単純な前処理関数の作成
この例では、[テキスト データの前処理] ライブ エディター タスクを使用して、解析のためにテキスト データをクリーニングおよび前処理する関数を作成する方法を示します。
テキスト データは大きくなる可能性があり、統計解析に悪影響を与える多くのノイズが含まれる可能性があります。たとえば、テキスト データには次のような内容が含まれます。
大文字と小文字のバリエーション (たとえば "new" と "New")
語形のバリエーション (たとえば "walk" と "walking")
ノイズを付加する単語 (たとえば "the" や "of" などの "ストップ ワード")
句読点と特殊文字
HTML および XML のタグ
次のワード クラウドは、工場レポートの生テキスト データに適用された単語頻度解析と、同じテキスト データの前処理済みバージョンに適用された単語頻度解析を示しています。

ほとんどのワークフローでは、さまざまなテキスト データのコレクションを同じ方法で簡単に準備するための前処理関数が必要です。たとえば、モデルに学習させる際、同じ手順を使用して学習データと新しいデータを前処理するために、同じ関数を使用できます。
[テキスト データの前処理] ライブ エディター タスクを使用して、テキスト データを対話形式で前処理し、結果を可視化することができます。この例では、[テキスト データの前処理] ライブ エディター タスクを使用して、テキスト データの前処理および再利用可能な関数の作成を行うコードを生成します。ライブ エディター タスクの詳細については、ライブ スクリプトへの対話型タスクの追加を参照してください。
まず、工場レポート データを読み込みます。データには、工場の障害イベントを説明するテキストが含まれています。
tbl = readtable("factoryReports.csv")
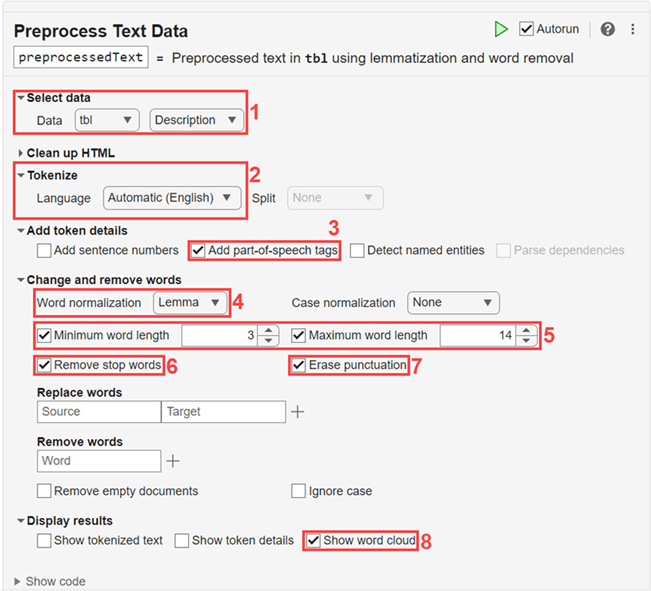
[テキスト データの前処理] ライブ エディター タスクを開きます。タスクを開くには、まずタスク名を入力し、提案されたコマンドの補完候補から [テキスト データの前処理] を選択します。または、[ライブ エディター] タブで、[タスク] 、 [テキスト データの前処理] を選択します。

以下のオプションを使用してテキストを前処理します。
入力データとして
tblを選択し、table 変数Descriptionを選択します。自動言語検出を使用してテキストをトークン化します。
レンマ化を改善するには、トークンの詳細に品詞タグを追加します。
レンマ化を使用して単語を正規化します。
3 文字未満または 14 文字を超える単語を削除します。
ストップ ワードを削除します。
句読点を消去します。
前処理されたテキストをワード クラウドで表示します。

[テキスト データの前処理] ライブ エディター タスクは、ライブ スクリプトでコードを生成します。生成されたコードには、選択したオプションが反映され、表示を生成するためのコードが含まれています。生成されたコードを表示するには、タスク パラメーター領域の下部にある [コードの表示] をクリックします。タスクが展開され、生成されたコードが表示されます。
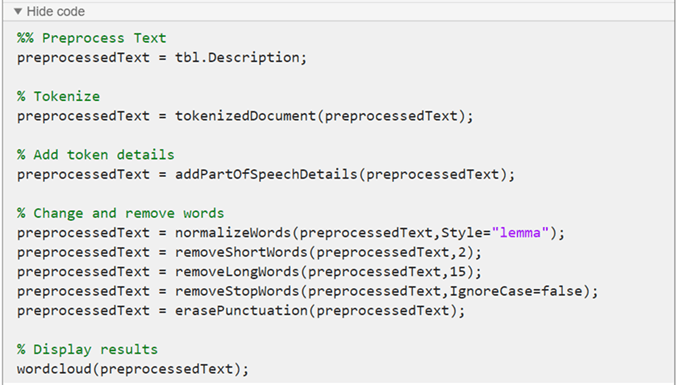
既定では、生成されたコードは MATLAB® ワークスペースに返される出力変数の名前として preprocessedText を使用します。別の出力変数名を指定するには、タスクの最上部にある要約行に新しい名前を入力します。

コードで同じ手順を再利用するには、テキスト データを入力として受け取り、前処理されたテキスト データを出力する関数を作成します。この関数は、スクリプトの最後に含めることも、別のファイルとして含めることもできます。例の最後にリストされている関数 preprocessTextData は、[テキスト データの前処理] ライブ エディター タスクによって生成されたコードを使用します。
この関数を使用するには、table を関数 preprocessTextData への入力として指定します。
documents = preprocessTextData(tbl);
前処理関数
関数 preprocessTextData は、[テキスト データの前処理] ライブ エディター タスクによって生成されたコードを使用します。この関数は、table tbl を入力として受け取り、前処理されたテキスト preprocessedText を返します。この関数は、以下の手順を実行します。
入力 table の変数
Descriptionからテキスト データを抽出する。tokenizedDocumentを使用してテキストをトークン化する。addPartOfSpeechDetailsを使用して品詞の詳細を追加する。normalizeWordsを使用して単語をレンマ化する。removeShortWordsを使用して、2 文字以下の単語を削除する。removeLongWordsを使用して、15 文字以上の単語を削除する。removeStopWordsを使用して、ストップ ワード ("and"、"of"、"the" など) を削除する。erasePunctuationを使用して句読点を消去する。
function preprocessedText = preprocessTextData(tbl) %% Preprocess Text preprocessedText = tbl.Description; % Tokenize preprocessedText = tokenizedDocument(preprocessedText); % Add token details preprocessedText = addPartOfSpeechDetails(preprocessedText); % Change and remove words preprocessedText = normalizeWords(preprocessedText,Style="lemma"); preprocessedText = removeShortWords(preprocessedText,2); preprocessedText = removeLongWords(preprocessedText,15); preprocessedText = removeStopWords(preprocessedText,IgnoreCase=false); preprocessedText = erasePunctuation(preprocessedText); end
より詳細なワークフローを示す例については、Preprocess Text Data in Live Editorを参照してください。テキスト解析の次のステップとして、分類モデルの作成を試すか、トピック モデルを使用してデータを解析できます。例については、分類用の単純なテキスト モデルの作成とトピック モデルを使用したテキスト データの解析を参照してください。
参考
テキスト データの前処理 | tokenizedDocument | erasePunctuation | removeStopWords | removeShortWords | removeLongWords | normalizeWords | addPartOfSpeechDetails