トピック モデリング入門
この例では、トピック モデルをテキスト データに当てはめて、トピックを可視化する方法を示します。
潜在的ディリクレ配分 (LDA) モデルは、文書のコレクションに内在するトピックを発見するトピック モデルです。単語の分布によって特徴付けられるトピックは、共通して共起する単語のグループに対応します。LDA は教師なしトピック モデルです。これは、ラベル付きデータを必要としないことを意味します。
テキスト データの読み込みと抽出
サンプル データを読み込みます。ファイル factoryReports.csv には、各イベントの説明テキストとカテゴリカル ラベルを含む工場レポートが格納されています。
関数 readtable を使用してデータをインポートし、Description 列からテキスト データを抽出します。
filename = "factoryReports.csv"; data = readtable(filename,'TextType','string'); textData = data.Description;
解析用のテキスト データの準備
テキスト データをトークン化して前処理し、bag-of-words モデルを作成します。
テキストをトークン化します。
documents = tokenizedDocument(textData);
モデルの当てはめを改善するには、句読点とストップ ワード ("and"、"of"、"the" などの単語) を文書から削除します。
documents = removeStopWords(documents); documents = erasePunctuation(documents);
bag-of-words モデルを作成します。
bag = bagOfWords(documents);
LDA モデルを当てはめる
関数 fitlda を使用して、トピック数 7 の LDA モデルを当てはめます。詳細出力を抑制するには、'Verbose' オプションを 0 に設定します。
numTopics = 7;
mdl = fitlda(bag,numTopics,'Verbose',0);トピックの可視化
ワード クラウドを使用して、最初の 4 つのトピックを可視化します。
figure for topicIdx = 1:4 subplot(2,2,topicIdx) wordcloud(mdl,topicIdx); title("Topic " + topicIdx) end
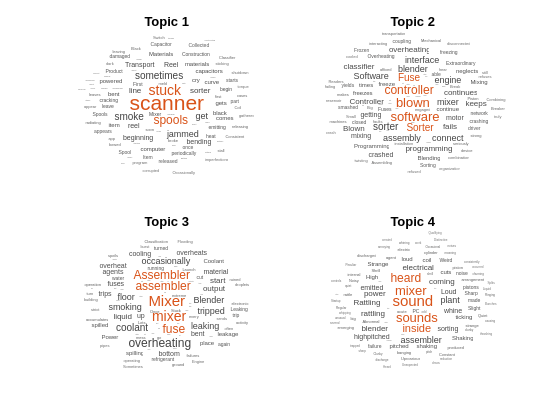
テキスト解析の次のステップとして、さまざまな前処理ステップを使用してトピックの混合を可視化し、モデルの当てはめを改善できます。例については、トピック モデルを使用したテキスト データの解析を参照してください。
参考
removeStopWords | tokenizedDocument | erasePunctuation | bagOfWords | fitlda | wordcloud