CNN-LSTM ネットワークを使用したシーケンス分類
この例では、2 次元畳み込みニューラル ネットワーク (CNN) と長短期記憶 (LSTM) 層を組み合わせ、音声分類タスク用の 2 次元 CNN-LSTM ネットワークを作成する方法を示します。
CNN は、入力にスライディング畳み込みフィルターを適用してシーケンス データを処理します。CNN は、空間次元と時間次元の両方から特徴を学習できます。LSTM ネットワークは、タイム ステップをループ処理し、タイム ステップ間の長期的な依存関係を学習することで、シーケンス データを処理します。CNN-LSTM ネットワークは、畳み込み層と LSTM 層を使用して学習データから学習します。
オーディオ データを使用して CNN-LSTM ネットワークに学習させるには、生のオーディオ データから聴覚ベースのスペクトログラムを抽出し、そのスペクトログラムを使用してネットワークに学習させます。次の図は、このネットワークのアプリケーションを示しています。

この例では、Berlin Database of Emotional Speech (Emo-DB) [1] を使用し、2 次元 CNN-LSTM ネットワークに学習させて音声テキストの感情を認識させます。感情はテキストに依存しません。つまり、データには感情を示す手がかりとなるテキストは含まれていません。
データ セットのダウンロード
Emo-DB [1] データ セットをダウンロードします。このデータセットには、怒り、退屈、嫌悪、不安/恐怖、幸福、悲しみ、中立のいずれかの感情でラベル付けされた、10 人の俳優による 535 個の発話が含まれています。
dataFolder = fullfile(tempdir,"Emo-DB"); if ~datasetExists(dataFolder) url = "http://emodb.bilderbar.info/download/download.zip"; disp("Downloading Emo-DB (40.5 MB) ...") unzip(url,dataFolder) end
データのaudioDatastore (Audio Toolbox)オブジェクトを作成します。
location = fullfile(dataFolder,"wav");
ads = audioDatastore(location);ファイル名には、話者 ID、発話されたテキスト、感情、およびバージョンが符号化されています。感情ラベルは次のように符号化されます。
W — 怒り
L — 退屈
E — 嫌悪感
A — 不安/恐怖
F — 幸福
T — 悲しみ
N — 中立
ファイル名から感情ラベルを抽出します。ファイル名の 6 番目の文字では、感情ラベルが符号化されています。
filepaths = ads.Files; [~,filenames] = fileparts(filepaths); emotionLabels = extractBetween(filenames,6,6);
1 文字のコードを記述ラベルに置き換えます。
emotionCodeNames = ["W" "L" "E" "A" "F" "T" "N"]; emotionNames = ["Anger" "Boredom" "Disgust" "Anxiety/Fear" "Happiness" "Sadness" "Neutral"]; emotionLabels = replace(emotionLabels,emotionCodeNames,emotionNames);
ラベルを categorical 配列に変換します。
emotionLabels = categorical(emotionLabels);
audioDatastore オブジェクトの Labels プロパティを emotionLabels に設定します。
ads.Labels = emotionLabels;
ヒストグラムでクラスの分布を表示します。
figure histogram(emotionLabels) title("Class Distribution") ylabel("Number of Observations")

データストアからサンプルを読み取り、プロットで波形を表示し、サンプルを再生します。
[audio,info] = read(ads); fs = info.SampleRate; sound(audio,fs) figure plot((1:length(audio))/fs,audio) title("Class: " + string(emotionLabels(1))) xlabel("Time (s)") ylabel("Amplitude")
学習用データの準備
データを学習データ、検証データ、テスト データに分割します。データの 70% を学習に、データの 15% を検証に、データの 15% をテストに使用します。
[adsTrain,adsValidation,adsTest] = splitEachLabel(ads,0.70,0.15,0.15);
学習観測値の数を表示します。
numObservationsTrain = numel(adsTrain.Files)
numObservationsTrain = 374
深層学習モデルに学習させるには、通常、良好な適合度を実現するために多くの学習観測値が必要です。利用できる学習データがあまりない場合は、拡張を行って学習データのサイズを人為的に増やすことで、ネットワークの適合度を高めることができます。
audioDataAugmenter (Audio Toolbox)オブジェクトを作成します。
各ファイルに 75 個の拡張を指定します。各ファイルの拡張数をいろいろと試すことで、処理時間と精度向上との間のトレードオフを比較することができます。
ピッチ シフトを適用する確率を
0.5に設定します。時間シフトを適用する確率を
1に設定し、範囲を[-0.3 0.3]秒に設定します。ノイズを追加する確率を
1に設定し、SNR の範囲を[-20 40]dB に設定します。
numAugmentations =75; augmenter = audioDataAugmenter(NumAugmentations=numAugmentations, ... TimeStretchProbability=0, ... VolumeControlProbability=0, ... PitchShiftProbability=0.5, ... TimeShiftProbability=1, ... TimeShiftRange=[-0.3 0.3], ... AddNoiseProbability=1, ... SNRRange=[-20 40]);
拡張されたデータを保持するための新しいフォルダーを作成します。
agumentedDataFolder = fullfile(pwd,"augmentedData");
mkdir(agumentedDataFolder)ネットワークへの入力時にデータを拡張することも、学習前に学習データを拡張し、拡張したファイルをディスクに保存しておくこともできます。結果をディスクに保存しておくと、ほとんどの場合、全体的な学習時間が短縮されるため、さまざまなネットワーク アーキテクチャや学習オプションを試すのに役立ちます。
データストアをループ処理し、オーディオ データ拡張機能を使用して学習データを拡張します。各拡張について次のようにします。
最大値が 1 になるように拡張を正規化します。
拡張データを WAV ファイルに保存し、ファイル名に
"_augK"を追加します。ここで、Kは拡張番号です。
拡張処理を高速化するには、parfor (Parallel Computing Toolbox)ループを使用してオーディオ ファイルを並列処理します。つまり、オーディオ データストアを小さな塊に分割し、その塊を並列でループ処理します。parfor を使用するには、Parallel Computing Toolbox™ ライセンスが必要です。Parallel Computing Toolbox ライセンスがない場合、parfor ループは逐次的に実行されます。
reset(ads) numPartitions = 50; augmentationTimer = tic; parfor i = 1:numPartitions adsPart = partition(adsTrain,numPartitions,i); while hasdata(adsPart) [X,info] = read(adsPart); data = augment(augmenter,X,fs); [~,name] = fileparts(info.FileName); for n = 1:numAugmentations XAug = data.Audio{n}; XAug = XAug/max(abs(XAug),[],"all"); nameAug = name + "_aug" + string(n); filename = fullfile(agumentedDataFolder,nameAug + ".wav"); audiowrite(filename,XAug,fs); end end end toc(augmentationTimer)
Elapsed time is 509.574047 seconds.
拡張されたデータ セットのオーディオ データストアを作成します。
augadsTrain = audioDatastore(agumentedDataFolder);
拡張データと元のデータのファイル名は接尾辞のみが異なるため、拡張データのラベルは元のラベルの繰り返し要素になります。元のデータストアのラベルの行を NumAugmentations 回複製し、それらを新しいデータストアの Labels プロパティに割り当てます。
augadsTrain.Labels = repelem(adsTrain.Labels,augmenter.NumAugmentations,1);
audioFeatureExtractor (Audio Toolbox)オブジェクトを使用して、オーディオ データから特徴量を抽出します。次のように指定します。
ウィンドウ長 2048 サンプル
ホップ長 512 サンプル
周期的なハミング ウィンドウ
片側メル スペクトルを抽出
windowLength = 2048; hopLength = 512; afe = audioFeatureExtractor( ... Window=hamming(windowLength,"periodic"), ... OverlapLength=(windowLength - hopLength), ... SampleRate=fs, ... melSpectrum=true);
特徴抽出器の抽出パラメーターを設定します。メルの帯域数を 128 に設定し、ウィンドウ正規化を無効にします。
numBands = 128; setExtractorParameters(afe,"melSpectrum", ... NumBands=numBands, ... WindowNormalization=false)
この例のオーディオ データ前処理関数セクションにリストされている preprocessAudioData 関数を使用して、学習用、検証用、およびテスト用のデータストアから特徴量とラベルを抽出します。
[featuresTrain,labelsTrain] = preprocessAudioData(augadsTrain,afe); [featuresValidation,labelsValidation] = preprocessAudioData(adsValidation,afe); [featuresTest,labelsTest] = preprocessAudioData(adsTest,afe);
いくつかの学習サンプルについて波形と聴覚スペクトログラムをプロットします。
numPlots = 3; idx = randperm(numel(augadsTrain.Files),numPlots); f = figure; f.Position(3) = 2*f.Position(3); tiledlayout(2,numPlots,TileIndexing="columnmajor") for ii = 1:numPlots [X,fs] = audioread(augadsTrain.Files{idx(ii)}); nexttile plot(X) axis tight title(augadsTrain.Labels(idx(ii))) xlabel("Time") ylabel("Amplitude") nexttile spect = permute(featuresTrain{idx(ii)}(:,1,:), [1 3 2]); pcolor(spect) shading flat xlabel("Time") ylabel("Frequency") end

最初のいくつかの観測値のサイズを表示します。この観測値は、1 つの空間次元をもつサンプルのシーケンスです。この観測値のサイズは、numBands×1×numTimeSteps です。ここで、numBands はデータの空間次元に対応し、numTimeSteps はデータの時間次元に対応します。
featuresTrain(1:10)
ans=10×1 cell array
128×1×56 double
128×1×56 double
128×1×56 double
128×1×56 double
128×1×56 double
128×1×56 double
128×1×56 double
128×1×56 double
128×1×56 double
128×1×56 double
ネットワークが学習データをサポートしていることを確認するには、シーケンス入力層の MinLength オプションを使用し、シーケンスがネットワークを通過できるかどうかをチェックします。入力層に渡す最短シーケンスの長さを計算します。
sequenceLengths = zeros(1,numObservationsTrain); for n = 1:numObservationsTrain sequenceLengths(n) = size(featuresTrain{n},3); end minLength = min(sequenceLengths)
minLength = 41
2 次元 CNN LSTM アーキテクチャの定義
[2] に基づいて、シーケンスのクラス ラベルを予測する 2 次元 CNN LSTM ネットワークを定義します。

シーケンス入力の場合は、入力データと一致する入力サイズのシーケンス入力層を指定します。ネットワークが学習データを確実にサポートするように、
MinLengthオプションを学習データ内で最も短いシーケンスの長さに設定します。1 次元イメージ シーケンス内の空間関係を学習するには、畳み込み層、バッチ正規化層、ReLU 層、最大プーリング層の 4 つのブロックが繰り返された 2 次元 CNN アーキテクチャを使用します。3 番目と 4 番目の畳み込み層に、それまでより多くのフィルターを指定します。
1 次元イメージ シーケンスの長期的な依存関係を学習するには、256 個の隠れユニットをもつ LSTM 層を含めます。シーケンスを単一の予測値にマッピングするには、
OutputModeオプションを"last"に設定し、最後のタイム ステップのみを出力します。分類用に、クラスの数と同じサイズの全結合層を含めます。出力を確率ベクトルに変換するには、ソフトマックス層を含めます。
filterSize = 3;
numFilters = 64;
numHiddenUnits = 256;
inputSize = [numBands 1];
numClasses = numel(categories(emotionLabels));
layers = [
sequenceInputLayer(inputSize,MinLength=minLength)
convolution2dLayer(filterSize,numFilters,Padding="same")
batchNormalizationLayer
reluLayer
maxPooling2dLayer(2,Stride=2)
convolution2dLayer(filterSize,numFilters,Padding="same")
batchNormalizationLayer
reluLayer
maxPooling2dLayer([4 2],Stride=[4 2])
convolution2dLayer(filterSize,2*numFilters,Padding="same")
batchNormalizationLayer
reluLayer
maxPooling2dLayer([4 2],Stride=[4 2])
convolution2dLayer(filterSize,2*numFilters,Padding="same")
batchNormalizationLayer
reluLayer
maxPooling2dLayer([4 2],Stride=[4 2])
flattenLayer
lstmLayer(numHiddenUnits,OutputMode="last")
fullyConnectedLayer(numClasses)
softmaxLayer];学習オプションの指定
trainingOptions関数を使用し、次のように学習オプションを指定します。
ミニバッチ サイズを 32 とし、Adam ソルバーを使用してネットワークに 3 エポック学習させます。
初期学習率 0.005 で学習させ、2 エポック後に学習率を段階的に減らします。
学習データの過適合を防ぐには、値が 0.0005 である L2 正則化項を指定します。
LSTM 層が出力するシーケンスの最後のタイム ステップにパディング値が影響するのを防ぐには、学習シーケンスを左パディングします。
すべてのエポックでデータをシャッフルします。
エポックごとに 1 回、検証データを使用して学習の進行状況を検証します。
学習の進行状況をプロットに表示し、学習と検証の精度を表示します。
詳細出力を非表示にします。
GPU が利用できる場合、GPU で学習を行います。既定では、関数
trainnetは利用可能な GPU がある場合にそれを使用します。GPU を使用するには、Parallel Computing Toolbox™ ライセンスとサポートされている GPU デバイスが必要です。サポートされているデバイスの詳細については、GPU 計算の要件 (Parallel Computing Toolbox)を参照してください。そうでない場合、関数は CPU を使用します。実行環境を手動で選択するには、ExecutionEnvironment学習オプションを使用します。
miniBatchSize = 32; options = trainingOptions("adam", ... MaxEpochs=3, ... MiniBatchSize=miniBatchSize, ... InitialLearnRate=0.005, ... LearnRateDropPeriod=2, ... LearnRateSchedule="piecewise", ... L2Regularization=5e-4, ... SequencePaddingDirection="left", ... Shuffle="every-epoch", ... ValidationFrequency=floor(numel(featuresTrain)/miniBatchSize), ... ValidationData={featuresValidation,labelsValidation}, ... Plots="training-progress", ... Metrics="accuracy", ... Verbose=false);
ネットワークの学習
関数trainnetを使用してニューラル ネットワークに学習させます。分類には、クロスエントロピー損失を使用します。
net = trainnet(featuresTrain,labelsTrain,layers,"crossentropy",options);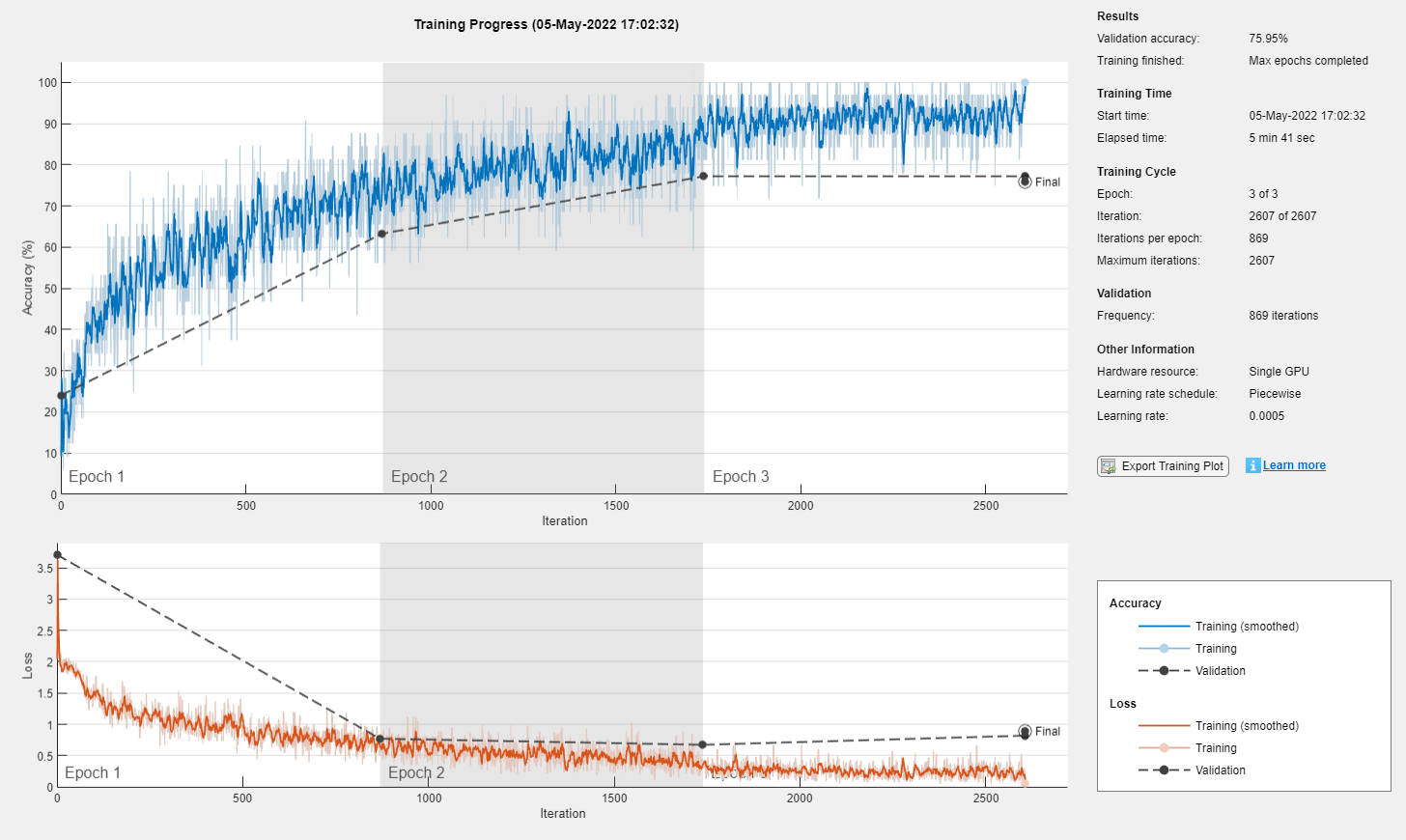
ネットワークのテスト
testnet関数を使用してニューラル ネットワークをテストします。単一ラベルの分類では、精度を評価します。精度は、正しい予測の割合です。既定では、testnet 関数は利用可能な GPU がある場合にそれを使用します。実行環境を手動で選択するには、testnet 関数の ExecutionEnvironment 引数を使用します。
accuracy = testnet(net,featuresTest,labelsTest,"accuracy", ... MiniBatchSize=miniBatchSize, ... SequencePaddingDirection="left")
accuracy = 67.5000
テストの予測を混同行列で可視化します。
scores = minibatchpredict(net,featuresTest, ... MiniBatchSize=miniBatchSize, ... SequencePaddingDirection="left"); classNames = categories(labelsTest); labelsPred = scores2label(scores,classNames); figure confusionchart(labelsTest,labelsPred)

サポート関数
オーディオ データ前処理関数
preprocessAudioData 関数は、オーディオ特徴抽出器 afe を使用し、オーディオ データストア ads から特徴量とラベルを抽出します。この関数は、この例の特徴抽出関数セクションにデータストア変換関数としてリストされている extractFeatures 関数を使用してデータを変換します。この関数は、データを処理するため、変換されたデータストアを作成し、readall 関数を使用してすべてのデータを読み取ります。この関数は、データを並列で読み取るため、readall 関数の UseParallel オプションを設定します。並列で読み取りを行うには、Parallel Computing Toolbox ライセンスが必要です。この関数は、データの読み取りに並列プールを使用できるかどうかを確認するため、canUseParallelPool関数を使用します。
function [features,labels] = preprocessAudioData(ads,afe) % Transform datastore. tds = transform(ads,@(X) extractFeatures(X,afe)); % Read all data. tf = canUseParallelPool; features = readall(tds,UseParallel=tf); % Extract labels. labels = ads.Labels; end
特徴抽出関数
extractFeatures 関数は、オーディオ特徴抽出器 afe を使用し、オーディオ データ X から特徴量を抽出します。この関数は、抽出された特徴量の対数を計算し、学習で使用できるように、データを numBands×1×numTimeSteps のサイズに並べ替えます。
function features = extractFeatures(X,afe) features = log(extract(afe,X) + eps); features = permute(features, [2 3 1]); features = {features}; end
参考文献
[1] Burkhardt, Felix, A. Paeschke, M. Rolfes, Walter F. Sendlmeier, and Benjamin Weiss. “A Database of German Emotional Speech.” In Interspeech 2005, 1517–20. ISCA, 2005. https://doi.org/10.21437/Interspeech.2005-446.
[2] Zhao, Jianfeng, Xia Mao, and Lijiang Chen. “Speech Emotion Recognition Using Deep 1D & 2D CNN LSTM Networks.” Biomedical Signal Processing and Control 47 (January 2019): 312–23. https://doi.org/10.1016/j.bspc.2018.08.035.
参考
trainnet | trainingOptions | dlnetwork | sequenceInputLayer | convolution2dLayer | lstmLayer