tall 配列の使用によるビッグ データの統計および機械学習
この例では、メモリ不足になるデータに対して MATLAB® と Statistics and Machine Learning Toolbox™ で統計解析と機械学習を実行する方法を示します。
tall 配列および tall table は、メモリ不足になるデータを処理するように設計されています。このタイプのデータは、少数の列 (変数) に対して非常に多くの数の行 (観測値) から構成されています。MapReduce のようにデータの巨大なサイズを考慮する特殊なコードを記述する代わりに、tall 配列を使用して、インメモリの MATLAB 配列に似た方法で大規模なデータ セットを処理できます。基本的な違いは、tall 配列は通常、計算の実行要求があるまで評価されない、という点です。
tall 配列に対する計算を実行する場合、MATLAB® は並列プール (Parallel Computing Toolbox™ がある場合は既定) またはローカルの MATLAB セッションを使用します。Parallel Computing Toolbox がある場合にローカルの MATLAB セッションを使用して例を実行するには、関数 mapreducer を使用してグローバルな実行環境を変更します。
mapreducer(0)
この例では、単一のコンピューターでデータのサブセットを処理して線形回帰モデルを作成してから、データ セット全体を分析するように拡張します。この分析は、次にも拡張できます。
メモリに読み込めないデータの処理
MATLAB Parallel Server™ の使用によるクラスター間分散されたデータの処理
Hadoop® や Spark® などのビッグ データ システムとの統合
tall 配列を使用する機械学習について
Statistics and Machine Learning Toolbox の教師なしおよび教師あり学習アルゴリズムのいくつかは tall 配列を扱う処理に利用可能であり、メモリ不足になるデータについてデータ マイニングや予測モデリングを実行します。これらのアルゴリズムは、メモリ不足になるデータに適しており、インメモリ アルゴリズムとわずかに異なる場合があります。機能には以下があります。
k-means クラスタリング
線形回帰
一般化線形回帰
ロジスティック回帰
判別分析
MATLAB では、メモリ不足になるデータに対する機械学習ワークフローはインメモリ データの場合と似ています。
前処理
調査
モデルの開発
モデルの検証
より大きいデータへの拡張
この例では、飛行機の遅れに対する予測モデルの開発と同様の構造に従います。このデータには、1987 ~ 2008 年における飛行機のフライト情報に関する大規模なファイルが含まれています。この例の目標は、いくつかの変数に基づいて出発の遅れを予測することです。
tall 配列の基本的な側面に関する詳細は、tall 配列を使用した MATLAB でのビッグ データの解析の例に含まれています。この例では、tall 配列配列を使用する機械学習を含めるように分析を拡張します。
飛行機データの tall table の作成
データストアとは、大きすぎてメモリに収まらないデータの集合を格納するリポジトリです。外部のデータ ソースから tall 配列を作成する 1 番目のステップとして、いくつかの異なるファイル形式からデータストアを作成できます。
サンプル ファイル airlinesmall.csv のデータストアを作成します。対象とする変数を選択し、'NA' 値を欠損データとして扱い、データのプレビュー テーブルを生成します。
ds = datastore('airlinesmall.csv'); ds.SelectedVariableNames = {'Year','Month','DayofMonth','DayOfWeek',... 'DepTime','ArrDelay','DepDelay','Distance'}; ds.TreatAsMissing = 'NA'; pre = preview(ds)
pre=8×8 table
Year Month DayofMonth DayOfWeek DepTime ArrDelay DepDelay Distance
____ _____ __________ _________ _______ ________ ________ ________
1987 10 21 3 642 8 12 308
1987 10 26 1 1021 8 1 296
1987 10 23 5 2055 21 20 480
1987 10 23 5 1332 13 12 296
1987 10 22 4 629 4 -1 373
1987 10 28 3 1446 59 63 308
1987 10 8 4 928 3 -2 447
1987 10 10 6 859 11 -1 954
データの処理を容易にするため、データストアによって支援される tall table を作成します。tall 配列の基となる型はデータストアの型によって異なります。この場合、データストアはテーブル形式のテキストなので、tall table が返されます。表示にはデータのプレビューが含まれており、サイズが不明であることが示されています。
tt = tall(ds)
tt =
M×8 tall table
Year Month DayofMonth DayOfWeek DepTime ArrDelay DepDelay Distance
____ _____ __________ _________ _______ ________ ________ ________
1987 10 21 3 642 8 12 308
1987 10 26 1 1021 8 1 296
1987 10 23 5 2055 21 20 480
1987 10 23 5 1332 13 12 296
1987 10 22 4 629 4 -1 373
1987 10 28 3 1446 59 63 308
1987 10 8 4 928 3 -2 447
1987 10 10 6 859 11 -1 954
: : : : : : : :
: : : : : : : :
データの前処理
この例の目的は、時刻と曜日をさらに詳しく調べることです。ラベルがある categorical 配列に曜日を変換し、出発時間の数値変数から時間を判別します。
tt.DayOfWeek = categorical(tt.DayOfWeek,1:7,{'Sun','Mon','Tues',...
'Wed','Thu','Fri','Sat'});
tt.Hr = discretize(tt.DepTime,0:100:2400,0:23)tt =
M×9 tall table
Year Month DayofMonth DayOfWeek DepTime ArrDelay DepDelay Distance Hr
____ _____ __________ _________ _______ ________ ________ ________ __
1987 10 21 Tues 642 8 12 308 6
1987 10 26 Sun 1021 8 1 296 10
1987 10 23 Thu 2055 21 20 480 20
1987 10 23 Thu 1332 13 12 296 13
1987 10 22 Wed 629 4 -1 373 6
1987 10 28 Tues 1446 59 63 308 14
1987 10 8 Wed 928 3 -2 447 9
1987 10 10 Fri 859 11 -1 954 8
: : : : : : : : :
: : : : : : : : :
2000 年以後の年のみを含め、欠損データがある行は無視します。対象のデータは、論理条件によって識別します。
idx = tt.Year >= 2000 & ...
~any(ismissing(tt),2);
tt = tt(idx,:);グループごとのデータ調査
いくつかの調査関数では tall 配列を利用できます。たとえば、関数 grpstats は tall 配列のグループ化された統計を計算します。曜日でグループ化された要約統計量を使用してデータの中心性と広がりを判別することによりデータを調べます。また、出発の遅れと到着の遅れとの相関を調べます。
g = grpstats(tt(:,{'ArrDelay','DepDelay','DayOfWeek'}),'DayOfWeek',...
{'mean','std','skewness','kurtosis'})g =
M×11 tall table
GroupLabel DayOfWeek GroupCount mean_ArrDelay std_ArrDelay skewness_ArrDelay kurtosis_ArrDelay mean_DepDelay std_DepDelay skewness_DepDelay kurtosis_DepDelay
__________ _________ __________ _____________ ____________ _________________ _________________ _____________ ____________ _________________ _________________
? ? ? ? ? ? ? ? ? ? ?
? ? ? ? ? ? ? ? ? ? ?
? ? ? ? ? ? ? ? ? ? ?
: : : : : : : : : : :
: : : : : : : : : : :
Preview deferred. Learn more.
C = corr(tt.DepDelay,tt.ArrDelay)
C =
M×N×... tall array
? ? ? ...
? ? ? ...
? ? ? ...
: : :
: : :
Preview deferred. Learn more.
これらのコマンドにより、さらに tall 配列が生成されます。結果が明示的にワークスペースに収集されるまでコマンドは実行されません。gather コマンドは実行をトリガーし、計算を実行するためにデータを通過しなければならない回数を最小限に抑えようとします。gather では、生成される変数がメモリに収まる必要があります。
[statsByDay,C] = gather(g,C)
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 1: Completed in 0.69 sec Evaluation completed in 1.1 sec
statsByDay=7×11 table
GroupLabel DayOfWeek GroupCount mean_ArrDelay std_ArrDelay skewness_ArrDelay kurtosis_ArrDelay mean_DepDelay std_DepDelay skewness_DepDelay kurtosis_DepDelay
__________ _________ __________ _____________ ____________ _________________ _________________ _____________ ____________ _________________ _________________
{'Fri' } Fri 7339 4.1512 32.1 7.082 120.53 7.0857 29.339 8.9387 168.37
{'Mon' } Mon 8443 5.2487 32.453 4.5811 37.175 6.8319 28.573 5.6468 50.271
{'Sat' } Sat 8045 7.132 33.108 3.6457 22.991 9.1557 29.731 4.5135 31.228
{'Sun' } Sun 8570 7.7515 36.003 5.7943 80.91 9.3324 32.516 7.2146 118.25
{'Thu' } Thu 8601 10.053 36.18 4.1381 37.051 10.923 34.708 1.1414 138.38
{'Tues'} Tues 8381 6.4786 32.322 4.374 38.694 7.6083 28.394 5.2012 46.249
{'Wed' } Wed 8489 9.3324 37.406 5.1638 57.479 10 33.426 6.4336 85.426
C = 0.8966
結果が含まれている変数はこの時、ワークスペース内のインメモリ変数です。これらの計算に基づいてデータ内で変動が発生します。遅れの間に相関があり、さらに調べることができます。
曜日と時刻の影響を調べ、平均の標準誤差や平均の 95% 信頼区間など追加の統計情報を取得します。tall table 全体を渡して、計算の対象となる変数を指定できます。
byDayHr = grpstats(tt,{'Hr','DayOfWeek'},...
{'mean','sem','meanci'},'DataVar','DepDelay');
byDayHr = gather(byDayHr);Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 1: Completed in 0.5 sec Evaluation completed in 0.65 sec
tall 配列のデータ分割が原因となって、出力が順序付けされない可能性があります。さらに調べるため、メモリ内のデータを再配置します。
x = unstack(byDayHr(:,{'Hr','DayOfWeek','mean_DepDelay'}),...
'mean_DepDelay','DayOfWeek');
x = sortrows(x)x=24×8 table
Hr Sun Mon Tues Wed Thu Fri Sat
__ _______ ________ ________ _______ _______ _______ _______
0 38.519 71.914 39.656 34.667 90 25.536 65.579
1 45.846 27.875 93.6 125.23 52.765 38.091 29.182
2 NaN 39 102 NaN 78.25 -1.5 NaN
3 NaN NaN NaN NaN -377.5 53.5 NaN
4 -7 -6.2857 -7 -7.3333 -10.5 -5 NaN
5 -2.2409 -3.7099 -4.0146 -3.9565 -3.5897 -3.5766 -4.1474
6 0.4 -1.8909 -1.9802 -1.8304 -1.3578 0.84161 -2.2537
7 3.4173 -0.47222 -0.18893 0.71546 0.08 1.069 -1.3221
8 2.3759 1.4054 1.6745 2.2345 2.9668 1.6727 0.88213
9 2.5325 1.6805 2.7656 2.683 5.6138 3.4838 2.5011
10 6.37 5.2868 3.6822 7.5773 5.3372 6.9391 4.9979
11 6.9946 4.9165 5.5639 5.5936 7.0435 4.8989 5.2839
12 5.673 5.1193 5.7081 7.9178 7.5269 8.0625 7.4686
13 8.0879 7.1017 5.0857 8.8082 8.2878 8.0675 6.2107
14 9.5164 5.8343 7.416 9.5954 8.6667 6.0677 8.444
15 8.1257 4.8802 7.4726 9.8674 10.235 7.167 8.6219
⋮
tall 配列のデータの可視化
現在、tall 配列のデータの可視化には histogram、histogram2、binScatterPlot および ksdensity を使用できます。すべての可視化で、関数 gather の呼び出しと同じように実行がトリガーされます。
binScatterPlot を使用して変数 Hr と変数 DepDelay の関係を調べます。
binScatterPlot(tt.Hr,tt.DepDelay,'Gamma',0.25)Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 1: Completed in 0.36 sec Evaluation completed in 0.48 sec Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 1: Completed in 0.27 sec Evaluation completed in 0.31 sec
ylim([0 500]) xlabel('Time of Day') ylabel('Delay (Minutes)')

出力表示に記されているように、多くの場合、可視化ではデータを 2 回通過します。ビンにまとめるための 1 回と、ビンに対する計算を実行して可視化を生成するための 1 回です。
学習セットと検証セットへのデータの分割
機械学習モデルを開発するには、データの一部をモデルの学習および開発用に保持し、データの別の部分をモデルのテスト用に保持すると有益です。データを学習セットと検証セットに分割する方法はいくつかあります。
datasample を使用してデータの無作為標本を抽出します。次に、cvpartition を使用してデータをテスト セットと学習セットに分割します。非層化区分を取得するため、データ標本にゼロを乗算して一様なグループ化変数を設定します。
再現性を得るため、tallrng を使用して乱数発生器のシードを設定します。tall 配列の場合、ワーカーの個数と実行環境によって結果が異なる可能性があります。詳細については、コードの実行場所の制御を参照してください。
tallrng('default') data = datasample(tt,25000,'Replace',false); groups = 0*data.DepDelay; y = cvpartition(groups,'HoldOut',1/3); dataTrain = data(training(y),:); dataTest = data(test(y),:);
教師あり学習モデルの当てはめ
いくつかの変数に基づいて出発の遅れを予測するモデルを構築します。線形回帰モデル関数 fitlm はインメモリ関数と同じように動作します。ただし、tall 配列を使用して計算を行うと、大規模なデータ セットでより効率的な CompactLinearModel が生成されます。モデルの当てはめは反復的なプロセスなので、実行がトリガーされます。
model = fitlm(dataTrain,'ResponseVar','DepDelay')
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 2: Completed in 0.4 sec - Pass 2 of 2: Completed in 0.78 sec Evaluation completed in 1.4 sec
model =
Compact linear regression model:
DepDelay ~ 1 + Year + Month + DayofMonth + DayOfWeek + DepTime + ArrDelay + Distance + Hr
Estimated Coefficients:
Estimate SE tStat pValue
__________ __________ ________ __________
(Intercept) 30.715 75.873 0.40482 0.68562
Year -0.01585 0.037853 -0.41872 0.67543
Month 0.03009 0.028097 1.0709 0.28421
DayofMonth -0.0094266 0.010903 -0.86457 0.38729
DayOfWeek_Mon -0.36333 0.35527 -1.0227 0.30648
DayOfWeek_Tues -0.2858 0.35245 -0.81091 0.41743
DayOfWeek_Wed -0.56082 0.35309 -1.5883 0.11224
DayOfWeek_Thu -0.25295 0.35239 -0.71782 0.47288
DayOfWeek_Fri 0.91768 0.36625 2.5056 0.012234
DayOfWeek_Sat 0.45668 0.35785 1.2762 0.20191
DepTime -0.011551 0.0053851 -2.145 0.031964
ArrDelay 0.8081 0.002875 281.08 0
Distance 0.0012881 0.00016887 7.6281 2.5106e-14
Hr 1.4058 0.53785 2.6138 0.0089613
Number of observations: 16667, Error degrees of freedom: 16653
Root Mean Squared Error: 12.4
R-squared: 0.834, Adjusted R-Squared: 0.833
F-statistic vs. constant model: 6.41e+03, p-value = 0
モデルの予測と検証
表示には、当てはめの情報、係数および関連する係数統計が示されています。
変数 model には当てはめたモデルに関する情報がプロパティとして含まれており、ドット表記を使用してアクセスできます。または、ワークスペースで変数をダブルクリックして対話的にプロパティを確認します。
model.Rsquared
ans = struct with fields:
Ordinary: 0.8335
Adjusted: 0.8334
モデルに基づいて新しい値を予測し、残差を計算し、ヒストグラムを使用して可視化を行います。関数 predict は tall データとインメモリ データの両方について新しい値を予測します。
pred = predict(model,dataTest); err = pred - dataTest.DepDelay; figure histogram(err,'BinLimits',[-100 100],'Normalization','pdf')
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 2: Completed in 0.52 sec - Pass 2 of 2: Completed in 0.27 sec Evaluation completed in 0.93 sec
title('Histogram of Residuals')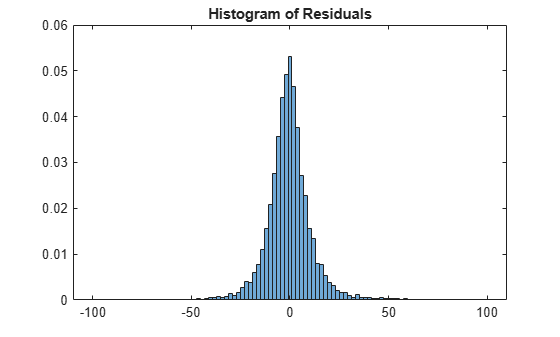
モデルの評価と調整
表示の出力 p 値を見ると、一部の変数はモデルに不要であると考えられます。このような変数を削除すると、モデルの複雑度を減らすことができます。
anova を使用して、モデルにおける変数の有意性をより詳しく確認します。
a = anova(model)
a=9×5 table
SumSq DF MeanSq F pValue
__________ _____ __________ _______ __________
Year 26.88 1 26.88 0.17533 0.67543
Month 175.84 1 175.84 1.1469 0.28421
DayofMonth 114.6 1 114.6 0.74749 0.38729
DayOfWeek 3691.4 6 615.23 4.0129 0.00050851
DepTime 705.42 1 705.42 4.6012 0.031964
ArrDelay 1.2112e+07 1 1.2112e+07 79004 0
Distance 8920.9 1 8920.9 58.188 2.5106e-14
Hr 1047.5 1 1047.5 6.8321 0.0089613
Error 2.5531e+06 16653 153.31
p 値に基づくと、変数 Year、Month および DayOfMonth はこのモデルでは有意ではないので、これらを削除してもモデルの品質にマイナスの影響はありません。
これらのモデル パラメーターをさらに調べるには、plotSlice、plotInterations、plotEffects などの対話的な可視化を使用します。たとえば、出発の遅れに対する各予測子変数の推定効果を調べるには、plotEffects を使用します。
plotEffects(model)
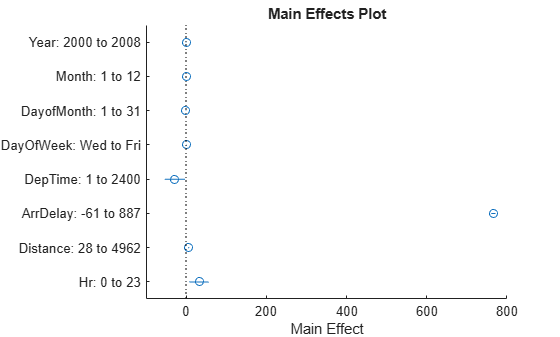
これらの計算に基づくと、モデルの主効果は ArrDelay です (DepDelay と高い相関があります)。他の効果は観測可能ですが、影響は非常に小さくなっています。さらに、Hr は DepTime から決定したので、これらの変数のうちモデルに必要なのは 1 つだけです。
変数の数を減らしてすべての日付成分を除外し、新しいモデルを当てはめます。
model2 = fitlm(dataTrain,'DepDelay ~ DepTime + ArrDelay + Distance')Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 1: Completed in 0.44 sec Evaluation completed in 0.5 sec
model2 =
Compact linear regression model:
DepDelay ~ 1 + DepTime + ArrDelay + Distance
Estimated Coefficients:
Estimate SE tStat pValue
_________ __________ _______ __________
(Intercept) -1.4646 0.31696 -4.6207 3.8538e-06
DepTime 0.0025087 0.00020401 12.297 1.3333e-34
ArrDelay 0.80767 0.0028712 281.3 0
Distance 0.0012981 0.00016886 7.6875 1.5838e-14
Number of observations: 16667, Error degrees of freedom: 16663
Root Mean Squared Error: 12.4
R-squared: 0.833, Adjusted R-Squared: 0.833
F-statistic vs. constant model: 2.77e+04, p-value = 0
モデルの開発
モデルを単純化した状態でも、変数間の関係をさらに調整して明確な交互作用を含めると有益な可能性があります。さらに調べるには、小さい tall 配列でこのワークフローを繰り返します。モデルを調整するときのパフォーマンスを高めるには、インメモリ データを少量抽出、処理した後に tall 配列全体に拡張することが考えられます。
この例では、反復的なインメモリ モデル開発に適している、ステップワイズ回帰に似た機能を使用できます。モデルを調整した後で、tall 配列を使用するように拡張できます。
データのサブセットをワークスペースに収集し、stepwiselm を使用してメモリ内で反復的にモデルを開発します。
subset = gather(dataTest);
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 1: Completed in 0.27 sec Evaluation completed in 0.33 sec
sModel = stepwiselm(subset,'ResponseVar','DepDelay')
1. Adding ArrDelay, FStat = 42200.3016, pValue = 0 2. Adding DepTime, FStat = 51.7918, pValue = 6.70647e-13 3. Adding DepTime:ArrDelay, FStat = 42.4982, pValue = 7.48624e-11 4. Adding Distance, FStat = 15.4303, pValue = 8.62963e-05 5. Adding ArrDelay:Distance, FStat = 231.9012, pValue = 1.135326e-51 6. Adding DayOfWeek, FStat = 3.4704, pValue = 0.0019917 7. Adding DayOfWeek:ArrDelay, FStat = 26.334, pValue = 3.16911e-31 8. Adding DayOfWeek:DepTime, FStat = 2.1732, pValue = 0.042528
sModel =
Linear regression model:
DepDelay ~ 1 + DayOfWeek*DepTime + DayOfWeek*ArrDelay + DepTime*ArrDelay + ArrDelay*Distance
Estimated Coefficients:
Estimate SE tStat pValue
___________ __________ ________ __________
(Intercept) 1.1799 1.0675 1.1053 0.26904
DayOfWeek_Mon -2.1377 1.4298 -1.4951 0.13493
DayOfWeek_Tues -4.2868 1.4683 -2.9196 0.0035137
DayOfWeek_Wed -1.6233 1.476 -1.0998 0.27145
DayOfWeek_Thu -0.74772 1.5226 -0.49109 0.62338
DayOfWeek_Fri -1.7618 1.5079 -1.1683 0.2427
DayOfWeek_Sat -2.1121 1.5214 -1.3882 0.16511
DepTime 7.5229e-05 0.00073613 0.10219 0.9186
ArrDelay 0.8671 0.013836 62.669 0
Distance 0.0015163 0.00023426 6.4728 1.0167e-10
DayOfWeek_Mon:DepTime 0.0017633 0.0010106 1.7448 0.081056
DayOfWeek_Tues:DepTime 0.0032578 0.0010331 3.1534 0.0016194
DayOfWeek_Wed:DepTime 0.00097506 0.001044 0.93398 0.35034
DayOfWeek_Thu:DepTime 0.0012517 0.0010694 1.1705 0.24184
DayOfWeek_Fri:DepTime 0.0026464 0.0010711 2.4707 0.013504
DayOfWeek_Sat:DepTime 0.0021477 0.0010646 2.0174 0.043689
DayOfWeek_Mon:ArrDelay -0.11023 0.014744 -7.4767 8.399e-14
DayOfWeek_Tues:ArrDelay -0.14589 0.014814 -9.8482 9.2943e-23
DayOfWeek_Wed:ArrDelay -0.041878 0.012849 -3.2593 0.0011215
DayOfWeek_Thu:ArrDelay -0.096741 0.013308 -7.2693 3.9414e-13
DayOfWeek_Fri:ArrDelay -0.077713 0.015462 -5.0259 5.1147e-07
DayOfWeek_Sat:ArrDelay -0.13669 0.014652 -9.329 1.3471e-20
DepTime:ArrDelay 6.4148e-05 7.7372e-06 8.2909 1.3002e-16
ArrDelay:Distance -0.00010512 7.3888e-06 -14.227 2.1138e-45
Number of observations: 8333, Error degrees of freedom: 8309
Root Mean Squared Error: 12
R-squared: 0.845, Adjusted R-Squared: 0.845
F-statistic vs. constant model: 1.97e+03, p-value = 0
ステップワイズ近似から生成したモデルには交互作用項が含まれています。
次に、stepwiselm によって返された式と共に fitlm を使用することにより、tall データ用のモデルの当てはめを試します。
model3 = fitlm(dataTrain,sModel.Formula)
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 1: Completed in 0.41 sec Evaluation completed in 0.44 sec
model3 =
Compact linear regression model:
DepDelay ~ 1 + DayOfWeek*DepTime + DayOfWeek*ArrDelay + DepTime*ArrDelay + ArrDelay*Distance
Estimated Coefficients:
Estimate SE tStat pValue
___________ __________ ________ __________
(Intercept) -0.31595 0.74499 -0.4241 0.6715
DayOfWeek_Mon -0.64218 1.0473 -0.61316 0.53978
DayOfWeek_Tues -0.90163 1.0383 -0.86836 0.38521
DayOfWeek_Wed -1.0798 1.0417 -1.0365 0.29997
DayOfWeek_Thu -3.2765 1.0379 -3.157 0.0015967
DayOfWeek_Fri 0.44193 1.0813 0.40869 0.68277
DayOfWeek_Sat 1.1428 1.0777 1.0604 0.28899
DepTime 0.0014188 0.00051612 2.7489 0.0059853
ArrDelay 0.72526 0.011907 60.913 0
Distance 0.0014824 0.00017027 8.7059 3.4423e-18
DayOfWeek_Mon:DepTime 0.00040994 0.00073548 0.55738 0.57728
DayOfWeek_Tues:DepTime 0.00051826 0.00073645 0.70373 0.48161
DayOfWeek_Wed:DepTime 0.00058426 0.00073695 0.79281 0.4279
DayOfWeek_Thu:DepTime 0.0026229 0.00073649 3.5614 0.00036991
DayOfWeek_Fri:DepTime 0.0002959 0.00077194 0.38332 0.70149
DayOfWeek_Sat:DepTime -0.00060921 0.00075776 -0.80396 0.42143
DayOfWeek_Mon:ArrDelay -0.034886 0.010435 -3.3432 0.00082993
DayOfWeek_Tues:ArrDelay -0.0073661 0.010113 -0.72837 0.4664
DayOfWeek_Wed:ArrDelay -0.028158 0.0099004 -2.8441 0.0044594
DayOfWeek_Thu:ArrDelay -0.061065 0.010381 -5.8821 4.1275e-09
DayOfWeek_Fri:ArrDelay 0.052437 0.010927 4.7987 1.6111e-06
DayOfWeek_Sat:ArrDelay 0.014205 0.01039 1.3671 0.1716
DepTime:ArrDelay 7.2632e-05 5.3946e-06 13.464 4.196e-41
ArrDelay:Distance -2.4743e-05 4.6508e-06 -5.3203 1.0496e-07
Number of observations: 16667, Error degrees of freedom: 16643
Root Mean Squared Error: 12.3
R-squared: 0.837, Adjusted R-Squared: 0.836
F-statistic vs. constant model: 3.7e+03, p-value = 0
このプロセスを繰り返して引き続き線形モデルを調整することができます。しかし、このケースでは、このデータにさらに適している可能性がある別のタイプの回帰を調べるべきです。たとえば、到着の遅れを含めない場合、このタイプの線形モデルは適切ではなくなります。詳細は、tall 配列を使用するロジスティック回帰を参照してください。
Spark への拡張
MATLAB と Statistics and Machine Learning Toolbox の tall 配列の主要な機能の一つとして、Hadoop や Spark などのプラットフォームへの接続があります。MATLAB Compiler™ を使用すると、コードをコンパイルして Spark で実行することもできます。以下の製品の使用に関する詳細については、他の製品による tall 配列の拡張を参照してください。
Database Toolbox™
Parallel Computing Toolbox™
MATLAB® Parallel Server™
MATLAB Compiler™