強化学習エージェントを使用した二足歩行ロボットの学習
この例では、深層決定論的方策勾配 (DDPG) エージェントと双生遅延深層決定論的方策勾配 (TD3) エージェントのいずれかを使用して、二足歩行ロボットに歩行を学習させる方法を説明します。この例ではそれらの学習済みエージェントの性能の比較も行います。この例で使用するロボットは、Simscape™ Multibody™ でモデル化されています。これらのエージェントの詳細については、深層決定論的方策勾配 (DDPG) エージェントおよび双生遅延深層決定論的 (TD3) 方策勾配エージェントを参照してください。
この例では比較のために、同じモデル パラメーターをもつ二足歩行ロボット環境上で両方のエージェントに学習させます。この例では、次の設定が同じになるようにエージェントを構成します。
二足歩行ロボットの初期条件の決定手法。
[1] からヒントを得た、アクターとクリティックのネットワーク構造。
アクター オブジェクトとクリティック オブジェクトのオプション。
学習オプション (サンプル時間、割引係数、ミニバッチ サイズ、経験バッファー長、探査ノイズ)。
再現性を高めるための乱数シード発生器の固定
サンプル コードには、いくつかの段階で乱数の計算が含まれる場合があります。サンプル コード内の複数のセクションの先頭にある乱数ストリームを固定すると、実行するたびにセクション内の乱数シーケンスが維持されるため、結果が再現される可能性が高くなります。詳細については、Results Reproducibilityを参照してください。
シード 0 で乱数ストリームを固定し、メルセンヌ・ツイスター乱数アルゴリズムを使用します。乱数生成に使用されるシード制御の詳細については、rngを参照してください。
previousRngState = rng(0,"twister");出力 previousRngState は、ストリームの前の状態に関する情報が格納された構造体です。例の最後で、状態を復元します。
二足歩行ロボット モデル
この例では、二足歩行ロボットを強化学習の環境として使用します。学習の目標は、最小限の制御量を使用して、ロボットを直進歩行させることです。
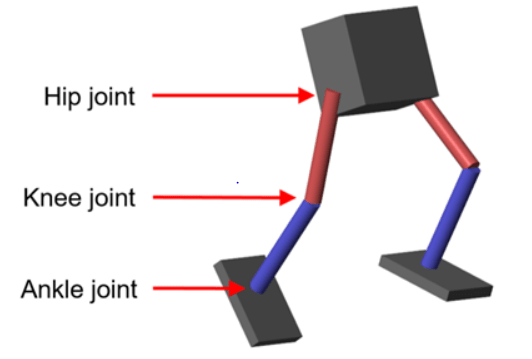
例のフォルダーに用意されている robotParametersRL スクリプトを使用し、モデルのパラメーターを MATLAB® ワークスペースに読み込みます。
robotParametersRL
Simulink® モデルを開きます。
mdl = "rlWalkingBipedRobot";
open_system(mdl)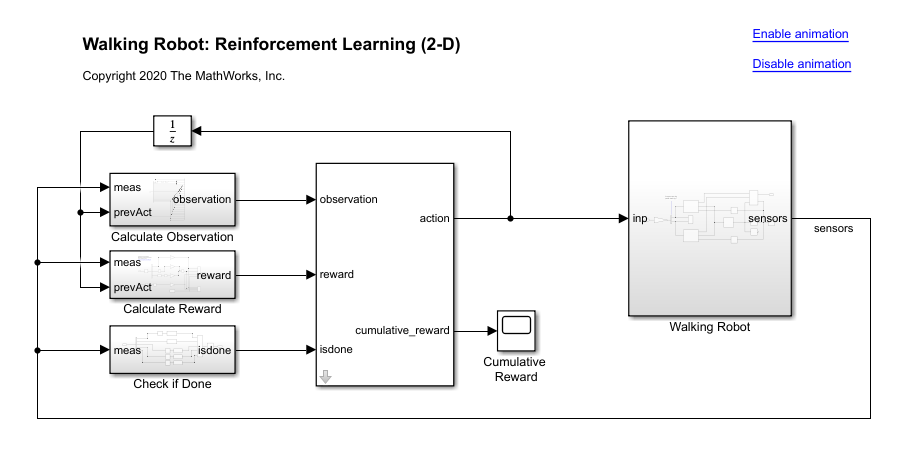
ロボットは Simscape™ Multibody™ を使用してモデル化されています。

このモデルでは、次のようにします。
中立の 0 rad の位置では、両脚はまっすぐで足は平らになっているものとする。
足の接触はSpatial Contact Force (Simscape Multibody)ブロックを使用してモデル化する。
エージェントは、-3 ~ 3 N·m のトルク信号を与えることで、ロボットの両脚の 3 つの独立した関節 (足関節、膝関節、および股関節) を制御できるものとする。実際に計算されたアクション信号は、-1 ~ 1 の範囲で正規化する。
この環境は、以下に示す 29 個の観測値をエージェントに提供します。
胴体重心の Y 方向 (横方向) および Z 方向 (垂直方向) の平行移動。Z 方向の平行移動は、他の観測値と同様の範囲で正規化。
X 方向 (進行方向)、Y 方向 (横方向)、および Z 方向 (垂直方向) の平行移動速度。
胴体のヨー角、ピッチ角、ロール角。
胴体のヨー角速度、ピッチ角速度、ロール角速度。
両脚の 3 つの関節 (足、膝、股関節) の角度位置と角速度。
前のタイム ステップからのアクション値。
エピソードは、次のいずれかの条件が発生したときに終了します。
ロボットの胴体重心が、Z 方向に 0.1 m 未満になる (ロボットが落下) か、Y のいずれかの方向に 1 m を超えている (ロボットが過度に横に移動)。
ロール角、ピッチ角、ヨー角のいずれかの絶対値が 0.7854 rad を超えている。
各タイム ステップで与えられる以下の報酬関数 は、[2] からヒントを得ています。
ここで、以下となります。
は、X 方向 (目標に向かう方向) におけるロボットの平行移動速度。
は、目標の直線軌跡からのロボットの横方向の平行移動変位。
は、ロボットの重心の正規化された垂直方向の平行移動変位。
は、前のタイム ステップにおける関節 "i" のトルク。
は、環境のサンプル時間。
は、環境の最終シミュレーション時間。
この報酬関数は、進行方向の正の速度に対して正の報酬を与えることで、エージェントに前進するよう推奨します。また、この関数は、タイム ステップごとに一定の報酬 () を与えることで、エピソードの終了を回避するようエージェントに推奨します。報酬関数に含まれるその他の項は、横方向および垂直方向の平行移動量の著しい変化に対するペナルティ、および過剰な制御操作に対するペナルティです。
環境オブジェクトの作成
観測値の仕様を作成します。
numObs = 29;
obsInfo = rlNumericSpec([numObs 1]);
obsInfo.Name = "observations";アクションの仕様を作成します。
numAct = 6;
actInfo = rlNumericSpec([numAct 1],LowerLimit=-1,UpperLimit=1);
actInfo.Name = "foot_torque";歩行ロボット モデルの環境オブジェクトを作成します。
blk = mdl + "/RL Agent";環境のリセット関数として補助関数 walkerResetFcn を指定します。詳細については、Reset Function for Simulink Environmentsを参照してください。
env = rlSimulinkEnv(mdl,blk,obsInfo,actInfo); env.ResetFcn = @(in) walkerResetFcn(in, ... upper_leg_length/100, ... lower_leg_length/100, ... h/100);
学習用のエージェントの選択と作成
エージェントを作成すると、アクター ネットワークとクリティック ネットワークの初期パラメーターがランダムな値で初期化されます。エージェントが常に同じパラメーター値で初期化されるように、乱数ストリームを固定します。
rng(0,"twister");この例では、DDPG エージェントまたは TD3 エージェントを使用してロボットに学習させるオプションを示します。好みのエージェントを使用してロボットをシミュレートするには、AgentSelection フラグを適宜設定します。
AgentSelection ="DDPG"; switch AgentSelection case "DDPG" agent = createDDPGAgent(numObs,obsInfo,numAct,actInfo,Ts); case "TD3" agent = createTD3Agent(numObs,obsInfo,numAct,actInfo,Ts); otherwise disp("Assign AgentSelection to DDPG or TD3") end
(例のフォルダーに用意されている) createDDPGAgent 補助関数および createTD3Agent 補助関数は、次のアクションを実行します。
アクター ネットワークとクリティック ネットワークの作成。
アクターとクリティックのオプションの指定。
以前に作成したネットワークとオプションを使用して、アクターとクリティックを作成。
エージェント固有のオプションの設定。
エージェントの作成。
DDPG エージェント
DDPG エージェントは、連続行動空間において、パラメーター化された決定論的方策を使用します。この方策は、連続決定論的アクター、および方策の価値を推定するパラメーター化された Q 値関数近似器によって学習されます。方策と Q 値関数は、ニューラル ネットワークを使用してモデル化されます。この例のアクター ネットワークとクリティック ネットワークは、[1] からヒントを得ています。
DDPG エージェントの作成方法の詳細については、補助関数 createDDPGAgent を参照してください。DDPG エージェントのオプション設定の詳細については、rlDDPGAgentOptionsを参照してください。
深層ニューラル ネットワークの値関数表現の作成の詳細については、Create Actors, Critics, and Policy Objectsを参照してください。DDPG エージェント用のニューラル ネットワークの作成例については、Compare DDPG Agent to LQR Controllerを参照してください。
TD3 エージェント
DDPG エージェントのクリティックは、Q 値を過大に推定する場合があります。エージェントは Q 値を使用して方策 (アクター) を更新するため、結果として得られる方策は準最適となる可能性があり、学習誤差が累積して動作の逸脱につながることがあります。TD3 アルゴリズムは DDPG を拡張したもので、Q 値の過大推定を防いでロバスト性を向上させます [3]。
2 つのクリティック ネットワーク — TD3 エージェントは、2 つのクリティック ネットワークをそれぞれ独立して学習し、関数の最小推定値を使用してアクター (方策) を更新します。これにより、後続のステップで誤差が累積され、Q 値が過大に推定されるのを防ぎます。
ターゲット方策ノイズの追加 — クリップされたノイズを価値関数に追加して、同様のアクションについて Q 関数の値を平滑化します。これにより、ノイズを含む推定値のシャープなピークを間違って学習するのを防ぎます。
方策とターゲットの遅延付き更新 — TD3 エージェントで、アクター ネットワークの更新を遅らせて、方策を更新する前に Q 関数が誤差を減らす (必要なターゲットにさらに近づく) ための時間が得られるようにします。これにより、推定値の分散が抑制され、より高品質の方策更新が可能になります。この例では、2 つのクリティック ネットワークとターゲット方策ノイズの影響を DDPG エージェントと TD3 エージェントの間でより適切に比較するために、方策の更新頻度とターゲット更新頻度のオプションを
1に設定します。
このエージェントで使用されるアクター ネットワークとクリティック ネットワークの構造は、DDPG エージェントで使用されるものと同じです。TD3 エージェントの作成の詳細については、補助関数 createTD3Agent を参照してください。TD3 エージェントのオプション設定の詳細については、rlTD3AgentOptionsを参照してください。
エージェントからアクターとクリティックのニューラル ネットワークを取得します。
actor = getActor(agent); critic = getCritic(agent); actorNet = getModel(actor); criticNet = getModel(critic(1));
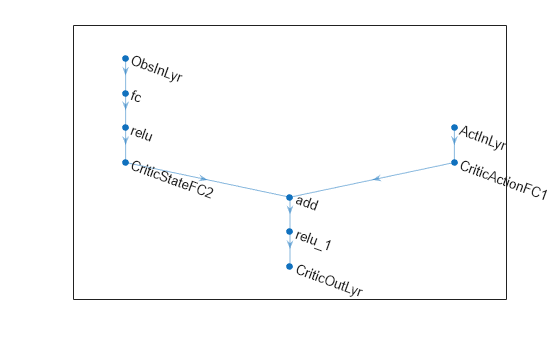
アクター ニューラル ネットワークの概要とプロットを表示します。
summary(actorNet);
Initialized: true
Number of learnables: 134.1k
Inputs:
1 'input' 29 features
plot(actorNet);

クリティック ニューラル ネットワークの概要とプロットを表示します。
summary(criticNet);
Initialized: true
Number of learnables: 134.7k
Inputs:
1 'ObsInLyr' 29 features
2 'ActInLyr' 6 features
plot(criticNet);
学習オプションの指定とエージェントの学習
この例の場合、DDPG エージェントと TD3 エージェントの学習オプションは同じです。
各学習セッションを 3000 個のエピソードに対して実行 (各エピソードの持続時間は最大
maxStepsタイム ステップ)。StopTrainingCriteriaを"none"に設定し、エピソードが最大数 (maxEpisodes) に達したときにのみ学習を終了させる。これにより、複数のエージェントについて学習セッション全体の学習曲線を比較することが可能。
詳細とその他のオプションについては、rlTrainingOptions を参照してください。
maxEpisodes = 3000; maxSteps = floor(Tf/Ts); trainOpts = rlTrainingOptions( ... MaxEpisodes=maxEpisodes, ... MaxStepsPerEpisode=maxSteps, ... ScoreAveragingWindowLength=250, ... StopTrainingCriteria="none", ... SimulationStorageType="file", ... SaveSimulationDirectory=AgentSelection+"Sims");
並列でエージェントに学習させるには、次の学習オプションを指定します。並列で学習させるには、Parallel Computing Toolbox™ が必要です。Parallel Computing Toolbox ソフトウェアがインストールされていない場合は、UseParallel を false に設定します。
UseParallelオプションを trueに設定。エージェントの学習を並列かつ非同期に実行。
trainOpts.UseParallel =true; trainOpts.ParallelizationOptions.Mode =
"async";
並列学習では、ワーカーは環境を使用してエージェントの方策をシミュレートし、経験をリプレイ メモリに保存します。ワーカーが非同期的に動作する場合、保存された経験の順序は確定的ではない可能性があるため、最終的な学習結果が異なる可能性があります。再現性の可能性を最大限高めるには次のようにします。
コードを実行するたびに、同じ数の並列ワーカーで並列プールを初期化する。プール サイズの指定については、クラスターの検出とクラスター プロファイルの使用 (Parallel Computing Toolbox)を参照してください。
trainOpts.ParallelizationOptions.Modeを"sync"に設定して同期並列学習を使用する。trainOpts.ParallelizationOptions.WorkerRandomSeedsを使用し、各並列ワーカーに乱数シードを割り当てる。既定値 -1 は、各並列ワーカーに一意の乱数シードが割り当てられることを意味します。
再現性のために乱数ストリームを固定します。
rng(0,"twister");関数 train を使用して、エージェントに学習させます。このプロセスは計算量が多いので、各エージェントが処理を完了するのに数時間かかります。この例の実行時間を節約するために、doTraining を false に設定して事前学習済みのエージェントを読み込みます。エージェントに学習させるには、doTraining を true に設定します。並列学習にはランダム性が存在するため、以下のプロットとは異なる学習結果が期待できます。この事前学習済みのエージェントは、4 つのワーカーを使用して並列学習が行われています。
doTraining =false; if doTraining % Train the agent. trainingStats = train(agent,env,trainOpts); else % Load a pretrained agent for the selected agent type. if strcmp(AgentSelection,"DDPG") load(fullfile("DDPGAgent","run1.mat"),"agent") else load(fullfile("TD3Agent","run1.mat"),"agent") end end

学習済みエージェントのシミュレーション
再現性のために乱数ストリームを固定します。
rng(0,"twister");学習済みエージェントのパフォーマンスを検証するには、二足歩行ロボット環境内でこのエージェントをシミュレートします。エージェントのシミュレーションの詳細については、rlSimulationOptions および sim を参照してください。
simOptions = rlSimulationOptions(MaxSteps=maxSteps); experience = sim(env,agent,simOptions);

エージェントのパフォーマンスの比較
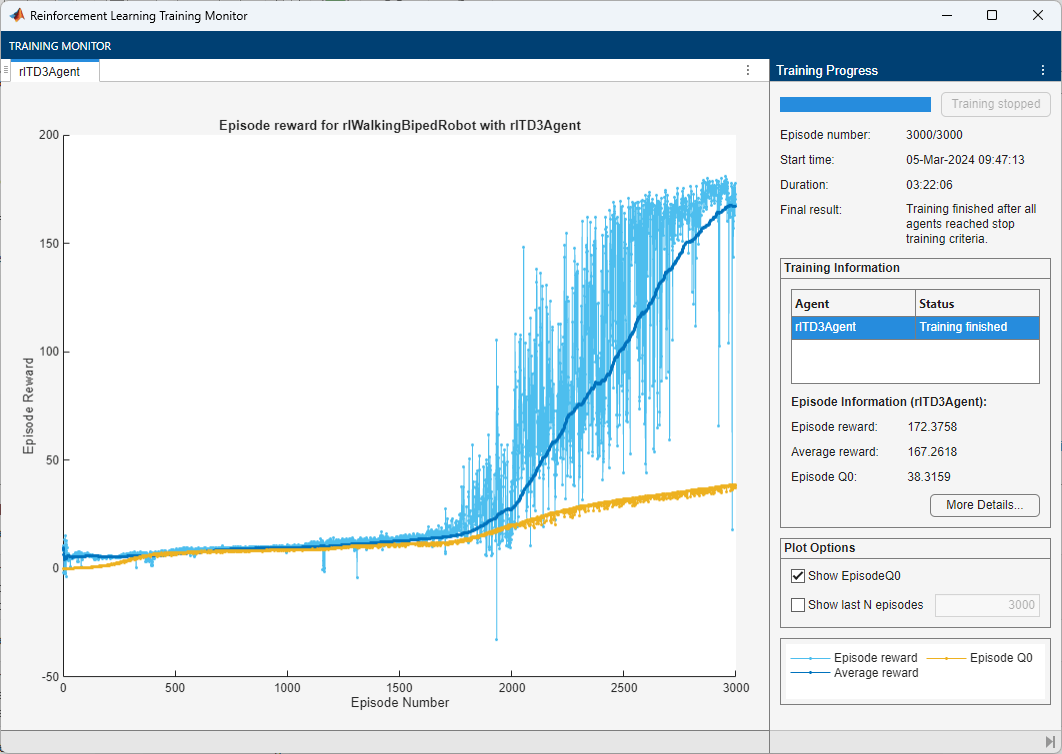
次に示すエージェントの比較では、毎回異なる乱数シードを使用して、各エージェントに 5 回学習させました。探査ノイズがランダムであり、並列学習にランダム性が存在するため、実行のたびに異なる学習曲線が得られます。エージェントの学習を複数回実行すると完了するまでに数日かかる可能性があるため、この比較では事前学習済みのエージェントを使用します。
DDPG エージェントと TD3 エージェントについて、エピソードの報酬の平均と標準偏差 (上部プロット)、およびエピソードの Q0 値 (下部プロット) をプロットします。エピソードの Q0 値は、環境の初期観測値が与えられた場合の、各エピソード開始時における割引長期報酬のクリティック推定値です。適切に設計されたクリティックでは、エピソードの Q0 値が真の割引長期報酬に近づきます。
再現性のために乱数ストリームを固定します。
rng(0,"twister");DDPGAgent フォルダーと TD3Agent フォルダーに保存されているデータを使用し、事前学習済みエージェントのパフォーマンスを比較します。パフォーマンス メトリクスをプロットするため、comparePerformance 関数の入力引数としてフォルダー名を指定します。比較データと関数は、例のディレクトリにあります。
comparePerformance("DDPGAgent","TD3Agent")
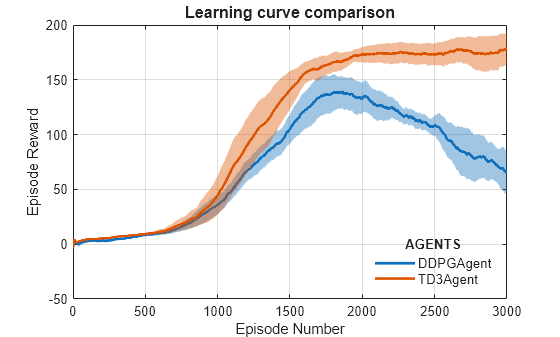

学習曲線の比較プロットから、次がわかります。
DDPG エージェントは場合によっては TD3 エージェントよりも高速に学習できますが、DDPG エージェントは長期にわたって学習させた場合のパフォーマンスに一貫性がない傾向があります。
TD3 エージェントは、環境に対して満足のいく歩行方策を一貫して学習しており、DDPG と比較して優れた収束特性を示す傾向があります。
エピソードの Q0 の比較プロットから、次がわかります。
TD3 エージェントは、DDPG と比較して、割引長期報酬をより控えめに推定します。これは、TD3 が、2 つのクリティックから近似した値の最小値として割引長期報酬を推定するためです。
DDPG エージェントを使用してヒューマノイド ロボットに歩行を学習させる方法の別の例については、ヒューマノイド ウォーカーの学習 (Simscape Multibody)を参照してください。DDPG エージェントを使用して四足歩行ロボットに歩行を学習させる方法の例については、DDPG エージェントを使用した四足歩行ロボットの移動を参照してください。
previousRngState に保存されている情報を使用して、乱数ストリームを復元します。
rng(previousRngState);
参考文献
[1] Lillicrap, Timothy P., Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. "Continuous Control with Deep Reinforcement Learning." Preprint, submitted July 5, 2019. https://arxiv.org/abs/1509.02971.
[2] Heess, Nicolas, Dhruva TB, Srinivasan Sriram, Jay Lemmon, Josh Merel, Greg Wayne, Yuval Tassa, et al. "Emergence of Locomotion Behaviours in Rich Environments." Preprint, submitted July 10, 2017. https://arxiv.org/abs/1707.02286.
[3] Fujimoto, Scott, Herke van Hoof, and David Meger. "Addressing Function Approximation Error in Actor-Critic Methods." Preprint, submitted October 22, 2018. https://arxiv.org/abs/1802.09477.
参考
関数
train|sim|rlSimulinkEnv
オブジェクト
rlDDPGAgent|rlDDPGAgentOptions|rlTD3Agent|rlTD3AgentOptions|rlQValueFunction|rlContinuousDeterministicActor|rlOptimizerOptions|rlTrainingOptions|rlSimulationOptions
ブロック
トピック
- Train AC Agent to Balance Discrete Cart-Pole Using Parallel Computing
- 並列計算を使用した車線維持支援用 DQN エージェントの学習
- DDPG エージェントを使用した四足歩行ロボットの移動
- Add Safety Constraint to Simulate Two-Link Robot with SAC Agent
- Define Observation and Reward Signals in Custom Environments
- 深層決定論的方策勾配 (DDPG) エージェント
- 双生遅延深層決定論的 (TD3) 方策勾配エージェント
- Train Agents Using Parallel Computing and GPUs