回数は、入力データストア内のブロック数と同じです。map 関数がデータストア内のデータのブロックをすべて処理した後、
mapreduceは中間KeyValueStoreオブジェクト内のすべての値を一意なキーでグループ化します。次に
mapreduceは、map 関数で追加された一意なキーごとに reduce 関数を 1 回呼び出します。各一意なキーには、多くの値が関連付けられている場合があります。mapreduceは、その値を reduce 関数にValueIteratorオブジェクトとして渡します。これは値を反復処理するために使用するオブジェクトです。各一意なキーに対するValueIteratorオブジェクトは、そのキーのすべての関連値を含みます。reduce 関数は、
hasnext関数およびgetnext関数を使用して、ValueIteratorオブジェクト内の値を一度に 1 つずつ反復処理します。reduce 関数は次に、map 関数からの中間結果を集計してから、最後のキーと値のペアを、add関数とaddmulti関数を使用して出力に追加します。出力内のキーの順序は、reduce 関数が最後のKeyValueStoreオブジェクトにキーを追加する順序と同じです。つまり、mapreduceは出力を明示的に並べ替えることはありません。reduce 関数は、最後のキーと値のペアを最後のKeyValueStoreオブジェクトに書き込みます。mapreduceは、このオブジェクトからキーと値のペアを出力データストアに引き出します。このデータストアは既定ではKeyValueDatastoreオブジェクトです。
MapReduce の計算例
この例では、簡単な計算 (一連の飛行データ内の平均飛行距離) を使用して、mapreduce を実行するのに必要な手順を解説します。
データの準備
mapreduce を使用する最初の手順は、データ セットのためのデータストアを作成することです。map 関数および reduce 関数の他に、データ セットのデータストアも mapreduce への入力として必須です。これにより、mapreduce はデータをブロック単位で処理できるからです。
mapreduce はほとんどの種類のデータストアで機能します。たとえば、airlinesmall.csv データ セットに対して TabularTextDatastore オブジェクトを作成します。
ds = tabularTextDatastore('airlinesmall.csv','TreatAsMissing','NA')
ds =
TabularTextDatastore with properties:
Files: {
' .../Bdoc26a_3146167_1317206/tp4990765e/matlab-ex76309484/airlinesmall.csv'
}
Folders: {
'/tmp/Bdoc26a_3146167_1317206/tp4990765e/matlab-ex76309484'
}
FileEncoding: 'UTF-8'
AlternateFileSystemRoots: {}
VariableNamingRule: 'modify'
ReadVariableNames: true
VariableNames: {'Year', 'Month', 'DayofMonth' ... and 26 more}
DatetimeLocale: en_US
Text Format Properties:
NumHeaderLines: 0
Delimiter: ','
RowDelimiter: '\r\n'
TreatAsMissing: 'NA'
MissingValue: NaN
Advanced Text Format Properties:
TextscanFormats: {'%f', '%f', '%f' ... and 26 more}
TextType: 'char'
ExponentCharacters: 'eEdD'
CommentStyle: ''
Whitespace: ' \b\t'
MultipleDelimitersAsOne: false
Properties that control the table returned by preview, read, readall:
SelectedVariableNames: {'Year', 'Month', 'DayofMonth' ... and 26 more}
SelectedFormats: {'%f', '%f', '%f' ... and 26 more}
ReadSize: 20000 rows
OutputType: 'table'
RowTimes: []
Write-specific Properties:
SupportedOutputFormats: ["txt" "csv" "dat" "asc" "xlsx" "xls" "parquet" "parq"]
DefaultOutputFormat: "txt"
これまでに説明したオプションの中で、mapreduce で便利なものがいくつかあります。mapreduce 関数は、データストアに対して read を実行し、データを取得して map 関数に渡します。したがって、SelectedVariableNames、SelectedFormats、ReadSize の各オプションを使用して、mapreduce が map 関数に渡すデータのブロック サイズと型を直接構成できます。
たとえば、Distance (総飛行距離) 変数を唯一の目的の変数として選択する場合は、SelectedVariableNames を指定します。
ds.SelectedVariableNames = 'Distance';こうすると、read 関数、readall 関数、または preview 関数が ds を処理するときに常に、Distance 変数の情報のみが返されます。これを確認するには、データストア内の最初の数行をプレビューできます。これにより、mapreduce 関数が map 関数に渡すデータの形式を調べられます。
preview(ds)
ans=8×1 table
Distance
________
308
296
480
296
373
308
447
954
mapreduce が map 関数に渡すデータを "そのまま" 表示するには、read を使用します。
詳細と、使用可能なオプションの完全な要約については、データストアを参照してください。
map 関数および reduce 関数の作成
mapreduce 関数は、実行中に map 関数および reduce 関数を自動的に呼び出すため、これらの関数が適切に実行されるためには特定の要件を満たさなければなりません。
map 関数への入力は、data、info および intermKVStore です。
dataおよびinfoは、入力データストアに対してread関数を呼び出した結果です。この呼び出しは、map 関数を呼び出す前に毎回mapreduceが自動的に実行します。intermKVStoreは、map 関数がキーと値のペアを追加する必要のある中間KeyValueStoreオブジェクトの名前です。add関数およびaddmulti関数は、このオブジェクト名を使用してキーと値のペアを追加します。map 関数の呼び出しで、キーと値のペアがintermKVStoreにまったく追加されなかった場合は、mapreduceは reduce 関数を呼び出さず、結果のデータストアは空になります。
map 関数の簡単な例を次に示します。
function MeanDistMapFun(data, info, intermKVStore) distances = data.Distance(~isnan(data.Distance)); sumLenValue = [sum(distances) length(distances)]; add(intermKVStore, 'sumAndLength', sumLenValue); end
この map 関数には 3 行しかなく、いくつかの簡単な役割を果たします。最初の行は距離データのブロック内のすべての NaN 値を除外します。2 行目は、総距離とブロックのカウントで 2 要素のベクトルを作成し、3 行目はその値のベクトルをキー 'sumAndLength' とともに intermKVStore に追加します。この map 関数を ds 内のデータのブロックすべてに対して実行した後、intermKVStore オブジェクトには、距離データの各ブロックの総距離とカウントが含まれます。
この関数を現在のフォルダーに MeanDistMapFun.m として保存します。
reduce 関数への入力は、intermKey、intermValIter および outKVStore です。
intermKeyは、map 関数によって追加されるアクティブなキーです。mapreduceが reduce 関数を呼び出すたびに、中間のKeyValueStoreオブジェクトのキーから新しい一意のキーが指定されます。intermValIterは、アクティブなキーintermKeyに関連付けられたValueIteratorです。このValueIteratorオブジェクトには、アクティブなキーに関連付けられたすべての値が含まれます。hasnext関数とgetnext関数を使用して値をスクロールします。outKVStoreは、reduce 関数によってキーと値のペアを追加する必要のある最終的なKeyValueStoreオブジェクトの名前です。mapreduceは、outKVStoreから出力のキーと値のペアを取得して出力データストア (既定ではKeyValueDatastoreオブジェクト) に返します。reduce 関数の呼び出しにより、outKVStoreにキーと値のペアがまったく追加されなかった場合は、mapreduceは空のデータストアを返します。
次に、reduce 関数の簡単な例を示します。
function MeanDistReduceFun(intermKey, intermValIter, outKVStore) sumLen = [0 0]; while hasnext(intermValIter) sumLen = sumLen + getnext(intermValIter); end add(outKVStore, 'Mean', sumLen(1)/sumLen(2)); end
この reduce 関数は、intermValIter 内の距離とカウントを順にループして、各パスの後の距離とカウントの合計値を保持します。このループの後、reduce 関数は単純な除算により全体の平均飛行距離を計算して、単一のキーを outKVStore に追加します。
この関数を現在のフォルダーに MeanDistReduceFun.m として保存します。
より高度な map 関数および reduce 関数の作成の詳細については、map 関数の作成およびreduce 関数の作成を参照してください。
mapreduce の実行
データストア、map 関数および reduce 関数の準備ができたら、mapreduce を呼び出して計算できます。データ セット内の平均飛行距離を計算するには、ds、MeanDistMapFun、および MeanDistReduceFun を使用して mapreduce を呼び出します。
outds = mapreduce(ds, @MeanDistMapFun, @MeanDistReduceFun);
******************************** * MAPREDUCE PROGRESS * ******************************** Map 0% Reduce 0% Map 16% Reduce 0% Map 32% Reduce 0% Map 48% Reduce 0% Map 65% Reduce 0% Map 81% Reduce 0% Map 97% Reduce 0% Map 100% Reduce 0% Map 100% Reduce 100%
既定では、mapreduce 関数は進捗情報をコマンド ラインに表示し、現在のフォルダーにあるファイルを指す KeyValueDatastore オブジェクトを返します。これら 3 つのオプションはすべて、'OutputFolder'、'OutputType' および'Display' のName,Value のペアの引数を使用して調整できます。詳細については、mapreduceのリファレンス ページを参照してください。
結果の表示
readall 関数を使用して、出力データストアからキーと値のペアを読み取ります。
readall(outds)
ans=1×2 table
Key Value
________ ____________
{'Mean'} {[702.1630]}
参考
tabularTextDatastore | mapreduce