Train Kernel Approximation Classifiers Using Classification Learner App
This example shows how to create and compare kernel approximation classifiers in the Classification Learner app, and export trained models to the workspace to make predictions for new data. You can use kernel approximation classifiers to perform nonlinear classification of data with many observations. For large in-memory data, kernel classifiers tend to train and predict faster than SVM classifiers with Gaussian kernels.
In the MATLAB® Command Window, load the
humanactivitydata set, and create a table from the variables in the data set to use for classification. The data set contains 24,075 observations of five physical human activities: sitting, standing, walking, running, and dancing. Each observation has 60 features extracted from acceleration data measured by smartphone accelerometer sensors.load humanactivity Tbl = array2table(feat); Tbl.Properties.VariableNames = featlabels'; activity = categorical(actid,1:5,actnames); Tbl.Activity = activity;Alternatively, you can load the
humanactivitydata set, create the categoricalactivityresponse variable, and keep thefeatandactivitydata as separate variables.Click the Apps tab, and then click the Show more arrow on the right to open the apps gallery. In the Machine Learning and Deep Learning group, click Classification Learner.
On the Learn tab, in the File section, click New Session and select From Workspace.

In the New Session from Workspace dialog box, select the table
Tblfrom the Data Set Variable list. Note that the app selects response and predictor variables based on their data types. In particular, the app selectsActivityas the response variable because it is the only categorical variable. For this example, do not change the selections.Alternatively, if you keep the predictor data
featand response variableactivityas two separate variables, you can first select the matrixfeatfrom the Data Set Variable list. Then, under Response, click the From workspace option button and selectactivityfrom the list.To accept the default validation scheme and continue, click Start Session. The default validation option is 5-fold cross-validation, to protect against overfitting.
Classification Learner creates a scatter plot of the data.
Use the scatter plot to investigate which variables are useful for predicting the response. Select different options in the X and Y lists under Predictors to visualize the distribution of activities and measurements. Note which variables separate the activities (colors) most clearly.
Create a selection of kernel approximation models. On the Learn tab, in the Models section, click the arrow to open the gallery. In the Kernel Approximation Classifiers group, click All Kernels.
In the Train section, click Train All and select Train All.
Note
If you have Parallel Computing Toolbox™, then the Use Parallel button is selected by default. After you click Train All and select Train All or Train Selected, the app opens a parallel pool of workers. During this time, you cannot interact with the software. After the pool opens, you can continue to interact with the app while models train in parallel.
If you do not have Parallel Computing Toolbox, then the Use Background Training check box in the Train All menu is selected by default. After you select an option to train models, the app opens a background pool. After the pool opens, you can continue to interact with the app while models train in the background.
Classification Learner trains one of each kernel approximation option in the gallery, as well as the default fine tree model. In the Models pane, the app outlines the Accuracy (Validation) score of the best model. Classification Learner also displays a validation confusion matrix for the first kernel model (SVM Kernel).
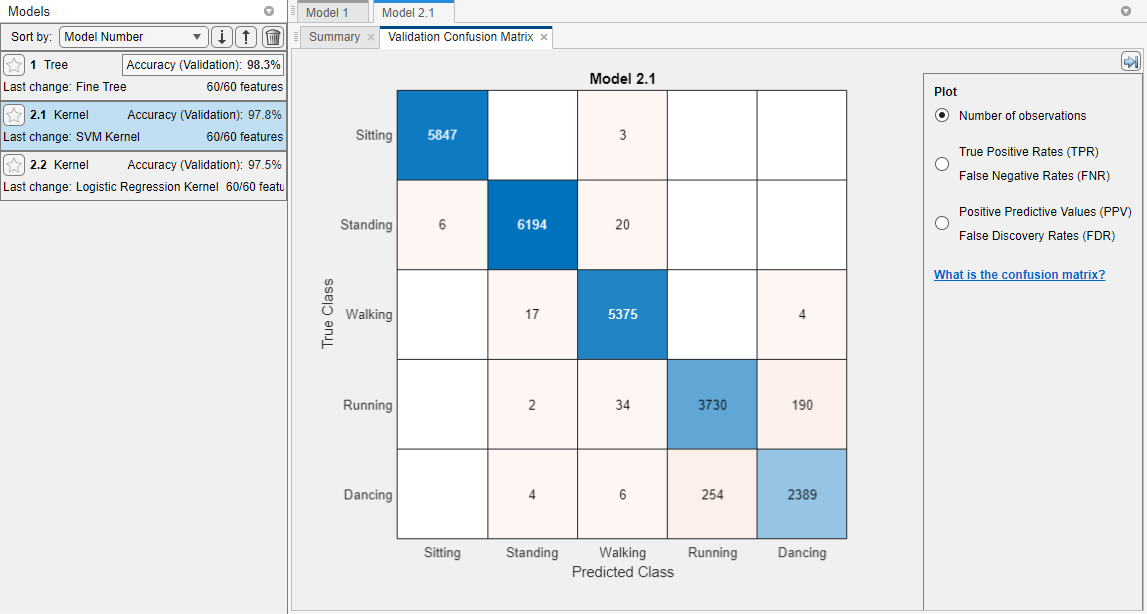
Note
Validation introduces some randomness into the results. Your model validation results can vary from the results shown in this example.
To view the results for a model, double-click the model in the Models pane, and inspect the model Summary tab. The Summary tab displays the Training Results and Additional Training Results metrics, calculated on the validation set.
Select the second kernel model (Logistic Regression Kernel) in the Models pane, and inspect the accuracy of the predictions in each class using a validation confusion matrix. On the Learn tab, in the Plots and Results section, click the arrow to open the gallery, and then click Confusion Matrix (Validation) in the Validation Results group. View the matrix of true class and predicted class results.
Compare the confusion matrices for the two kernel models side-by-side. First, close the plot and summary tabs for Model 1. On the Learn tab, in the Plots and Results section, click the Layout button and select Compare models. In the top right of each plot, click the Hide plot options button
 to make more room for the plot.
to make more room for the plot.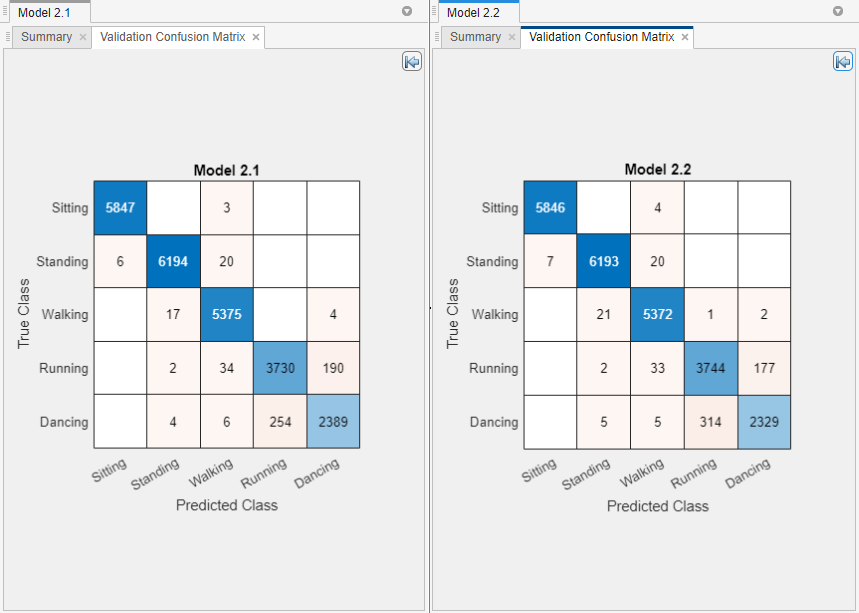
To return to the original layout, you can click the Layout button and select Single model (Default).
Choose the best kernel model in the Models pane (the best overall score is highlighted in the Accuracy (Validation) box). See if you can improve the model by removing features with low predictive power.
First, duplicate the best kernel model by right-clicking the model and selecting Duplicate.
Investigate features to include or exclude using one of these methods.
Use the parallel coordinates plot. On the Learn tab, in the Plots and Results section, click the arrow to open the gallery, and then click Parallel Coordinates in the Validation Results group. Keep predictors that separate classes well.
In the model Summary tab, you can specify the predictors to use during training. Click Feature Selection to expand the section, and specify predictors to remove from the model.
Use a feature ranking algorithm. On the Learn tab, in the Options section, click Feature Selection. In the Default Feature Selection tab, specify the feature ranking algorithm you want to use, and the number of features to keep among the highest ranked features. The bar graph can help you decide how many features to use.
Click Save and Apply to save your changes. The new feature selection is applied to the existing draft model in the Models pane and will be applied to new draft models that you create using the gallery in the Models section of the Learn tab.
Train the model. On the Learn tab, in the Train section, click Train All and select Train Selected to train the model using the new options. Compare results among the classifiers in the Models pane.
Choose the best kernel model in the Models pane. To try to improve the model further, change its hyperparameters. First, duplicate the model by right-clicking the model and selecting Duplicate. Then, try changing some hyperparameter settings in the model Summary tab. Train the new model by clicking Train All and selecting Train Selected in the Train section.
To learn more about kernel model settings, see Kernel Approximation Classifiers.
You can export a compact version of the trained model to the workspace. In the Export section of the Learn tab, click Export Model and select Export Model. In the Export Classification Model dialog box, the check box to include the training data is disabled because kernel approximation models do not store training data. In the dialog box, click OK to accept the default variable name.
To examine the code for training this classifier, on the Learn tab, in the Export section, click Export Model and select Generate Function. Because the data set used to train this classifier has more than two classes, the generated code uses the
fitcecocfunction rather thanfitckernel.
Tip
Use the same workflow to evaluate and compare the other classifier types you can train in Classification Learner.
To train all the nonoptimizable classifier model presets available for your data set:
On the Learn tab, in the Models section, click the arrow to open the gallery of classification models.
In the Get Started group, click All.

In the Train section, click Train All and select Train All.
To learn about other classifier types, see Train Classification Models in Classification Learner App.
Related Topics
- Train Classification Models in Classification Learner App
- Select Data for Classification or Open Saved App Session
- Choose Classifier Options
- Feature Selection and Feature Transformation Using Classification Learner App
- Visualize and Assess Classifier Performance in Classification Learner
- Export Classification Model to Predict New Data
- Train Decision Trees Using Classification Learner App
Select a Web Site
Choose a web site to get translated content where available and see local events and offers. Based on your location, we recommend that you select: United States.
You can also select a web site from the following list
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)
Asia Pacific
- Australia (English)
- India (English)
- New Zealand (English)
- 中国
- 日本Japanese (日本語)
- 한국Korean (한국어)