スナップショット アンサンブルのための周期的な学習率を使用したネットワークの学習
この例では、テスト精度の向上のために周期的な学習率スケジュールとスナップショットのアンサンブルを使用して、オブジェクトのイメージを分類するようにネットワークに学習させる方法を示します。この例では、学習率スケジュールに余弦関数を使用し、学習中にネットワークのスナップショットを取得してモデル アンサンブルを作成し、L2 ノルム正則化 (重み減衰) を学習損失に追加する方法を学習します。
この例は、カスタム周期学習率を使用し、CIFAR-10 データ セット [2] で残差ネットワーク [1] に学習させます。それぞれの反復で、ソルバーはシフトした余弦関数 [3] alpha(t) = (alpha0/2)*cos(pi*mod(t-1,T/M)/(T/M)+1) によって与えられる学習率を使用します。ここで、t は反復回数、T は学習反復の総数、alpha0 は初期学習率、M はサイクル/スナップショットの数です。この学習率スケジュールは、学習プロセスを M 個のサイクルに効果的に分割します。各サイクルは単調に減衰する大きな学習率で始まり、ネットワークにさまざまな局所的最小値を検索させます。各学習サイクルの最後に、ネットワークのスナップショットを取得 (つまり、その反復におけるモデルを保存) し、その後、すべてのスナップショット モデルの予測を平均化 (スナップショット アンサンブル [4] とも呼ばれます) して、最終的なテスト精度を向上させます。
データの準備
CIFAR-10 データ セット [2] をダウンロードします。このデータ セットには 60,000 個のイメージが格納されています。各イメージのサイズは 32 x 32 で 3 つのカラー チャネル (RGB) があります。データ セットのサイズは 175 MB です。インターネット接続の速度によっては、ダウンロード プロセスに時間がかかることがあります。
datadir = tempdir; downloadCIFARData(datadir);
CIFAR-10 学習イメージとテスト イメージを 4 次元配列として読み込みます。学習セットには 50,000 個のイメージが格納されていて、テスト セットには 10,000 個のイメージが格納されています。
[XTrain,TTrain,XTest,TTest] = loadCIFARData(datadir); classes = categories(TTrain); numClasses = numel(classes);
次のコードを使用して、ランダムにサンプリングされた学習イメージを表示できます。
figure; idx = randperm(size(XTrain,4),20); im = imtile(XTrain(:,:,:,idx),ThumbnailSize=[96,96]); imshow(im)
ネットワーク学習に使用する augmentedImageDatastore オブジェクトを作成します。学習中に、データストアは縦軸に沿って学習イメージをランダムに反転させ、水平方向および垂直方向に最大 4 ピクセルだけランダムに平行移動させます。データ拡張は、ネットワークで過適合が発生したり、学習イメージの正確な詳細が記憶されたりすることを防止するのに役立ちます。
imageSize = [32 32 3]; pixelRange = [-4 4]; imageAugmenter = imageDataAugmenter( ... RandXReflection=true, ... RandXTranslation=pixelRange, ... RandYTranslation=pixelRange); augimdsTrain = augmentedImageDatastore(imageSize,XTrain,TTrain, ... DataAugmentation=imageAugmenter);
ネットワーク アーキテクチャの定義
6 つの標準畳み込みユニット (段階ごとに 2 ユニット) があり、幅が 16 の残差ネットワーク [1] を作成します。ネットワークの深さの合計は 2*6+2 = 14 です。さらに、イメージ入力層で Mean オプションを使用して平均イメージを指定します。
netWidth = 16;
layers = [
imageInputLayer(imageSize,Mean=mean(XTrain,4))
convolution2dLayer(3,netWidth,Padding="same")
batchNormalizationLayer
reluLayer(Name="reluInp")
convolutionalUnit(netWidth,1)
additionLayer(2,Name="add11")
reluLayer(Name="relu11")
convolutionalUnit(netWidth,1)
additionLayer(2,Name="add12")
reluLayer(Name="relu12")
convolutionalUnit(2*netWidth,2)
additionLayer(2,Name="add21")
reluLayer(Name="relu21")
convolutionalUnit(2*netWidth,1)
additionLayer(2,Name="add22")
reluLayer(Name="relu22")
convolutionalUnit(4*netWidth,2)
additionLayer(2,Name="add31")
reluLayer(Name="relu31")
convolutionalUnit(4*netWidth,1)
additionLayer(2,Name="add32")
reluLayer(Name="relu32")
globalAveragePooling2dLayer
fullyConnectedLayer(numClasses)
softmaxLayer];
lgraph = layerGraph(layers);
lgraph = connectLayers(lgraph,"reluInp","add11/in2");
lgraph = connectLayers(lgraph,"relu11","add12/in2");
skip1 = [
convolution2dLayer(1,2*netWidth,Stride=2,Name="skipConv1")
batchNormalizationLayer(Name="skipBN1")];
lgraph = addLayers(lgraph,skip1);
lgraph = connectLayers(lgraph,"relu12","skipConv1");
lgraph = connectLayers(lgraph,"skipBN1","add21/in2");
lgraph = connectLayers(lgraph,"relu21","add22/in2");
skip2 = [
convolution2dLayer(1,4*netWidth,Stride=2,Name="skipConv2")
batchNormalizationLayer(Name="skipBN2")];
lgraph = addLayers(lgraph,skip2);
lgraph = connectLayers(lgraph,"relu22","skipConv2");
lgraph = connectLayers(lgraph,"skipBN2","add31/in2");
lgraph = connectLayers(lgraph,"relu31","add32/in2");ResNet アーキテクチャをプロットします。
figure plot(lgraph)
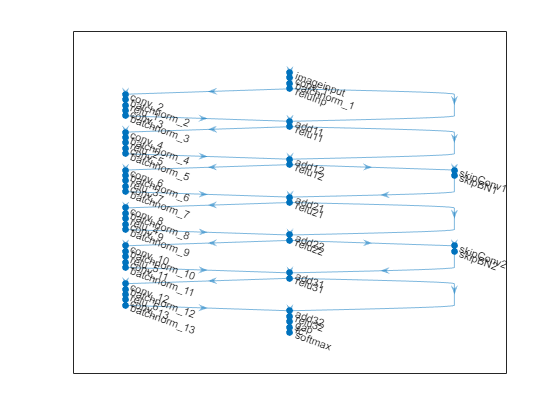
層グラフから dlnetwork オブジェクトを作成します。
net = dlnetwork(lgraph);
モデル損失関数の定義
例の最後にリストされている補助関数 modelLoss を作成します。この関数は、dlnetwork オブジェクト net、および入力データのミニバッチ X とそれに対応するラベル T を受け取り、net 内の学習可能なパラメーターについての損失と損失の勾配、および特定の反復におけるネットワークの学習不能なパラメーターの状態を返します。
学習オプションの指定
学習オプションを指定します。
ミニバッチ サイズを 64 として 200 エポック学習させます。
モーメンタムを 0.9 とし、SGDM を使用して学習させます。
重み減衰値 を使用して重みを正則化します。
numEpochs = 200; miniBatchSize = 64; momentum = 0.9; weightDecay = 1e-4;
重み減衰を適用する重みのインデックスを判定します。
idxWeights = ismember(net.Learnables.Parameter,["Weights" "Scale"]);
SGDM 最適化のパラメーターを初期化します。
velocity = [];
周期学習率に固有の学習オプションを指定します。alpha0 は初期学習率、numSnapshots はサイクル数つまり学習中に取得したスナップショットの数です。
alpha0 = 0.1;
numSnapshots = 5;
epochsPerSnapshot = numEpochs./numSnapshots;
numObservations = numel(TTrain);
iterationsPerSnapshot = ceil(numObservations./miniBatchSize)*numEpochs./numSnapshots;
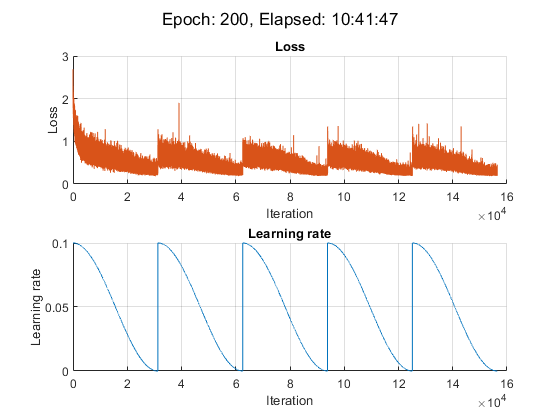
modelPrefix = "SnapshotEpoch";学習の Figure を初期化します。
[lossLine,learnRateLine] = plotLossAndLearnRate;
モデルの学習
minibatchqueueを使用し、学習中にイメージのミニバッチを処理および管理します。各ミニバッチで次を行います。
カスタム ミニバッチ前処理関数
preprocessMiniBatch(この例の最後に定義) を使用して、クラス ラベルを one-hot 符号化します。イメージ データを次元ラベル
"SSCB"(spatial、spatial、channel、batch) で形式を整えます。既定では、minibatchqueueオブジェクトは、基となる型がsingleのdlarrayオブジェクトにデータを変換します。形式をクラス ラベルに追加しないでください。GPU が利用できる場合、GPU で学習を行います。既定では、
minibatchqueueオブジェクトは、GPU が利用可能な場合、各出力をgpuArrayに変換します。GPU を使用するには、Parallel Computing Toolbox™ とサポートされている GPU デバイスが必要です。サポートされているデバイスの詳細については、GPU 計算の要件 (Parallel Computing Toolbox)を参照してください。
augimdsTrain.MiniBatchSize = miniBatchSize; mbqTrain = minibatchqueue(augimdsTrain,... MiniBatchSize=miniBatchSize,... MiniBatchFcn=@preprocessMiniBatch,... MiniBatchFormat=["SSCB",""]);
dlaccelerate を使用して、関数 modelLoss を高速化します。
accfun = dlaccelerate(@modelLoss);
カスタム学習ループを使用してモデルに学習させます。各エポックについて、データストアをシャッフルし、データのミニバッチをループ処理して、現在のエポックが epochsPerSnapshot の倍数の場合はモデル (スナップショット) を保存します。各エポックの最後に、学習の進行状況を表示します。各ミニバッチで次を行います。
dlfevalおよび高速化した関数modelLossを使用して、モデルの損失と勾配を評価します。ネットワークの学習不能なパラメーターの状態を更新します。
周期学習率スケジュールの学習率を決定します。
関数
sgdmupdateを使用してネットワーク パラメーターを更新します。各反復での損失と学習率をプロットします。
この例では、NVIDIA® TITAN RTX での学習に約 11 時間かかりました。
iteration = 0; start = tic; % Loop over epochs. for epoch = 1:numEpochs % Shuffle data. shuffle(mbqTrain); % Save snapshot model. if ~mod(epoch,epochsPerSnapshot) save(modelPrefix + epoch + ".mat","net"); end % Loop over mini-batches. while hasdata(mbqTrain) iteration = iteration + 1; % Read mini-batch of data. [X,T] = next(mbqTrain); % Evaluate the model loss and gradients using dlfeval and the % accelerated modelLoss function. [loss, gradients, state] = dlfeval(accfun,net,X,T,weightDecay,idxWeights); % Update the state of nonlearnable parameters. net.State = state; % Determine learning rate for cyclical learning rate schedule. learnRate = 0.5*alpha0*(cos((pi*mod(iteration-1,iterationsPerSnapshot)./iterationsPerSnapshot))+1); % Update the network parameters using the SGDM optimizer. [net, velocity] = sgdmupdate(net, gradients, velocity, learnRate, momentum); % Display the training progress. D = duration(0,0,toc(start),Format="hh:mm:ss"); addpoints(lossLine,iteration,double(loss)) addpoints(learnRateLine, iteration, learnRate); sgtitle("Epoch: " + epoch + ", Elapsed: " + string(D)) drawnow end end
スナップショット アンサンブルの作成とモデルのテスト
学習中に取得したネットワークの M 個のスナップショットを結合して、最終的なアンサンブルを形成し、モデルの分類精度をテストします。アンサンブル予測は、M 個の独立したモデルすべてからの全結合層の出力の平均に対応します。
CIFAR-10 データ セットで提供されるテスト データでモデルをテストします。学習データと同じ設定の minibatchqueue オブジェクトを使用して、テスト データ セットを管理します。
augimdsTest = augmentedImageDatastore(imageSize,XTest,TTest); augimdsTest.MiniBatchSize = miniBatchSize; mbqTest = minibatchqueue(augimdsTest,... MiniBatchSize=miniBatchSize,... MiniBatchFcn=@preprocessMiniBatch,... MiniBatchFormat=["SSCB",""]);
各スナップショット ネットワークの精度を評価します。この例の終わりに定義されている関数 modelPredictions を使用して、テスト データ セット内のすべてのデータを反復処理します。この関数は、モデルからの全結合層の出力、予測されたクラス、および真のクラスとの比較を返します。
modelName = cell(numSnapshots+1,1); fcOutput = zeros(numClasses,numel(TTest),numSnapshots+1); classPredictions = cell(1,numSnapshots+1); modelAccuracy = zeros(numSnapshots+1,1); for m = 1:numSnapshots modelName{m} = modelPrefix + m*epochsPerSnapshot; load(modelName{m} + ".mat"); reset(mbqTest); [fcOutputTest,classPredTest,classCorrTest] = modelPredictions(net,mbqTest,classes); fcOutput(:,:,m) = fcOutputTest; classPredictions{m} = classPredTest; modelAccuracy(m) = 100*mean(classCorrTest); disp(modelName{m} + " accuracy: " + modelAccuracy(m) + "%") end
SnapshotEpoch40 accuracy: 87.93% SnapshotEpoch80 accuracy: 89.92% SnapshotEpoch120 accuracy: 90.55% SnapshotEpoch160 accuracy: 90.67% SnapshotEpoch200 accuracy: 91.33%
アンサンブル ネットワークの出力を決定するには、各スナップショット ネットワークの全結合出力の平均を計算します。関数 onehotdecode を使用して、予測されたクラスをアンサンブル ネットワークから見つけます。真のクラスと比較し、アンサンブルの精度を評価します。
fcOutput(:,:,end) = mean(fcOutput(:,:,1:end-1),3);
classPredictions{end} = onehotdecode(softmax(fcOutput(:,:,end)),classes,1,"categorical");
classCorrEnsemble = classPredictions{end} == TTest';
modelAccuracy(end) = 100*mean(classCorrEnsemble);
modelName{end} = "Ensemble model";
disp("Ensemble accuracy: " + modelAccuracy(end) + "%")Ensemble accuracy: 91.74%
精度のプロット
テスト データセットに対するすべてのスナップショット モデルとアンサンブル モデルの精度をプロットします。
figure;bar(modelAccuracy); ylabel("Accuracy (%)"); xticklabels(modelName) xtickangle(45) title("Model accuracy")

補助関数
モデル損失関数
関数 modelLoss は、dlnetwork オブジェクト net、入力データのミニバッチ X、ラベル T、重み減衰のパラメーター、および減衰させる重みのインデックスを受け取ります。この関数は、損失、勾配、および学習不能なパラメーターの状態を返します。勾配を自動的に計算するには、関数 dlgradient を使用します。
function [loss,gradients,state] = modelLoss(net,X,T,weightDecay,idxWeights) [Y,state] = forward(net,X); loss = crossentropy(Y, T); % L2-regularization (weight decay) allParams = net.Learnables(idxWeights,:).Value; L = dlupdate(@(x) sum(x.^2,"all"),allParams); L = sum(cat(1,L{:})); loss = loss + weightDecay*0.5*L; gradients = dlgradient(loss,net.Learnables); end
モデル予測関数
関数 modelPredictions は、dlnetwork オブジェクト net と入力データの minibatchqueue オブジェクト mbq を入力として受け取り、minibatchqueue に含まれるすべてのデータを反復処理することによってモデル予測を計算します。この関数は、関数 onehotdecode を使用して、スコアが最も高い予測されたクラスを見つけ、その予測を真のクラスと比較します。この関数は、ネットワーク出力、クラス予測、および予測の正誤を表す 0 と 1 のベクトルを返します。
function [rawPredictions,classPredictions,classCorr] = modelPredictions(net,mbq,classes) rawPredictions = []; classPredictions = []; classCorr = []; while hasdata(mbq) [X,T] = next(mbq); % Make predictions YPred = predict(net,X); rawPredictions = [rawPredictions extractdata(gather(YPred))]; % Convert network output to probabilities and determine predicted % classes YPred = softmax(YPred); YPredBatch = onehotdecode(YPred,classes,1); classPredictions = [classPredictions YPredBatch]; % Compare predicted and true classes T = onehotdecode(T,classes,1); classCorr = [classCorr YPredBatch == T]; end end
損失と学習率をプロットする関数
plotLossAndLearnRate 関数は、学習中の各反復での損失と学習率を表示するためにプロットを初期化します。
function [lossLine, learnRateLine] = plotLossAndLearnRate figure subplot(2,1,1); lossLine = animatedline(Color=[0.85 0.325 0.098]); title("Loss"); xlabel("Iteration") ylabel("Loss") grid on subplot(2,1,2); learnRateLine = animatedline(Color=[0 0.447 0.741]); title("Learning rate"); xlabel("Iteration") ylabel("Learning rate") grid on end
畳み込みユニット関数
関数 convolutionalUnit(numF,stride) は 2 つの畳み込み層と対応するバッチ正規化層および ReLU 層のある層の配列を作成します。numF は畳み込みフィルターの数で、stride は最初の畳み込み層のストライドです。
function layers = convolutionalUnit(numF,stride) layers = [ convolution2dLayer(3,numF,Padding="same",Stride=stride) batchNormalizationLayer reluLayer convolution2dLayer(3,numF,Padding="same") batchNormalizationLayer]; end
データ前処理関数
関数 preprocessMiniBatch は、次の手順でデータを前処理します。
入力 cell 配列からイメージ データを抽出して数値配列に連結します。4 番目の次元でイメージ データを連結することにより、3 番目の次元が各イメージに追加されます。この次元は、シングルトン チャネル次元として使用されます。
入力 cell 配列からラベル データを抽出し、2 番目の次元に沿って categorical 配列に連結させます。
カテゴリカル ラベルを数値配列に one-hot 符号化します。最初の次元への符号化は、ネットワーク出力の形状と一致する符号化された配列を生成します。
function [X,T] = preprocessMiniBatch(XCell,TCell) % Extract image data from cell and concatenate X = cat(4,XCell{:}); % Extract label data from cell and concatenate T = cat(2,TCell{:}); % One-hot encode labels T = onehotencode(T,1); end
参考文献
[1] He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep residual learning for image recognition." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770-778. 2016.
[2] Krizhevsky, Alex. "Learning multiple layers of features from tiny images." (2009). https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
[3] Loshchilov, Ilya, and Frank Hutter. "Sgdr: Stochastic gradient descent with warm restarts." (2016). arXiv preprint arXiv:1608.03983.
[4] Huang, Gao, Yixuan Li, Geoff Pleiss, Zhuang Liu, John E. Hopcroft, and Kilian Q. Weinberger. "Snapshot ensembles: Train 1, get m for free." (2017). arXiv preprint arXiv:1704.00109.
参考
trainnet | trainingOptions | dlnetwork | dlarray | sgdmupdate | dlfeval | dlgradient | sigmoid | minibatchqueue | onehotencode | onehotdecode