hyperpca
ハイパースペクトル データの主成分分析
構文
説明
Add-On Required: この機能にはが必要です。
outputDataCube = hyperpca(inputData,numComponents)numComponents と等しくなります。スペクトル次元削減を実現するには、指定した主成分の数がハイパースペクトル データ キューブ inputData 内のスペクトル バンドの数未満でなければなりません。
また、[ はハイパースペクトル データ キューブのスペクトル次元をまたがって推定された主成分係数も返します。outputDataCube,coeff] = hyperpca(___)
[ は、前の構文で説明した出力引数に加えて、主成分バンドによって保持された分散の割合を返します。outputDataCube,coeff,var] = hyperpca(___)
[___] = hyperpca(___, は名前と値の引数を使用して主成分分析 (PCA) 法および追加オプションを指定します。Name=Value)
メモ
Hyperspectral Imaging Library for Image Processing Toolbox™ は、MATLAB® Online™ および MATLAB Mobile™ によってサポートされないため、デスクトップの MATLAB が必要です。
例
ハイパースペクトル データをワークスペースに読み取ります。
hcube = imhypercube("paviaU.dat");ハイパースペクトル データ キューブの主成分バンドを計算します。抽出する主成分の数を 10 に指定します。既定では、関数は特異値分解 (SVD) 法を使用して主成分を抽出します。
reducedDataCube = hyperpca(hcube,10);
入力データ キューブの最初の 10 個のスペクトル バンドを表示します。
datacube = gather(hcube); figure montage(datacube(:,:,1:10),BorderSize=[10 10],Size=[2 5],DisplayRange=[]);

可視化のため、主成分の値を [0, 1] の範囲に入るよう再スケーリングします。データ キューブから抽出された主成分バンドをすべて表示します。
figure
rescalePC = rescale(reducedDataCube,0,1);
montage(rescalePC,BorderSize=[10 10],Size=[2 5]);
title("Principal Component Bands of Data Cube")
ハイパースペクトル データをワークスペースに読み取ります。
hcube = imhypercube("paviaU.dat");固有値分解を使用して入力データ キューブの PCA を実行します。抽出する主成分の数を 3 に指定します。主成分 (PC) バンド、係数、および保持された分散を導出します。
[outputDataCube,coeff,var] = hyperpca(hcube,3,Method="Eig");可視化のため、主成分の値を [0, 1] の範囲に入るよう再スケーリングします。データ キューブから抽出された主成分バンドをすべて表示します。
figure
rescalePC = rescale(outputDataCube,0,1);
montage(rescalePC,BorderSize=[10 10],Size=[1 3]);
title("Principal Component Bands of Data Cube")
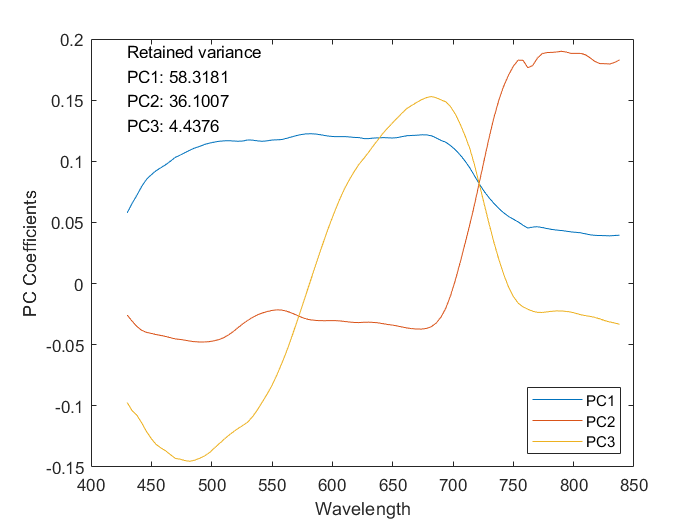
主成分係数をプロットし、それぞれの主成分によって保持された分散の割合を表示します。保持された分散値の総和は、入力ハイパースペクトル データの情報の 99% が 3 つの主成分によって取得されていることを示唆しています。
figure plot(hcube.Wavelength,coeff); legend(["PC1";"PC2";"PC3"],Location="SouthEast") text(430,0.19,"Retained variance"); text(430,0.17,"PC1: "+num2str(var(1))) text(430,0.15,"PC2: "+num2str(var(2))) text(430,0.13,"PC3: "+num2str(var(3))) xlabel("Wavelength") ylabel("PC Coefficients")
入力引数
名前と値の引数
出力引数
バージョン履歴
R2020a で導入