条件付き敵対的生成ネットワーク (CGAN) の学習
この例では、条件付き敵対的生成ネットワークに学習させてイメージを生成する方法を説明します。
敵対的生成ネットワーク (GAN) は深層学習ネットワークの一種で、入力された学習データと類似の特性をもつデータを生成できます。
GAN は一緒に学習を行う 2 つのネットワークで構成されています。
ジェネレーター。ランダムな値で構成されるベクトルを入力として与えられ、学習データと同じ構造のデータを生成します。
ディスクリミネーター。学習データとジェネレーターにより生成されたデータの両方の観測値を含むデータのバッチを与えられ、その観測値が
"real"か"generated"かの分類を試みます。

"条件付き" 敵対的生成ネットワーク (CGAN) は GAN の一種で、こちらも学習プロセス中にラベルを利用します。
ジェネレーター。ラベルと乱数の配列を入力として与えられ、同じラベルに対応する学習データの観測値と同じ構造のデータを生成します。
ディスクリミネーター。学習データとジェネレーターにより生成されたデータの両方の観測値を含むラベル付きデータのバッチを与えられ、その観測値が
"real"か"generated"かの分類を試みます。
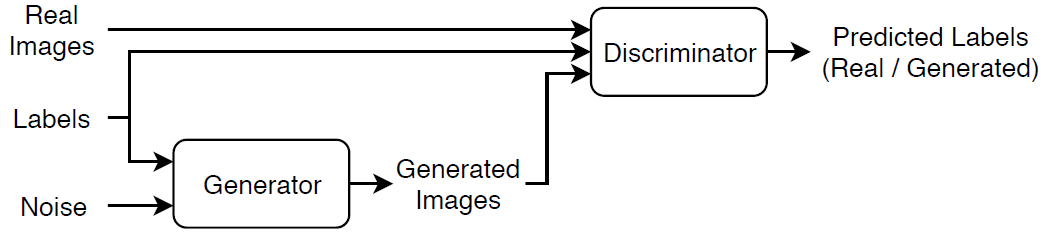
条件付き GAN に学習させる場合は、両方のネットワークの学習を同時に行うことで両者のパフォーマンスを最大化します。
ジェネレーターに学習させて、ディスクリミネーターを "騙す" データを生成。
ディスクリミネーターに学習させて、実データと生成データを区別。
ジェネレーターのパフォーマンスを最大化するには、生成されたラベル付きデータが与えられたときのディスクリミネーターの損失を最大化します。つまり、ジェネレーターの目的はディスクリミネーターが "real" と分類するようなラベル付きデータを生成することです。
ディスクリミネーターのパフォーマンスを最大化するには、ラベル付きの実データと生成データ両方のバッチが与えられたときのディスクリミネーターの損失を最小化します。つまり、ディスクリミネーターの目的はジェネレーターに "騙されない" ことです。
この方法の理想的な結果は、入力ラベルごとにいかにも本物らしいデータをジェネレーターに生成させ、ラベルごとの学習データの特性を表す強い特徴表現をディスクリミネーターに学習させることです。
学習データの読み込み
Flowers データ セット [1] をダウンロードし、解凍します。
url = "http://download.tensorflow.org/example_images/flower_photos.tgz"; downloadFolder = tempdir; filename = fullfile(downloadFolder,"flower_dataset.tgz"); imageFolder = fullfile(downloadFolder,"flower_photos"); if ~exist(imageFolder,"dir") disp("Downloading Flowers data set (218 MB)...") websave(filename,url); untar(filename,downloadFolder) end
花の写真のイメージ データストアを作成します。
datasetFolder = fullfile(imageFolder);
imds = imageDatastore(datasetFolder,IncludeSubfolders=true,LabelSource="foldernames");クラス数を表示します。
classes = categories(imds.Labels); numClasses = numel(classes)
numClasses = 5
データを拡張して水平方向にランダムに反転させ、イメージのサイズを 64 x 64 に変更します。
augmenter = imageDataAugmenter(RandXReflection=true); augimds = augmentedImageDatastore([64 64],imds,DataAugmentation=augmenter);
ジェネレーター ネットワークの定義
サイズ 100 のランダム ベクトルと対応するラベルを与えられてイメージを生成する、次の 2 入力ネットワークを定義します。
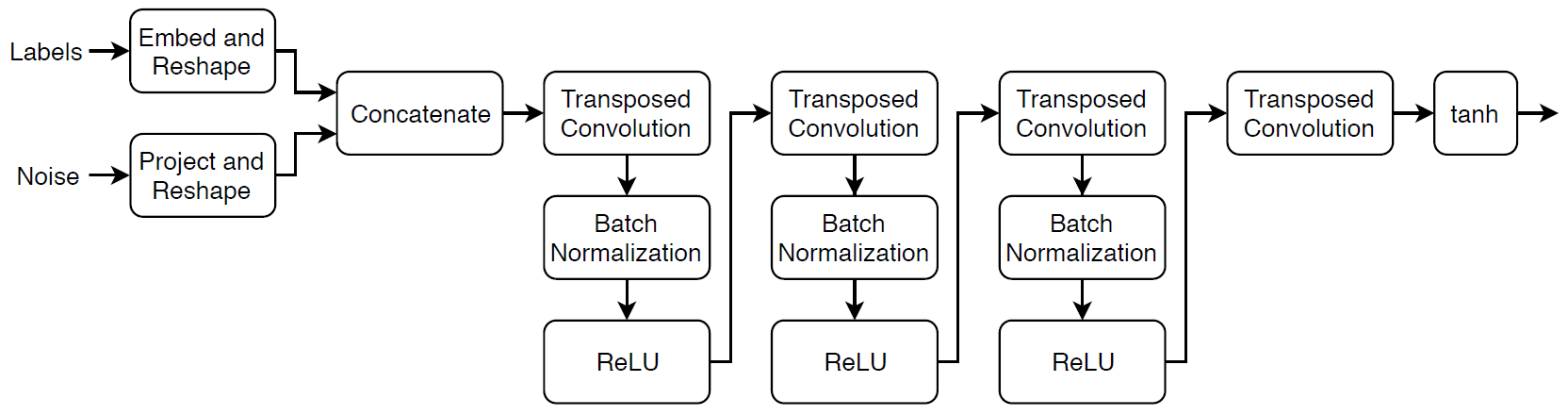
このネットワークは、次を行います。
全結合層とそれに続く形状変更操作を使用して、サイズ 100 のランダム ベクトルを 4×4×1024 の配列に変換します。
カテゴリカル ラベルを埋め込みベクトルに変換して 4 行 4 列の配列に形状を変更します。
2 つの入力から得られた結果のイメージをチャネルの次元に沿って連結します。出力は 4 x 4 x 1025 の配列です。
バッチ正規化と ReLU 層を用いた一連の転置畳み込み層を使用して、結果の配列を 64 x 64 x 3 の配列にアップスケール。
このネットワーク アーキテクチャを定義し、次のネットワーク プロパティを指定します。
カテゴリカル入力では、50 の埋め込み次元を使用します。
転置畳み込み層では、各層のフィルター数を減らして 5 x 5 のフィルターを指定し、ストライドを 2 に、出力のトリミングを
"same"に指定します。最後の転置畳み込み層では、生成されたイメージの 3 つの RGB チャネルに対応する 3 つの 5 x 5 のフィルターを指定します。
ネットワークの最後に、tanh 層を追加。
ノイズ入力を投影して形状変更するには、全結合層に続けて、空間次元とチャネル次元で演算する形状変更層を使用します。カテゴリカル ラベルを埋め込むには、埋め込み層を使用します。
numLatentInputs = 100;
embeddingDimension = 50;
numFilters = 64;
filterSize = 5;
projectionSize = [4 4 1024];
netG = dlnetwork;
layers = [
featureInputLayer(numLatentInputs)
fullyConnectedLayer(prod(projectionSize))
reshapeLayer(projectionSize,OperationDimension="spatial-channel")
concatenationLayer(3,2,Name="cat");
transposedConv2dLayer(filterSize,4*numFilters)
batchNormalizationLayer
reluLayer
transposedConv2dLayer(filterSize,2*numFilters,Stride=2,Cropping="same")
batchNormalizationLayer
reluLayer
transposedConv2dLayer(filterSize,numFilters,Stride=2,Cropping="same")
batchNormalizationLayer
reluLayer
transposedConv2dLayer(filterSize,3,Stride=2,Cropping="same")
tanhLayer];
netG = addLayers(netG,layers);
layers = [
featureInputLayer(1)
embeddingLayer(embeddingDimension,numClasses)
fullyConnectedLayer(prod(projectionSize(1:2)))
reshapeLayer([projectionSize(1:2) 1],OperationDimension="spatial-channel",Name="emb_reshape")];
netG = addLayers(netG,layers);
netG = connectLayers(netG,"emb_reshape","cat/in2");カスタム学習ループを使用してネットワークに学習させるために、dlnetwork オブジェクトを初期化します。
netG = initialize(netG)
netG =
dlnetwork with properties:
Layers: [19×1 nnet.cnn.layer.Layer]
Connections: [18×2 table]
Learnables: [19×3 table]
State: [6×3 table]
InputNames: {'input' 'input_1'}
OutputNames: {'layer'}
Initialized: 1
View summary with summary.
ディスクリミネーター ネットワークの定義
イメージのセットと対応するラベルを与えられて 64 x 64 の実イメージと生成イメージを分類する、次の 2 入力ネットワークを定義します。
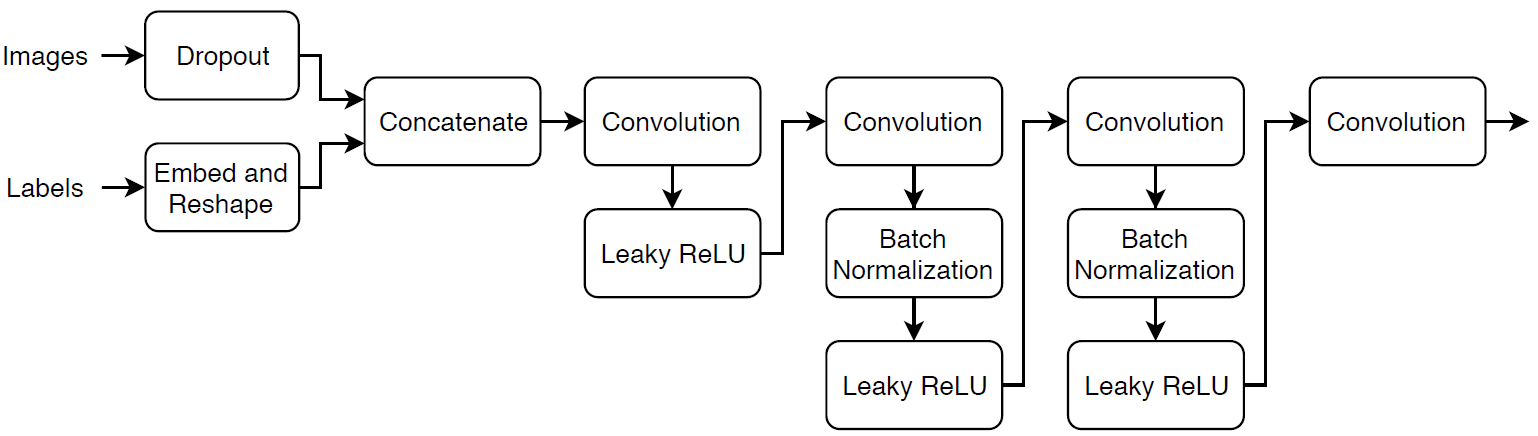
64 x 64 x 1 のイメージと対応するラベルを入力として受け取り、バッチ正規化層と leaky ReLU 層をもつ一連の畳み込み層を使用してスカラーの予測スコアを出力するネットワークを作成します。ドロップアウトを使用して、入力イメージにノイズを追加します。
ドロップアウト層で、ドロップアウトの確率を 0.75 に設定。
畳み込み層で、5 x 5 のフィルターを指定し、各層でフィルター数を増やす。また、ストライドを 2 に指定し、各エッジでの出力のパディングを指定します。
leaky ReLU 層で、スケールを 0.2 に設定。
最後の層で、4 x 4 のフィルターをもつ畳み込み層を設定します。
dropoutProb = 0.75;
numFilters = 64;
scale = 0.2;
inputSize = [64 64 3];
filterSize = 5;
netD = dlnetwork;
layers = [
imageInputLayer(inputSize,Normalization="none")
dropoutLayer(dropoutProb)
concatenationLayer(3,2,Name="cat")
convolution2dLayer(filterSize,numFilters,Stride=2,Padding="same")
leakyReluLayer(scale)
convolution2dLayer(filterSize,2*numFilters,Stride=2,Padding="same")
batchNormalizationLayer
leakyReluLayer(scale)
convolution2dLayer(filterSize,4*numFilters,Stride=2,Padding="same")
batchNormalizationLayer
leakyReluLayer(scale)
convolution2dLayer(filterSize,8*numFilters,Stride=2,Padding="same")
batchNormalizationLayer
leakyReluLayer(scale)
convolution2dLayer(4,1)];
netD = addLayers(netD,layers);
layers = [
featureInputLayer(1)
embeddingLayer(embeddingDimension,numClasses)
fullyConnectedLayer(prod(inputSize(1:2)))
reshapeLayer([inputSize(1:2) 1],OperationDimension="spatial-channel",Name="emb_reshape")];
netD = addLayers(netD,layers);
netD = connectLayers(netD,"emb_reshape","cat/in2");カスタム学習ループを使用してネットワークに学習させ、自動微分を有効にするために、dlnetwork オブジェクトを初期化します。
netD = initialize(netD)
netD =
dlnetwork with properties:
Layers: [19×1 nnet.cnn.layer.Layer]
Connections: [18×2 table]
Learnables: [19×3 table]
State: [6×3 table]
InputNames: {'imageinput' 'input'}
OutputNames: {'conv_5'}
Initialized: 1
View summary with summary.
モデル損失関数の定義
この例のモデル損失関数の節にリストされている関数 modelLoss を作成します。この関数は、ジェネレーターおよびディスクリミネーターのネットワーク、入力データのミニバッチ、および乱数値の配列を入力として受け取り、ネットワーク内の学習可能なパラメーターについての損失の勾配と、生成されたイメージの配列を返します。
学習オプションの指定
ミニバッチ サイズを 128 として 500 エポック学習させます。
numEpochs = 500; miniBatchSize = 128;
Adam 最適化のオプションを指定します。両方のネットワークで次を使用します。
学習率 0.0002
勾配の減衰係数 0.5
2 乗勾配の減衰係数 0.999
learnRate = 0.0002; gradientDecayFactor = 0.5; squaredGradientDecayFactor = 0.999;
100 回の反復ごとに学習の進行状況プロットを更新します。
validationFrequency = 100;
実イメージと生成イメージとを区別するディスクリミネーターの学習速度が速すぎる場合、ジェネレーターの学習に失敗する可能性があります。ディスクリミネーターとジェネレーターの学習バランスを改善するために、実イメージの一部のラベルをランダムに反転します。反転係数を 0.5 に指定します。
flipFactor = 0.5;
モデルの学習
カスタム学習ループを使用してモデルに学習させます。学習データ全体をループ処理し、各反復でネットワーク パラメーターを更新します。学習の進行状況を監視するには、ホールドアウトされたランダムな値の配列をジェネレーターに入力して得られた生成イメージのバッチと、ネットワーク スコアのプロットを表示します。
minibatchqueueを使用して、学習中にイメージのミニバッチを処理および管理します。各ミニバッチで次を行います。
カスタム ミニバッチ前処理関数
preprocessMiniBatch(この例の最後に定義) を使用して、イメージを範囲[-1,1]で再スケーリングします。観測値が 128 個未満の部分的なミニバッチは破棄します。
イメージ データを次元ラベル
"SSCB"(spatial、spatial、channel、batch) で形式を整えます。ラベル データを、次元ラベル
"BC"(batch、channel) で形式を整えます。GPU が利用できる場合、GPU で学習を行います。
minibatchqueueのOutputEnvironmentオプションが"auto"のとき、GPU が利用可能であれば、minibatchqueueは各出力をgpuArrayに変換します。GPU を使用するには、Parallel Computing Toolbox™ とサポートされている GPU デバイスが必要です。サポートされているデバイスの詳細については、GPU 計算の要件 (Parallel Computing Toolbox)を参照してください。
minibatchqueue オブジェクトは、既定では、基となる型が single の dlarray オブジェクトにデータを変換します。
augimds.MiniBatchSize = miniBatchSize; executionEnvironment = "auto"; mbq = minibatchqueue(augimds, ... MiniBatchSize=miniBatchSize, ... PartialMiniBatch="discard", ... MiniBatchFcn=@preprocessData, ... MiniBatchFormat=["SSCB" "BC"], ... OutputEnvironment=executionEnvironment);
Adam オプティマイザーのパラメーターを初期化します。
velocityD = []; trailingAvgG = []; trailingAvgSqG = []; trailingAvgD = []; trailingAvgSqD = [];
学習の進行状況を監視するには、25 個のランダム ベクトルを含むホールドアウトされたバッチと、対応する 1 から 5 のラベル (クラスに対応) を 5 回繰り返した集合を作成します。
numValidationImagesPerClass = 5;
ZValidation = randn(numLatentInputs,numValidationImagesPerClass*numClasses,"single");
TValidation = single(repmat(1:numClasses,[1 numValidationImagesPerClass]));データを dlarray オブジェクトに変換し、次元ラベル "CB" (channel、batch) を指定します。
ZValidation = dlarray(ZValidation,"CB"); TValidation = dlarray(TValidation,"CB");
GPU での学習用に、データを gpuArray オブジェクトに変換します。
if (executionEnvironment == "auto" && canUseGPU) || executionEnvironment == "gpu" ZValidation = gpuArray(ZValidation); TValidation = gpuArray(TValidation); end
モデルの損失関数を高速化します。
accfun = dlaccelerate(@modelLoss);
ジェネレーターとディスクリミネーターのスコアを追跡するには、trainingProgressMonitorオブジェクトを使用します。モニター用に合計反復回数を計算します。
numObservationsTrain = numel(imds.Files); numIterationsPerEpoch = floor(numObservationsTrain / miniBatchSize); numIterations = numEpochs * numIterationsPerEpoch;
TrainingProgressMonitor オブジェクトを初期化します。監視オブジェクトを作成するとタイマーが開始されるため、学習ループに近いところでオブジェクトを作成するようにしてください。
monitor = trainingProgressMonitor( ... Metrics=["GeneratorScore","DiscriminatorScore"], ... Info=["Epoch","Iteration"], ... XLabel="Iteration"); groupSubPlot(monitor,Score=["GeneratorScore","DiscriminatorScore"])
条件付き GAN に学習させます。各エポックについて、データをシャッフルしてデータのミニバッチをループで回します。
各ミニバッチで次を行います。
TrainingProgressMonitorオブジェクトのStopプロパティがtrueのときに停止します。[停止] ボタンをクリックしたときにStopプロパティがtrueに変更します。反転させるラベルを選択します。
dlfevalと高速化されたmodelLoss関数を使用して、学習可能なパラメーターについての損失の勾配、ジェネレーターの状態、およびネットワークのスコアを評価します。関数
adamupdateを使用してネットワーク パラメーターを更新します。2 つのネットワークのスコアをプロットします。
validationFrequency回の反復が終わるごとに、ホールドアウトされた固定ジェネレーター入力の生成イメージのバッチを表示します。
学習を行うのに時間がかかる場合があります。
epoch = 0; iteration = 0; % Loop over epochs. while epoch < numEpochs && ~monitor.Stop epoch = epoch + 1; % Reset and shuffle data. shuffle(mbq); % Loop over mini-batches. while hasdata(mbq) && ~monitor.Stop iteration = iteration + 1; % Read mini-batch of data. [X,T] = next(mbq); % Generate latent inputs for the generator network. Convert to % dlarray and specify the dimension labels "CB" (channel, batch). % If training on a GPU, then convert latent inputs to gpuArray. Z = randn(numLatentInputs,miniBatchSize,"single"); Z = dlarray(Z,"CB"); if (executionEnvironment == "auto" && canUseGPU) || executionEnvironment == "gpu" Z = gpuArray(Z); end % Flip labels. numObservations = size(X,4); idxFlip = randperm(numObservations,floor(flipFactor * numObservations)); idxFlip = dlarray(idxFlip); % Evaluate the gradients of the loss with respect to the learnable % parameters, the generator state, and the network scores using % dlfeval and the modelLoss function. [~,~,gradientsG,gradientsD,stateG,scoreG,scoreD] = ... dlfeval(accfun,netG,netD,X,T,Z,idxFlip); netG.State = stateG; % Update the discriminator network parameters. [netD,trailingAvgD,trailingAvgSqD] = adamupdate(netD, gradientsD, ... trailingAvgD, trailingAvgSqD, iteration, ... learnRate, gradientDecayFactor, squaredGradientDecayFactor); % Update the generator network parameters. [netG,trailingAvgG,trailingAvgSqG] = ... adamupdate(netG, gradientsG, ... trailingAvgG, trailingAvgSqG, iteration, ... learnRate, gradientDecayFactor, squaredGradientDecayFactor); % Every validationFrequency iterations, display batch of generated images using the % held-out generator input. if mod(iteration,validationFrequency) == 0 || iteration == 1 % Generate images using the held-out generator input. XGeneratedValidation = predict(netG,ZValidation,TValidation); % Tile and rescale the images in the range [0 1]. I = imtile(extractdata(XGeneratedValidation), ... GridSize=[numValidationImagesPerClass numClasses]); I = rescale(I); % Display the images. image(I) xticklabels([]); yticklabels([]); title("Generated Images"); end % Update the training progress monitor. recordMetrics(monitor,iteration, ... GeneratorScore=scoreG, ... DiscriminatorScore=scoreD); updateInfo(monitor,Epoch=epoch,Iteration=iteration); monitor.Progress = 100*iteration/numIterations; end end

ここでは、ディスクリミネーターは生成イメージの中から実イメージを識別する強い特徴表現を学習しました。次に、ジェネレーターは、学習データと同様のイメージを生成できるように、同様に強い特徴表現を学習しました。各列は 1 つのクラスに対応します。
学習プロットは、ジェネレーターおよびディスクリミネーターのネットワークのスコアを示しています。ネットワークのスコアを解釈する方法の詳細については、GAN の学習過程の監視と一般的な故障モードの識別を参照してください。
新しいイメージの生成
特定のクラスの新しいイメージを生成するには、ジェネレーターに対して関数 predict を使用し、dlarray オブジェクトを指定します。このオブジェクトには、ランダム ベクトルのバッチと、目的のクラスに対応するラベルの配列が含まれています。データを dlarray オブジェクトに変換し、次元ラベル "CB" (channel、batch) を指定します。GPU での予測のために、データを gpuArray オブジェクトに変換します。イメージを並べて表示するには関数 imtile を使用し、関数 rescale を使ってイメージを再スケーリングします。
1 番目のクラスに対応する、乱数値から成る 36 ベクトルの配列を作成します。
numObservationsNew = 36;
idxClass = 1;
ZNew = randn(numLatentInputs,numObservationsNew,"single");
TNew = repmat(single(idxClass),[1 numObservationsNew]);データを次元ラベル "SSCB" (spatial、spatial、channel、batch) 付きの dlarray オブジェクトに変換します。
ZNew = dlarray(ZNew,"CB"); TNew = dlarray(TNew,"CB");
GPU を使用してイメージを生成するには、データを gpuArray オブジェクトにも変換します。
if (executionEnvironment == "auto" && canUseGPU) || executionEnvironment == "gpu" ZNew = gpuArray(ZNew); TNew = gpuArray(TNew); end
ジェネレーター ネットワークに対して関数 predict を使用し、イメージを生成します。
XGeneratedNew = predict(netG,ZNew,TNew);
生成されたイメージをプロットに表示します。
figure
I = imtile(extractdata(XGeneratedNew));
I = rescale(I);
imshow(I)
title("Class: " + classes(idxClass))
ここで、ジェネレーター ネットワークは指定のクラスで条件付けされたイメージを生成します。
モデル損失関数
関数 modelLoss は、ジェネレーターおよびディスクリミネーターの dlnetwork オブジェクト netG および netD、入力データのミニバッチ X、対応するラベル T、および乱数値の配列 Z を入力として受け取り、ネットワーク内の学習可能なパラメーターについての損失の勾配、ジェネレーターの状態、およびネットワークのスコアを返します。
実イメージと生成イメージとを区別するディスクリミネーターの学習速度が速すぎる場合、ジェネレーターの学習に失敗する可能性があります。ディスクリミネーターとジェネレーターの学習バランスを改善するために、実イメージの一部のラベルをランダムに反転します。
function [lossG,lossD,gradientsG,gradientsD,stateG,scoreG,scoreD] = ... modelLoss(netG,netD,X,T,Z,idxFlip) % Calculate the predictions for real data with the discriminator network. YReal = forward(netD,X,T); % Calculate the predictions for generated data with the discriminator network. [XGenerated,stateG] = forward(netG,Z,T); YGenerated = forward(netD,XGenerated,T); % Calculate probabilities. probGenerated = sigmoid(YGenerated); probReal = sigmoid(YReal); % Calculate the generator and discriminator scores. scoreG = mean(probGenerated); scoreD = (mean(probReal) + mean(1-probGenerated)) / 2; % Flip labels. probReal(:,:,:,idxFlip) = 1 - probReal(:,:,:,idxFlip); % Calculate the GAN loss. [lossG, lossD] = ganLoss(probReal,probGenerated); % For each network, calculate the gradients with respect to the loss. gradientsG = dlgradient(lossG,netG.Learnables,RetainData=true); gradientsD = dlgradient(lossD,netD.Learnables); end
GAN の損失関数
ジェネレーターの目的はディスクリミネーターが "real" と分類するようなデータを生成することです。ジェネレーターが生成したイメージをディスクリミネーターが実データとして分類する確率を最大化するには、負の対数尤度関数を最小化します。
ディスクリミネーターの出力 が与えられた場合、次のようになります。
は、入力イメージがクラス
"real"に属する確率です。は、入力イメージがクラス
"generated"に属する確率です。
シグモイド演算 は関数 modelLoss で行われる点に注意してください。ジェネレーターの損失関数は次の式で表されます。
ここで、 は生成イメージに対するディスクリミネーターの出力確率を表しています。
ディスクリミネーターの目的はジェネレーターに "騙されない" ことです。ディスクリミネーターが実イメージと生成イメージを正しく区別する確率を最大化するには、対応する負の対数尤度関数の和を最小化します。ディスクリミネーターの損失関数は次の式で表されます。
ここで、 は実イメージに対するディスクリミネーターの出力確率を表しています。
function [lossG, lossD] = ganLoss(scoresReal,scoresGenerated) % Calculate losses for the discriminator network. lossGenerated = -mean(log(1 - scoresGenerated)); lossReal = -mean(log(scoresReal)); % Combine the losses for the discriminator network. lossD = lossReal + lossGenerated; % Calculate the loss for the generator network. lossG = -mean(log(scoresGenerated)); end
ミニバッチ前処理関数
関数 preprocessMiniBatch は、次の手順でデータを前処理します。
入力 cell 配列からイメージとラベルのデータを抽出し、それらを数値配列に連結します。
イメージの範囲が
[-1,1]となるように再スケーリングします。
function [X,T] = preprocessData(XCell,TCell) % Extract image data from cell and concatenate X = cat(4,XCell{:}); % Extract label data from cell and concatenate T = cat(1,TCell{:}); % Rescale the images in the range [-1 1]. X = rescale(X,-1,1,InputMin=0,InputMax=255); end
参考文献
The TensorFlow Team.Flowers http://download.tensorflow.org/example_images/flower_photos.tgz
参考
dlnetwork | forward | predict | dlarray | dlgradient | dlfeval | adamupdate