フランケ データの曲面近似
曲線フィッター アプリには、フランケの二変量テスト関数から生成されたサンプル データが用意されています。このデータは、曲線フィッター アプリでさまざまな近似設定を試すのに適しています。このデータを使って、曲面近似を作成、比較、エクスポートします。
MATLAB® コマンド ラインで、
frankeデータ セットを読み込みます。変数x、y、zがワークスペースに表示されます。load frankeこのサンプル データは、曲線フィッター アプリでさまざまな近似設定を試すために適切なデータを作成できるよう、フランケの二変量テスト関数から生成され、ノイズとスケーリングが追加されています。フランケ関数の詳細については、[1] を参照してください。
データを近似データと検証データに分けます。
xv = x(200:293); yv = y(200:293); zv = z(200:293); x = x(1:199); y = y(1:199); z = z(1:199);
サンプル データを使用して曲面を当てはめます。
曲線フィッター アプリを開きます。
または、[アプリ] タブの [数学、統計および最適化] グループで [曲線フィッター] をクリックします。curveFitter
曲線フィッター アプリで、データ変数を選択します。[曲線フィッター] タブの [データ] セクションで [データの選択] をクリックします。[近似データの選択] ダイアログ ボックスで、
[x]を [X データ] 変数として、[y]を [Y データ] 変数として、[z]を [Z データ] 変数として指定します。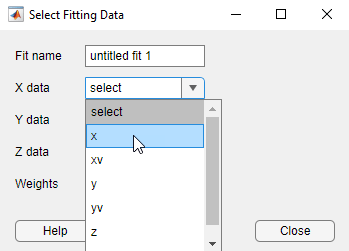
または、
curveFitterを使用して曲線フィッター アプリを開くときにデータ変数を指定し、既定の近似 (curveFitter(x,y,z)) を作成することもできます。
変数を選択すると、曲線フィッター アプリによってデータ点がプロットされます。
x、y、zを選択すると、既定の曲面近似が自動的に作成されます。既定の近似はデータ点を通過する内挿曲面です。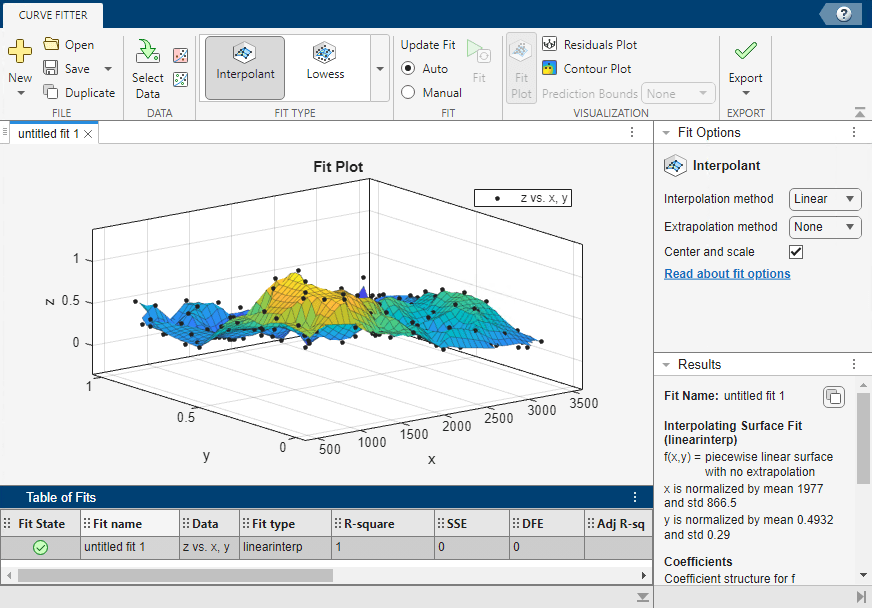
Lowess 近似タイプを試します。[曲線フィッター] タブの [近似タイプ] セクションで、矢印をクリックしてギャラリーを開きます。[平滑化] グループの [局所回帰平滑化 (Lowess)] をクリックします。
曲線フィッター アプリにより、局所平滑化回帰近似が作成されます。
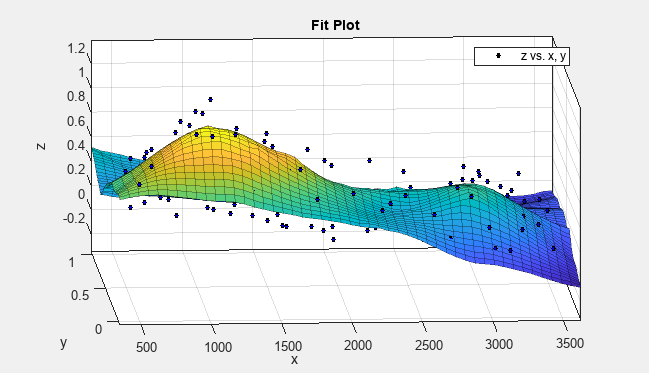
近似設定を変えてみます。[近似オプション] ペインで、[範囲 (%)] の値を
10に変更します。範囲を既定の設定から合計データ点数の 10% に減らすと、よりデータに近い曲面が生成されます。この範囲によって、それぞれの平滑化値を決定するために使用される隣接データ点が定義されます。
[近似テーブル] ペインで、[近似名] を
Smoothing regressionに変更します。検証データを使用して、曲面が適切なモデルになっているかを確認します。つまり、曲面を、近似に使用されていないデータと比較します。
[曲線フィッター] タブの [データ] セクションで [検証データ] をクリックします。[検証データの選択] ダイアログ ボックスで、[X データ]、[Y データ]、[Z データ] のドロップダウン リストから検証変数の
xv、yv、zvを選択します。プロット内の選択した検証データと、[結果] ペインおよび [近似テーブル] ペインの検証統計量 (SSE および RMSE) を確認します。
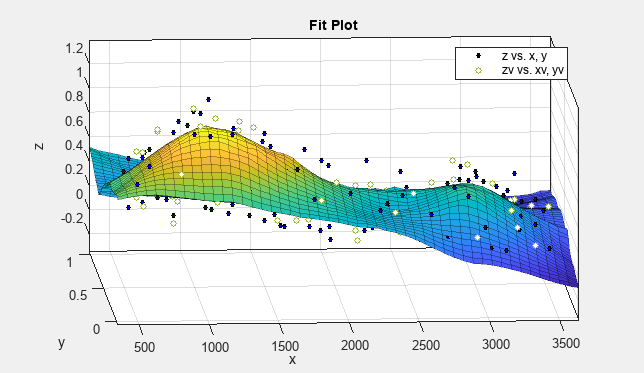
現在の曲面近似をコピーして、別の近似を作成します。[曲線フィッター] タブの [ファイル] セクションで [複製] をクリックします。または、[近似テーブル] ペインの近似を右クリックして、["Smoothing regression" を複製] を選択します。
同じ近似設定、データ、検証データで新しい近似の Figure が作成されます。また、新しい行が近似テーブルの下部に追加されます。
新しい近似のタイプと名前を変更します。[曲線フィッター] タブの [近似タイプ] セクションで、矢印をクリックしてギャラリーを開きます。[回帰モデル] グループの [多項式] をクリックします。
[近似テーブル] ペインで、[近似名] を
Polynomialに変更します。[近似オプション] ペインで、[X の次数] および [Y の次数] の値を
[3]に変更し、両方の次元において 3 次多項式を当てはめます。x 軸および y 軸のスケールを確認し、[結果] ペインに表示される警告メッセージを確認します。
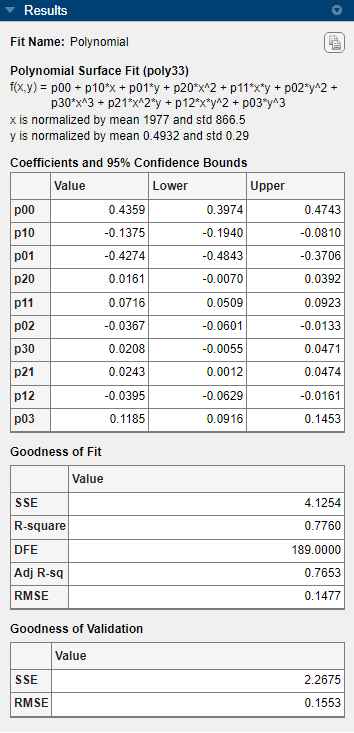
方程式の条件が不適切です。繰り返しデータ点を削除するか、センタリングとスケーリングを試してください。[近似オプション] ペインで、[データのセンタリングとスケーリング] チェック ボックスをオンにして正規化し、x と y のスケールの大きな違いを補正します。

曲面近似を正規化すると [結果] ペインの警告メッセージが消えます。
[結果] ペインを見てみます。以下を確認できます。
モデルの方程式
推定係数の値
適合度の統計量
検証の適合度の統計量
この近似情報をワークスペースにエクスポートするには、[曲線フィッター] タブの [エクスポート] セクションで、[エクスポート] をクリックして [ワークスペースにエクスポート] を選択します。このコマンドを実行すると、観測値とパラメーターの数、残差、近似モデルなどその他の情報もエクスポートされます。
この近似モデルを、X および Y の値で曲面を予測または評価する関数として扱うことができます。詳細については、ワークスペースへの近似のエクスポートを参照してください。
残差のプロットを表示し、曲面に対する点の分布を確認します。[曲線フィッター] タブの [可視化] セクションで [残差プロット] をクリックします。

残差プロットを右クリックし、[X-Z 表示に移動] を選択します。X-Z 表示は必須ではありませんが、この表示を使用すると削除する外れ値を簡単に確認できます。
外れ値を削除するには、座標軸ツール バーの [外れ値を除外] ボタン
 をクリックします。
をクリックします。マウス カーソルをプロットに移動すると、カーソルが十字に変わり、外れ値選択モードであることが示されます。
表面プロットまたは残差プロットで除外する点をクリックします。または、クリックしてドラッグすることにより四角形を指定し、囲まれたすべての点を削除します。
プロットでは、削除した点は赤い X 印として表示されます。

[曲線フィッター] タブの [近似] セクションで [自動] を選択していた場合は、削除した点を除いた状態で曲面が再度当てはめられます。一方、[手動] を選択していた場合は、[近似] をクリックして曲面の再近似を行います。
プロット内で回転モードに戻るには、[外れ値を除外] ボタン
を再度クリックします。
近似を並べて比較します。近似の Figure タブの右端にある [ドキュメント アクション] ボタンをクリックします。
[すべて並べて表示]オプションを選択して、1 行 2 列のレイアウトを指定します。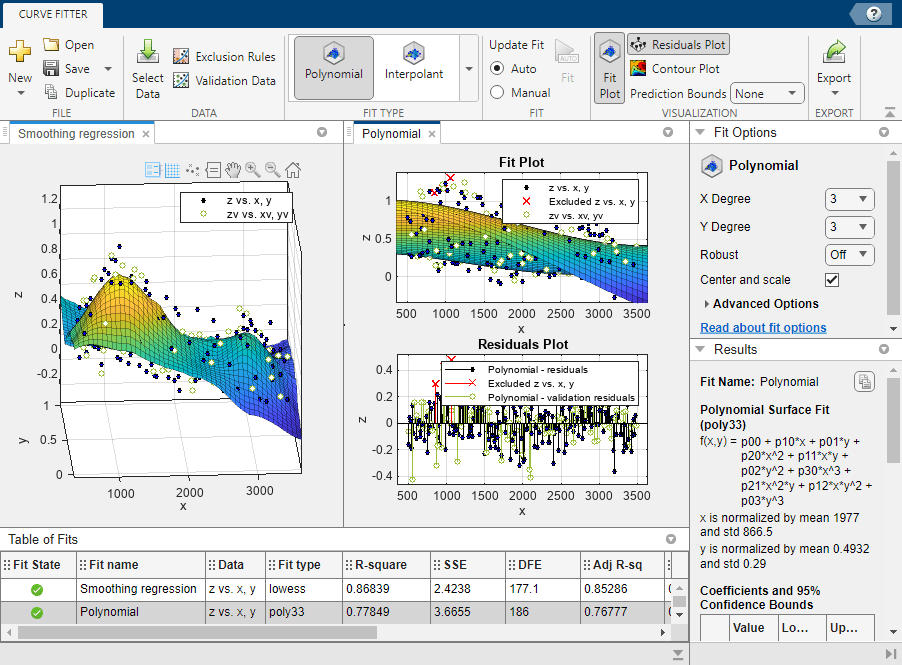
[近似テーブル] ペインで情報を確認します。セッション内のすべての近似について適合度の統計量を比較し、どれが最適かを判断します。
対話型の曲面近似セッションを保存するには、[曲線フィッター] タブの [ファイル] セクションで [保存] をクリックします。セッションを保存して再度開くと複数の近似にアクセスできます。セッション ファイルには、セッション内のすべての近似と変数が含まれています。
近似を対話的に作成し比較した後で、曲線フィッター アプリのセッションで近似ごとに MATLAB コードを生成できます。[曲線フィッター] タブの [エクスポート] セクションで [エクスポート] をクリックし、[コード生成] を選択します。
曲線フィッター アプリはセッションからコードを生成し、MATLAB エディターにファイルを表示します。このファイルには、セッション内で現在選択されている近似と、開かれているプロットが含まれます。
ファイルを
createFit.mという既定の名前で保存します。近似とプロットを再作成するには、コマンド ラインから (元のデータまたは新しいデータを入力引数に指定して) そのファイルを呼び出します。この場合、元の変数がワークスペースに引き続き表示されます。
ファイルの最初の行を強調表示して評価します (
functionという単語は除きます)。右クリックして [コマンド ウィンドウで選択を実行] を選択するか、F9 を押すか、または次のコードをコピーしてコマンド ラインに貼り付けます。[fitresult,gof] = createFit(x,y,z,xv,yv,zv)
この関数は、セッション内で選択した近似の Figure ウィンドウを作成します。曲線フィッター アプリで対話的に作成した曲面と残差の両方のプロットが多項式近似の Figure に表示されることを観察します。
必要に応じて、生成したコードを開始点として、ニーズに合うように曲面近似およびプロットを変更できます。使用できるメソッドの一覧については、
sfitを参照してください。
参照
[1] Franke, Richard. “Scattered Data Interpolation: Tests of Some Methods.” Mathematics of Computation 38, no. 157 (January 1, 1982): 181–200. https://doi.org/10.1090/S0025-5718-1982-0637296-4.