ウェーブレット散乱と深層学習を使用した数字音声認識
この例では、機械学習と深層学習の両方の手法を使用して数字音声を分類する方法を説明します。この例では、ウェーブレット時間散乱をサポート ベクター マシン (SVM) および長短期記憶 (LSTM) ネットワークと組み合わせて分類を行います。また、ベイズ最適化を適用し、LSTM ネットワークの精度向上に適したハイパーパラメーターを判定します。さらに、この例では、深層畳み込みニューラル ネットワーク (CNN) とメル周波数スペクトログラムを用いた手法についても説明します。
データ
Free Spoken Digit データセット (FSDD) をダウンロードします [1]。FSDD には、4 人の話者が英語で発話した 0 ~ 9 の数字が 2000 件記録されています。2 人の話者はアメリカ英語を話すネイティブ スピーカー、1 人の話者はベルギー フランス語なまりの英語を話す非ネイティブ スピーカー、もう 1 人の話者はドイツ語なまりの英語を話す非ネイティブ スピーカーです。データは 8000 Hz でサンプリングされます。
downloadFolder = matlab.internal.examples.downloadSupportFile("audio","FSDD.zip"); dataFolder = tempdir; unzip(downloadFolder,dataFolder) dataset = fullfile(dataFolder,"FSDD");
audioDatastore (Audio Toolbox)を使用してデータ アクセスを管理し、録音が必ず学習セットとテスト セットにランダムに分割されるようにします。データセットを指す audioDatastore を作成します。
ads = audioDatastore(dataset,IncludeSubfolders=true);
補助関数 helpergenLabels は、FSDD ファイルから取得したラベルの categorical 配列を作成します。helpergenLabels のソース コードの一覧を付録に示します。クラスと、各クラスに含まれる例の数をリストします。
ads.Labels = helpergenLabels(ads); summary(ads.Labels)
2000×1 categorical
0 200
1 200
2 200
3 200
4 200
5 200
6 200
7 200
8 200
9 200
<undefined> 0
この FSDD データセットはバランスの取れた 10 個のクラスで構成され、各クラスに 200 個の録音が含まれています。FSDD に含まれる録音はそれぞれ再生時間が異なります。FSDD は膨大ではないため、FSDD のファイルをすべて読み取り、信号長のヒストグラムを作成します。
LenSig = zeros(numel(ads.Files),1); nr = 1; while hasdata(ads) digit = read(ads); LenSig(nr) = numel(digit); nr = nr+1; end reset(ads) histogram(LenSig) grid on xlabel("Signal Length (Samples)") ylabel("Frequency")
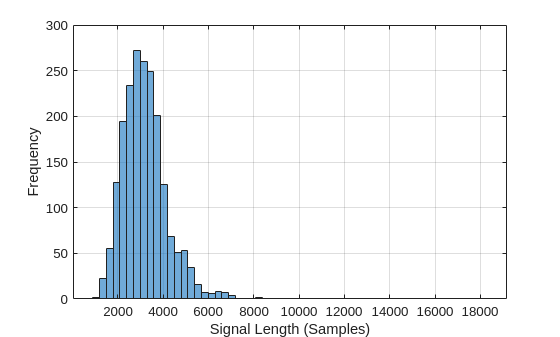
ヒストグラムから、録音の長さの分布に正の歪みがあることがわかります。この例は、分類のために一般的な信号長である 8192 サンプルを使用します。これは、長い録音を打ち切っても発話内容が切断されることのない保守的な値です。信号が 8192 サンプル (1.024 秒) より長い場合、録音は 8192 サンプルに打ち切られます。信号が 8192 サンプルより短い場合、長さを 8192 サンプルにするため、信号の前後が対称的にゼロでパディングされます。
ウェーブレット時間散乱
waveletScattering を使用して、0.22 秒の不変スケールでウェーブレット時間散乱フレームワークを作成します。この例では、すべての時間サンプルについて散乱変換を平均化することで特徴ベクトルを作成します。時間ウィンドウごとの平均化に十分な数の散乱係数を得るため、OversamplingFactor を 2 に設定し、大きくダウンサンプリングされた値に対して各パスの散乱係数の数が 4 倍となるようにします。
sf = waveletScattering(SignalLength=8192,InvarianceScale=0.22, ...
SamplingFrequency=8000,OversamplingFactor=2);FSDD を学習セットとテスト セットに分割します。データの 80% を学習セットに割り当て、20% をテスト セット用に確保します。学習データは、散乱変換に基づいて分類器に学習させるのに使用します。テスト データは、モデルを検証するのに使用します。
rng("default")
ads = shuffle(ads);
[adsTrain,adsTest] = splitEachLabel(ads,0.8);
countEachLabel(adsTrain)ans=10×2 table
0 160
1 160
2 160
3 160
4 160
5 160
6 160
7 160
8 160
9 160
countEachLabel(adsTest)
ans=10×2 table
0 40
1 40
2 40
3 40
4 40
5 40
6 40
7 40
8 40
9 40
補助関数 helperReadSPData は、長さが 8192 となるようにデータを打ち切り (またはパディングし)、各記録データを最大値で正規化します。helperReadSPData のソース コードの一覧を付録に示します。各列に数字音声の録音を格納する 8192 行 1600 列の行列を作成します。
Xtrain = []; scatds_Train = transform(adsTrain,@(x)helperReadSPData(x)); while hasdata(scatds_Train) smat = read(scatds_Train); Xtrain = cat(2,Xtrain,smat); end
テスト セットに対して同じ処理を繰り返します。8192 行 400 列の行列が得られます。
Xtest = []; scatds_Test = transform(adsTest,@(x)helperReadSPData(x)); while hasdata(scatds_Test) smat = read(scatds_Test); Xtest = cat(2,Xtest,smat); end
学習セットとテスト セットにウェーブレット散乱変換を適用します。
Strain = sf.featureMatrix(Xtrain); Stest = sf.featureMatrix(Xtest);
学習セットとテスト セットの平均の散乱特徴を取得します。ゼロ次散乱係数は除外します。
TrainFeatures = Strain(2:end,:,:); TrainFeatures = squeeze(mean(TrainFeatures,2))'; TestFeatures = Stest(2:end,:,:); TestFeatures = squeeze(mean(TestFeatures,2))';
SVM 分類器
データが各記録データの特徴ベクトルに削減されたので、次に、これらの特徴を使用して記録データを分類します。2 次多項式カーネルを使用して、SVM 学習器のテンプレートを作成します。SVM を学習データに適合させます。
template = templateSVM(... KernelFunction="polynomial", ... PolynomialOrder=2, ... KernelScale="auto", ... BoxConstraint=1, ... Standardize=true); classificationSVM = fitcecoc( ... TrainFeatures, ... adsTrain.Labels, ... Learners=template, ... Coding="onevsone", ... ClassNames=categorical({'0'; '1'; '2'; '3'; '4'; '5'; '6'; '7'; '8'; '9'}));
k 分割交差検証を使用して、学習データに基づきモデルの一般化精度を予測します。学習セットを 5 つのグループに分割します。
partitionedModel = crossval(classificationSVM,KFold=5);
[validationPredictions, validationScores] = kfoldPredict(partitionedModel);
validationAccuracy = (1 - kfoldLoss(partitionedModel,LossFun="ClassifError"))*100validationAccuracy = 96.9375
推定された一般化精度は約 97% です。学習済みの SVM を使用して、テスト セットに含まれる数字音声のクラスを予測します。
predLabels = predict(classificationSVM,TestFeatures);
testAccuracy = sum(predLabels==adsTest.Labels)/numel(predLabels)*100 %#ok<NASGU>testAccuracy = 98
テスト セットに対するモデルの性能を混同チャートに集計します。列と行の要約を使用して、各クラスの適合率と再現率を表示します。混同チャートの下部にあるテーブルに、各クラスの精度が示されます。混同チャートの右側にあるテーブルに、再現率が示されます。
figure(Units="normalized",Position=[0.2 0.2 0.5 0.5]) ccscat = confusionchart(adsTest.Labels,predLabels); ccscat.Title = "Wavelet Scattering Classification"; ccscat.ColumnSummary = "column-normalized"; ccscat.RowSummary = "row-normalized";
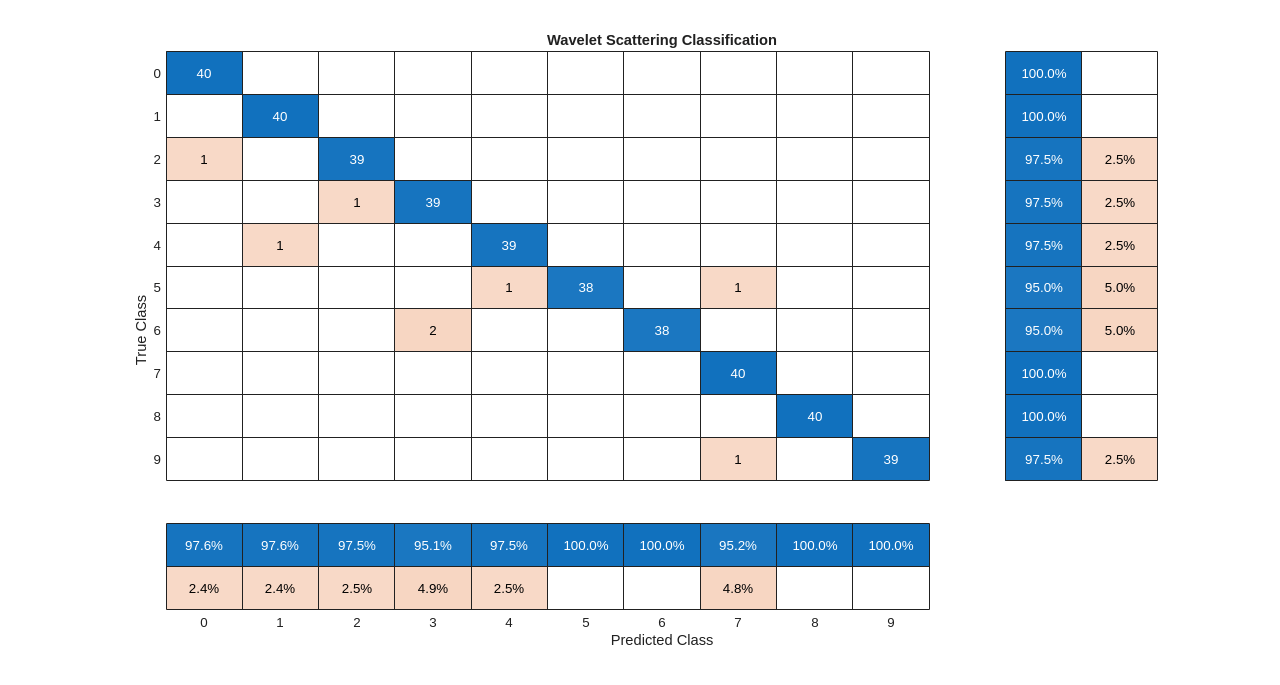
散乱変換と SVM 分類器を組み合わせると、テスト セットに含まれる数字音声が 98% の精度 (または 2% の誤差率) で分類されます。
長短期記憶 (LSTM) ネットワーク
LSTM ネットワークは、再帰型ニューラル ネットワーク (RNN) の一種です。RNN は、音声データのようなシーケンス データまたは時間データの処理に特化したニューラル ネットワークです。ウェーブレット散乱係数はシーケンスなので、LSTM の入力として使用できます。生データではなく散乱特徴を使用することで、ネットワークが学習すべき変動性を減らすことができます。
LSTM ネットワークで使用できるように、学習用およびテスト用の散乱特徴に変更を加えます。ゼロ次散乱係数は除外し、特徴を cell 配列に変換します。
TrainFeatures = Strain(2:end,:,:); TrainFeatures = squeeze(num2cell(TrainFeatures,[1 2])); TestFeatures = Stest(2:end,:,:); TestFeatures = squeeze(num2cell(TestFeatures, [1 2]));
256 個の隠れ層を使用して、単純な LSTM ネットワークを構築します。
[inputSize, ~] = size(TrainFeatures{1});
YTrain = adsTrain.Labels;
numHiddenUnits = 256;
numClasses = numel(unique(YTrain));
layers = [ ...
sequenceInputLayer(inputSize)
lstmLayer(numHiddenUnits,OutputMode="last")
fullyConnectedLayer(numClasses)
softmaxLayer];ハイパーパラメーターを設定します。Adam 最適化を使用し、ミニバッチ サイズとして 50 を使用します。エポックの最大回数に 300 を設定します。学習率として 1e-4 を使用します。プロットを使用して学習の進行状況を追跡しない場合は、学習の進行状況プロットをオフにして構いません。使用可能な場合、学習には GPU が既定で使用されます。そうでない場合は CPU が使用されます。詳細については、trainingOptions (Deep Learning Toolbox)を参照してください。
maxEpochs = 300; miniBatchSize = 50; options = trainingOptions("adam", ... InitialLearnRate=1e-4,... MaxEpochs=maxEpochs, ... MiniBatchSize=miniBatchSize, ... SequenceLength="shortest", ... Shuffle="every-epoch",... Verbose=false, ... Plots="training-progress", ... Metrics="accuracy", ... InputDataFormats="CTB");
ネットワークに学習をさせます。
net = trainnet(TrainFeatures,YTrain,layers,"crossentropy",options);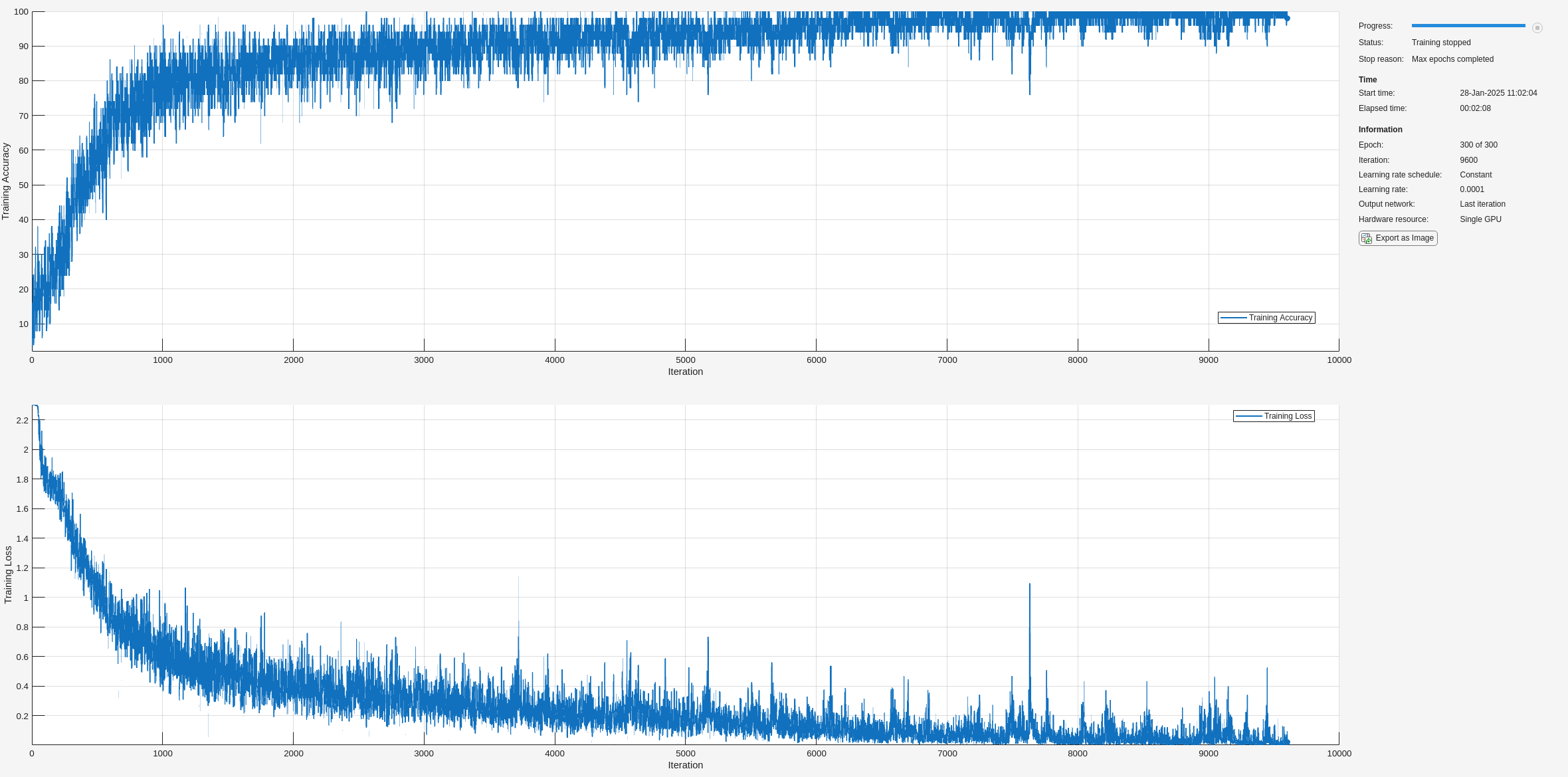
scores = minibatchpredict(net,TestFeatures,InputDataFormats="CTB"); classNames = categories(ads.Labels); predLabels = scores2label(scores,classNames); testAccuracy = sum(predLabels==adsTest.Labels)/numel(predLabels)*100 %#ok<NASGU>
testAccuracy = 93.7500
ベイズ最適化
一般に、ハイパーパラメーターの適切な設定は、深層ネットワークの学習において最も難しい作業の 1 つです。ベイズ最適化を使用すると、これを軽減できます。この例では、ベイズ法を使用して隠れ層の数と初期学習率を最適化します。ハイパーパラメーターの設定とネットワークに関する情報、および対応する誤差率を格納する MAT ファイルを保存するための新しいディレクトリを作成します。
YTrain = adsTrain.Labels; YTest = adsTest.Labels; if ~exist("results/",'dir') mkdir results end
最適化する変数とその値の範囲を初期化します。隠れ層の数は整数でなければならないため、'type' を 'integer' に設定します。
optVars = [
optimizableVariable(InitialLearnRate=[1e-5, 1e-2],Transform="log")
optimizableVariable(NumHiddenUnits=[100, 1000],Type="integer")
];ベイズ最適化は計算量が多く、完了するまで数時間かかる場合があります。この例では、optimizeCondition を false に設定し、事前に定義された最適化済みのハイパーパラメーター設定をダウンロードして使用します。optimizeCondition を true に設定すると、目的関数 helperBayesOptLSTM はベイズ最適化を使用して最小化されます。付録にリストされているこの目的関数は、特定のハイパーパラメーター設定が与えられたときのネットワークの誤差率を表します。読み込まれる設定では、目的関数の最小値が 0.02 (誤差率 2%) になります。
ObjFcn = helperBayesOptLSTM(TrainFeatures,YTrain,TestFeatures,YTest); optimizeCondition = false; if optimizeCondition BayesObject = bayesopt(ObjFcn,optVars, ... MaxObjectiveEvaluations=15, ... IsObjectiveDeterministic=false, ... UseParallel=false); %#ok<UNRCH> else url = "http://ssd.mathworks.com/supportfiles/audio/SpokenDigitRecognition.zip"; downloadNetFolder = tempdir; netFolder = fullfile(downloadNetFolder,"SpokenDigitRecognition"); if ~exist(netFolder,"dir") disp("Downloading pretrained network (1 file - 12 MB) ...") unzip(url,downloadNetFolder) end file = load(fullfile(netFolder,"0.02.mat")); end
ベイズ最適化を実行すると、目的関数の値と対応するハイパーパラメーターの値および反復回数を追跡するために、次のような図が生成されます。ベイズ最適化の反復回数を増やすと、目的関数の大域的最小値に確実に到達できます。
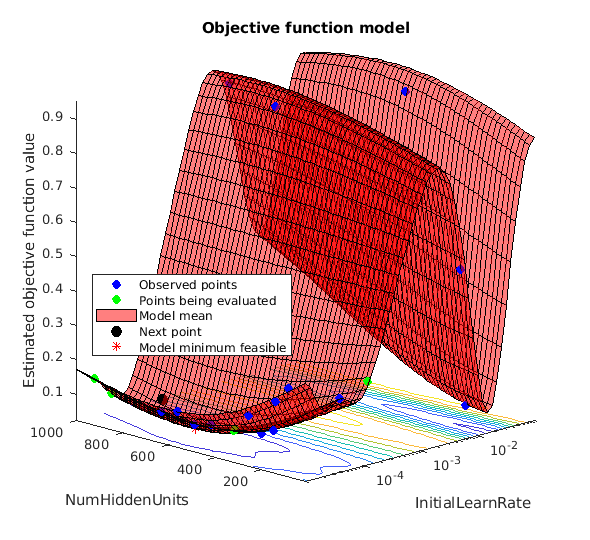

隠れユニットの数と初期学習率に最適化された値を適用し、ネットワークに再学習させます。
bestNumHiddenUnits = 768; bestInitialLearnRate = 2.198827960269379e-04; numClasses = numel(unique(YTrain)); layers = [ ... sequenceInputLayer(inputSize) lstmLayer(bestNumHiddenUnits,OutputMode="last") fullyConnectedLayer(numClasses) softmaxLayer]; maxEpochs = 300; miniBatchSize = 50; options = trainingOptions("adam", ... InitialLearnRate=bestInitialLearnRate, ... MaxEpochs=maxEpochs, ... MiniBatchSize=miniBatchSize, ... SequenceLength="shortest", ... Shuffle="every-epoch", ... Verbose=false, ... Plots="training-progress", ... Metrics="accuracy", ... InputDataFormats="CTB"); net = trainnet(TrainFeatures,YTrain,layers,"crossentropy",options);

scores = minibatchpredict(net,TestFeatures,InputDataFormats="CTB");
classNames = categories(ads.Labels);
predLabels = scores2label(scores,classNames);
testAccuracy = sum(predLabels==adsTest.Labels)/numel(predLabels)*100 testAccuracy = 97.5000
このプロットからわかるように、ベイズ最適化によって LSTM の精度が向上します。
メル周波数スペクトログラムを使用した深層畳み込みネットワーク
数字音声認識のタスクを処理するもう 1 つのアプローチとして、メル周波数スペクトログラムに基づく深層畳み込みニューラル ネットワーク (DCNN) を使用して FSDD データセットを分類する方法があります。散乱変換の場合と同じ手順で信号の切り捨てやパディングを行います。同様に、各信号サンプルを最大絶対値で除算して、各録音を正規化します。一貫性を持たせるため、散乱変換の場合と同じ学習セットとテスト セットを使用します。
メル周波数スペクトログラムのパラメーターを設定します。ウィンドウ (フレーム) の持続時間には、散乱変換の場合と同じ0.22 秒を使用します。ウィンドウ間のホップを 10 ms に設定します。周波数帯域の数として 40 を使用します。
segmentDuration = 8192*(1/8000); frameDuration = 0.22; hopDuration = 0.01; numBands = 40;
学習データストアとテスト データストアをリセットします。
reset(adsTrain) reset(adsTest)
この例の最後で定義されている補助関数 helperspeechSpectrograms は、録音の長さを標準化し、振幅を正規化した後に、melSpectrogram (Audio Toolbox)を使用してメル周波数スペクトログラムを取得します。メル周波数スペクトログラムの対数を DCNN への入力として使用します。ゼロの対数をとることのないよう、各要素に小さいイプシロンを追加します。
epsil = 1e-6; XTrain = helperspeechSpectrograms(adsTrain,segmentDuration,frameDuration,hopDuration,numBands);
Computing speech spectrograms... Processed 500 files out of 1600 Processed 1000 files out of 1600 Processed 1500 files out of 1600 ...done
XTrain = log10(XTrain + epsil); XTest = helperspeechSpectrograms(adsTest,segmentDuration,frameDuration,hopDuration,numBands);
Computing speech spectrograms... ...done
XTest = log10(XTest + epsil); YTrain = adsTrain.Labels; YTest = adsTest.Labels;
DCNN アーキテクチャの定義
小さい DCNN を層の配列として構築します。畳み込み層とバッチ正規化層を使用します。また、最大プーリング層を使って特徴マップをダウンサンプリングします。ネットワークが学習データの特定の特徴を記憶する可能性を減らすために、最後の全結合層への入力に少量のドロップアウトを追加します。
sz = size(XTrain);
specSize = sz(1:2);
imageSize = [specSize 1];
numClasses = numel(categories(YTrain));
dropoutProb = 0.2;
numF = 12;
layers = [
imageInputLayer(imageSize)
convolution2dLayer(5,numF,Padding="same")
batchNormalizationLayer
reluLayer
maxPooling2dLayer(3,Stride=2,Padding="same")
convolution2dLayer(3,2*numF,Padding="same")
batchNormalizationLayer
reluLayer
maxPooling2dLayer(3,Stride=2,Padding="same")
convolution2dLayer(3,4*numF,Padding="same")
batchNormalizationLayer
reluLayer
maxPooling2dLayer(3,Stride=2,Padding="same")
convolution2dLayer(3,4*numF,Padding="same")
batchNormalizationLayer
reluLayer
convolution2dLayer(3,4*numF,Padding="same")
batchNormalizationLayer
reluLayer
maxPooling2dLayer(2)
dropoutLayer(dropoutProb)
fullyConnectedLayer(numClasses)
softmaxLayer
];ネットワークの学習に使用するハイパーパラメーターを設定します。ミニバッチ サイズとして 50 を使用し、学習率として 1e-4 を使用します。Adam 最適化を指定します。実行環境を "gpu" または "auto" に設定することで、使用可能な GPU 上でネットワークに学習させることができます。詳細については、trainingOptions (Deep Learning Toolbox)を参照してください。
miniBatchSize = 50; options = trainingOptions("adam", ... InitialLearnRate=1e-4, ... MaxEpochs=30, ... MiniBatchSize=miniBatchSize, ... Shuffle="every-epoch", ... Plots="training-progress", ... Verbose=false, ... Metrics="accuracy", ... ExecutionEnvironment="auto");
ネットワークに学習をさせます。
trainedNet = trainnet(XTrain,YTrain,layers,"crossentropy",options);
学習済みのネットワークを使用して、テスト セットに含まれる数字ラベルを予測します。
scores = minibatchpredict(trainedNet,XTest); classNames = categories(YTrain); Ypredicted = scores2label(scores,classNames); cnnAccuracy = sum(Ypredicted==YTest)/numel(YTest)*100
cnnAccuracy = 98.7500
テスト セットに対する学習済みのネットワークのパフォーマンスを混同チャートに要約します。列と行の要約を使用して、各クラスの適合率と再現率を表示します。混同チャートの下にあるテーブルに、精度が示されます。混同チャートの右側にあるテーブルに、再現率が示されます。
figure(Units="normalized",Position=[0.2 0.2 0.5 0.5]); ccDCNN = confusionchart(YTest,Ypredicted); ccDCNN.Title = "Confusion Chart for DCNN"; ccDCNN.ColumnSummary = "column-normalized"; ccDCNN.RowSummary = "row-normalized";

メル周波数スペクトログラムを入力として使用する DCNN の場合も、テスト セットに含まれる数字音声が約 98% の精度で分類されています。
まとめ
この例では、機械学習と深層学習に関するさまざまな手法を使用して、FSDD に含まれる数字音声を分類する方法を示しました。ここではウェーブレット散乱を SVM および LSTM の両方と組み合わせる方法について説明しました。ベイズ法を使用して LSTM のハイパーパラメーターを最適化しました。最後に、CNN とメル周波数スペクトログラムを組み合わせて使用する方法を説明しました。
この例の目的は、基本的には異なるものの、相互に補完する手法で問題に取り組むために、MathWorks® のツールをどのように使用するかを示すことです。どのワークフローでも audioDatastore を使用してディスクからのデータの流れを管理し、データを確実にランダム化します。
この例で使用されている手法は、どれもテスト セットに対して同程度に良好な性能を示しています。この例は各種の手法を直接比較することを意図したものではありません。たとえば、CNN のハイパーパラメーターの選択にベイズ最適化を使用することもできます。このバージョンの FSDD のように小さな学習セットを使用した深層学習に役立つもう 1 つの手法として、データ拡張があります。データの操作がクラスにどのように影響するかは必ずしも明らかではないため、データの拡張が不可能な場合もあります。ただし、音声の場合は、audioDataAugmenter (Audio Toolbox)を使用したデータ拡張の手法が確立されています。
ウェーブレット時間散乱の場合も、さまざまな変更を試すことができます。たとえば、変換の不変スケールを変更したり、フィルター バンクごとのウェーブレット フィルターの数を変更したり、各種の分類器を試してみることができます。
付録: 補助関数
function Labels = helpergenLabels(ads) % This function is only for use in Wavelet Toolbox examples. It may be % changed or removed in a future release. tmp = cell(numel(ads.Files),1); expression = "[0-9]+_"; for nf = 1:numel(ads.Files) idx = regexp(ads.Files{nf},expression); tmp{nf} = ads.Files{nf}(idx); end Labels = categorical(tmp); end
function x = helperReadSPData(x) % This function is only for use Wavelet Toolbox examples. It may change or % be removed in a future release. N = numel(x); if N > 8192 x = x(1:8192); elseif N < 8192 pad = 8192-N; prepad = floor(pad/2); postpad = ceil(pad/2); x = [zeros(prepad,1) ; x ; zeros(postpad,1)]; end x = x./max(abs(x)); end
function x = helperBayesOptLSTM(X_train, Y_train, X_val, Y_val) % This function is only for use in the % "Spoken Digit Recognition with Wavelet Scattering and Deep Learning" % example. It may change or be removed in a future release. x = @valErrorFun; function [valError,cons, fileName] = valErrorFun(optVars) %% LSTM Architecture [inputSize,~] = size(X_train{1}); numClasses = numel(unique(Y_train)); layers = [ ... sequenceInputLayer(inputSize) bilstmLayer(optVars.NumHiddenUnits,OutputMode="last") % Using number of hidden layers value from optimizing variable fullyConnectedLayer(numClasses) softmaxLayer]; % Plots not displayed during training options = trainingOptions("adam", ... InitialLearnRate=optVars.InitialLearnRate, ... % Using initial learning rate value from optimizing variable MaxEpochs=300, ... MiniBatchSize=30, ... SequenceLength="shortest", ... Shuffle="every-epoch", ... Verbose=false, ... Metrics="accuracy", ... InputDataFormats="CTB"); %% Train the network net = trainnet(X_train, Y_train, layers, "crossentropy", options); %% Training accuracy scores = minibatchpredict(net,X_val,InputDataFormats="CTB"); classNames = categories(Y_train); X_val_P = scores2label(scores,classNames); accuracy_training = sum(X_val_P == Y_val)./numel(Y_val); valError = 1 - accuracy_training; %% save results of network and options in a MAT file in the results folder along with the error value fileName = fullfile("results", num2str(valError) + ".mat"); save(fileName,"net","valError","options") cons = []; end % end for inner function end % end for outer function
function X = helperspeechSpectrograms(ads,segmentDuration,frameDuration,hopDuration,numBands) % This function is only for use in the % "Spoken Digit Recognition with Wavelet Scattering and Deep Learning" % example. It may change or be removed in a future release. % % helperspeechSpectrograms(ads,segmentDuration,frameDuration,hopDuration,numBands) % computes speech spectrograms for the files in the datastore ads. % segmentDuration is the total duration of the speech clips (in seconds), % frameDuration the duration of each spectrogram frame, hopDuration the % time shift between each spectrogram frame, and numBands the number of % frequency bands. disp("Computing speech spectrograms..."); numHops = ceil((segmentDuration - frameDuration)/hopDuration); numFiles = length(ads.Files); X = zeros([numBands,numHops,1,numFiles],"single"); for i = 1:numFiles [x,info] = read(ads); x = normalizeAndResize(x); fs = info.SampleRate; frameLength = round(frameDuration*fs); hopLength = round(hopDuration*fs); spec = melSpectrogram(x,fs, ... Window=hamming(frameLength,"periodic"), ... OverlapLength=frameLength-hopLength, ... FFTLength=2048, ... NumBands=numBands, ... FrequencyRange=[50,4000]); % If the spectrogram is less wide than numHops, then put spectrogram in % the middle of X. w = size(spec,2); left = floor((numHops-w)/2)+1; ind = left:left+w-1; X(:,ind,1,i) = spec; if mod(i,500) == 0 disp("Processed " + i + " files out of " + numFiles) end end disp("...done"); end %-------------------------------------------------------------------------- function x = normalizeAndResize(x) % This function is only for use in the % "Spoken Digit Recognition with Wavelet Scattering and Deep Learning" % example. It may change or be removed in a future release. N = numel(x); if N > 8192 x = x(1:8192); elseif N < 8192 pad = 8192-N; prepad = floor(pad/2); postpad = ceil(pad/2); x = [zeros(prepad,1) ; x ; zeros(postpad,1)]; end x = x./max(abs(x)); end
参考文献
[1] Jakobovski. “Jakobovski/Free-Spoken-Digit-Dataset.” GitHub, May 30, 2019. https://github.com/Jakobovski/free-spoken-digit-dataset.
Copyright 2018-2025, The MathWorks, Inc.
参考
オブジェクト
waveletScattering|audioDatastore(Audio Toolbox) |audioDataAugmenter(Audio Toolbox)
関数
featureMatrix|melSpectrogram(Audio Toolbox)