tall 配列を使用した MATLAB でのビッグ データの解析
この例では、tall 配列を使用して MATLAB® でビッグ データを処理する方法を示します。tall 配列を使用して、メモリに収まらないさまざまな種類のデータで各種計算を実行できます。これには、基本の計算の他に、Statistics and Machine Learning Toolbox™ 内の機械学習アルゴリズムも含まれます。
この例では、1 台のコンピューターでデータの小さなサブセットに対して演算を実行した後に、スケール アップしてすべてのデータ セットを解析します。ただし、この解析手法ではさらにスケール アップしてメモリに読み取ることができない大きいデータ セットを扱ったり、Apache Spark™ などのシステムで作業することができます。
tall 配列の紹介
tall 配列と tall テーブルは、任意の行数をもつメモリに収まらないデータを処理するために使用されます。巨大なサイズのデータを考慮する特殊なコードを作成するのではなく、tall 配列と tall テーブルを使用してインメモリ MATLAB® 配列と同様の方法で大きなデータ セットを処理することができます。違いは、計算の実行を要求するまで tall 配列は通常未評価のままであるという点です。
この遅延評価により、MATLAB では可能な限りキューに登録された計算を組み合わせ、データを通す回数を最小に抑えることができます。データを通す回数は実行時間に大きく影響するため、出力は必要な場合にのみ要求することをお勧めします。
ファイルのコレクション用のデータストアの作成
データストアを作成するとデータのコレクションにアクセスできます。データストアは、大量のデータを任意に処理することができます。データが複数のフォルダー内の複数のファイルに散在していても構いません。データストアは、表形式のテキスト ファイル (ここで例示)、スプレッドシート、イメージのコレクション、SQL データベース (Database Toolbox™ が必要)、Hadoop® シーケンス ファイルなど、ほとんどのファイル タイプについて作成できます。
航空路線のデータを含む .csv ファイルのデータストアを作成します。'NA' 値を欠損値として扱います。これにより、tabularTextDatastore がそれらを NaN 値に置き換えます。必要な変数を選択し、変数 Origin と Dest に categorical データ型を指定します。内容をプレビューします。
ds = tabularTextDatastore('airlinesmall.csv'); ds.TreatAsMissing = 'NA'; ds.SelectedVariableNames = {'Year','Month','ArrDelay','DepDelay','Origin','Dest'}; ds.SelectedFormats(5:6) = {'%C','%C'}; pre = preview(ds)
pre=8×6 table
Year Month ArrDelay DepDelay Origin Dest
____ _____ ________ ________ ______ ____
1987 10 8 12 LAX SJC
1987 10 8 1 SJC BUR
1987 10 21 20 SAN SMF
1987 10 13 12 BUR SJC
1987 10 4 -1 SMF LAX
1987 10 59 63 LAX SJC
1987 10 3 -2 SAN SFO
1987 10 11 -1 SEA LAX
tall 配列の作成
tall 配列は、任意の行数をもつことができる点を除き、インメモリ MATLAB 配列と似ています。tall 配列には、数値型、logical 型、datetime 型、duration 型、calendarDuration 型、categorical 型、string 型のデータを含めることができます。また、どのインメモリ配列でも tall 配列に変換することができます (インメモリ配列 A はサポートされるいずれかのデータ型でなければなりません)。
tall 配列の基となるクラスは、元のデータストアのタイプに基づきます。たとえば、データストア ds に表形式データが含まれる場合、tall(ds) はそのデータを含む tall table を返します。
tt = tall(ds)
tt =
M×6 tall table
Year Month ArrDelay DepDelay Origin Dest
____ _____ ________ ________ ______ ____
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
: : : : : :
: : : : : :
Preview deferred. Learn more.
表示には、基となるデータ型が示され、データの先頭の数行が含まれます。table のサイズは "Mx6" と表示されています。これは MATLAB がデータの行数をまだ把握していないことを示します。
tall 配列での計算の実行
tall 配列と tall テーブルはインメモリ MATLAB 配列およびテーブルと同様の方法で使用できます。
tall 配列の重要な点の 1 つは、この配列を処理しても MATLAB ではほとんどの演算がすぐに実行されないことです。これらの演算が迅速に実行されているように見えるのは、明確に出力を要求するまで実際の計算が延期されるためです。size(X) のような単純なコマンドでも、10 億行の tall 配列で実行した場合、迅速に計算されないため、この遅延評価は重要です。
tall 配列を処理する際に、MATLAB は実行されるすべての演算を追跡し、データを通す回数を最適化します。そのため、必要な場合にのみ未評価の tall 配列を処理し、出力を要求するようになっています。MATLAB では、配列の評価と表示が要求されるまで未評価の tall 配列の内容またはサイズを把握しません。
平均出発遅延時間を計算します。
mDep = mean(tt.DepDelay,'omitnan')mDep =
tall double
?
Preview deferred. Learn more.
ワークスペースへの結果の収集
遅延評価のメリットは、MATLAB で計算を実行する段階になったときに、多くの場合はデータを通す回数が最小になるように演算を組み合わせることが可能である点です。したがって、実行する演算が多くても、MATLAB はどうしても必要な場合にのみ追加でデータを通します。
関数 gather によって、キューに登録されたすべての演算が強制的に評価されて、結果の出力はメモリに戻ります。MATLAB では gather によって "全体" の結果が返されるため、結果がメモリ内に収まることを確認する必要があります。たとえば、sum、min、mean など、tall 配列のサイズを減らす関数の結果の tall 配列で gather を使用します。
gather を使用して平均出発遅延時間を計算し、回答をメモリに入れます。この計算でデータを通さなければならないのは 1 回ですが、他の計算では複数回データを通さなければならない場合があります。MATLAB は、計算においてデータを通す最適な回数を判別し、コマンド ラインにこの情報を表示します。
mDep = gather(mDep)
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 2: Completed in 0.39 sec - Pass 2 of 2: Completed in 0.38 sec Evaluation completed in 1 sec
mDep = 8.1860
tall 配列のサブセットの選択
添字を作成するか、インデックス付けして tall 配列から値を抽出できます。配列の先頭からまたは末尾から、あるいは論理インデックスを使用してインデックス付けすることができます。インデックス付けの代替方法として、関数 head と tail を使用して、tall 配列の最初と最後の部分を調べることができます。両方の変数を同時に収集してデータを通す回数が追加されないようにします。
h = head(tt); tl = tail(tt); [h,tl] = gather(h,tl)
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 1: Completed in 0.33 sec Evaluation completed in 0.41 sec
h=8×6 table
Year Month ArrDelay DepDelay Origin Dest
____ _____ ________ ________ ______ ____
1987 10 8 12 LAX SJC
1987 10 8 1 SJC BUR
1987 10 21 20 SAN SMF
1987 10 13 12 BUR SJC
1987 10 4 -1 SMF LAX
1987 10 59 63 LAX SJC
1987 10 3 -2 SAN SFO
1987 10 11 -1 SEA LAX
tl=8×6 table
Year Month ArrDelay DepDelay Origin Dest
____ _____ ________ ________ ______ ____
2008 12 14 1 DAB ATL
2008 12 -8 -1 ATL TPA
2008 12 1 9 ATL CLT
2008 12 -8 -4 ATL CLT
2008 12 15 -2 BOS LGA
2008 12 -15 -1 SFO ATL
2008 12 -12 1 DAB ATL
2008 12 -1 11 ATL IAD
head を使用して、完全なデータ セットにスケーリングする前に、コードのプロトタイピング用にデータから 10,000 行のサブセットを選択します。
ttSubset = head(tt,10000);
条件によるデータの選択
tall 配列では通常の論理演算を使用できます。論理演算は、関連データを選択したり、論理インデックス付けで外れ値を削除するのに役立ちます。論理式で tall logical ベクトルが作成されます。これを使用して添字付けを行い、条件が真となる行を特定します。
categorical 変数 Origin の要素を値 'BOS' と比較してボストンを出発するフライトのみを選択します。
idx = (ttSubset.Origin == 'BOS');
bosflights = ttSubset(idx,:)bosflights =
207×6 tall table
Year Month ArrDelay DepDelay Origin Dest
____ _____ ________ ________ ______ ____
1987 10 -8 0 BOS LGA
1987 10 -13 -1 BOS LGA
1987 10 12 11 BOS BWI
1987 10 -3 0 BOS EWR
1987 10 -5 0 BOS ORD
1987 10 31 19 BOS PHL
1987 10 -3 0 BOS CLE
1987 11 5 5 BOS STL
: : : : : :
: : : : : :
同じインデックス付け手法を使用して、tall 配列から欠損データまたは NaN 値をもつ行を削除できます。
idx = any(ismissing(ttSubset),2); ttSubset(idx,:) = [];
最大遅延時間の特定
ビッグ データの特性により、sort や sortrows などの従来型の方法を使用したすべてのデータの並べ替えは効率的とは言えません。ただし、tall 配列用の関数 topkrows は、上位 k 行を並べ替えられた順序で返します。
上位 10 位までの最大出発遅延時間を計算します。
biggestDelays = topkrows(ttSubset,10,'DepDelay');
biggestDelays = gather(biggestDelays)Evaluating tall expression using the Local MATLAB Session: Evaluation completed in 0.037 sec
biggestDelays=10×6 table
Year Month ArrDelay DepDelay Origin Dest
____ _____ ________ ________ ______ ____
1988 3 772 785 ORD LEX
1989 3 453 447 MDT ORD
1988 12 397 425 SJU BWI
1987 12 339 360 DEN STL
1988 3 261 273 PHL ROC
1988 7 261 268 BWI PBI
1988 2 257 253 ORD BTV
1988 3 236 240 EWR FLL
1989 2 263 227 BNA MOB
1989 6 224 225 DFW JAX
tall 配列のデータの可視化
ビッグ データ セット内のすべての点をプロットすることは不可能です。そのため、tall 配列の可視化では、サンプリングまたはビン化を使用してデータ点の数を削減します。
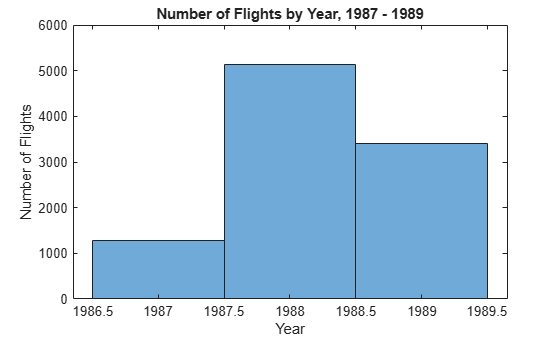
ヒストグラムにより 1 年あたりのフライト数を可視化します。可視化関数はデータを通し、関数を呼び出すとすぐに解を評価するため、gather は必要ありません。
histogram(ttSubset.Year,'BinMethod','integers')
Evaluating tall expression using the Local MATLAB Session: Evaluation completed in 0.19 sec
xlabel('Year') ylabel('Number of Flights') title('Number of Flights by Year, 1987 - 1989')
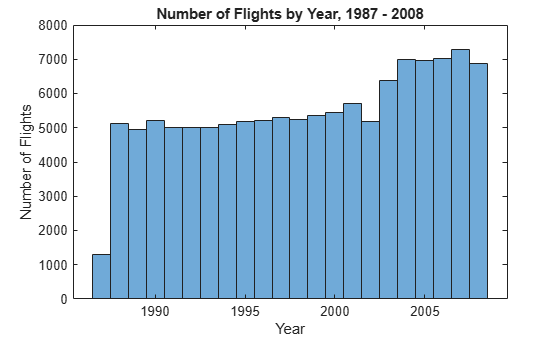
データ セット全体へのスケーリング
head から返される少量のデータを使用するのではなく、スケール アップして tall(ds) の結果を使用し、データ セット全体に対して計算を実行することができます。
tt = tall(ds); idx = any(ismissing(tt),2); tt(idx,:) = []; mnDelay = mean(tt.DepDelay,'omitnan'); biggestDelays = topkrows(tt,10,'DepDelay'); [mnDelay,biggestDelays] = gather(mnDelay,biggestDelays)
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 2: Completed in 0.18 sec - Pass 2 of 2: Completed in 0.25 sec Evaluation completed in 0.48 sec
mnDelay = 8.1310
biggestDelays=10×6 table
Year Month ArrDelay DepDelay Origin Dest
____ _____ ________ ________ ______ ____
1991 3 -8 1438 MCO BWI
1998 12 -12 1433 CVG ORF
1995 11 1014 1014 HNL LAX
2007 4 914 924 JFK DTW
2001 4 887 884 MCO DTW
2008 7 845 855 CMH ORD
1988 3 772 785 ORD LEX
2008 4 710 713 EWR RDU
1998 10 679 673 MCI DFW
2006 6 603 626 ABQ PHX
histogram(tt.Year,'BinMethod','integers')
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 2: Completed in 0.24 sec - Pass 2 of 2: Completed in 0.23 sec Evaluation completed in 0.52 sec
xlabel('Year') ylabel('Number of Flights') title('Number of Flights by Year, 1987 - 2008')
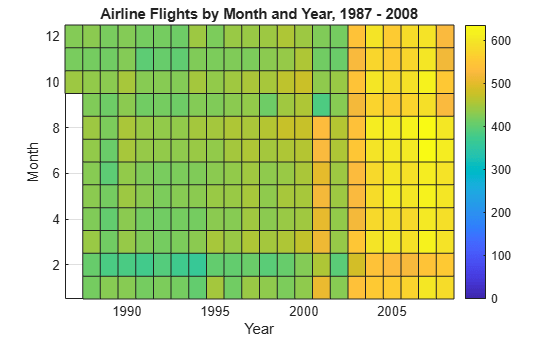
histogram2 を使用して、データ セット全体のフライト数をさらに月別に分割します。Month と Year のビンは事前に把握されているため、ビンのエッジを指定して、追加でデータを通さないようにします。
year_edges = 1986.5:2008.5; month_edges = 0.5:12.5; histogram2(tt.Year,tt.Month,year_edges,month_edges,'DisplayStyle','tile')
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 1: Completed in 0.28 sec Evaluation completed in 0.32 sec
colorbar xlabel('Year') ylabel('Month') title('Airline Flights by Month and Year, 1987 - 2008')
tall 配列を使用したデータの解析と機械学習
Statistics and Machine Learning Toolbox™ の関数を使用して、tall 配列で、予測解析の計算や機械学習の実行を含むより高度な統計解析を実行できます。
詳細については、tall 配列の使用によるビッグ データの統計および機械学習 (Statistics and Machine Learning Toolbox)を参照してください。
ビッグ データ システムへのスケーリング
MATLAB での tall 配列の重要機能は、計算用クラスターや Apache Spark™ などのビッグ データ プラットフォームへの接続です。
この例では、tall 配列によるビッグ データ処理のごく表面に触れたにすぎません。以下の使用法の詳細については、他の製品による tall 配列の拡張を参照してください。
Statistics and Machine Learning Toolbox™
Database Toolbox™
Parallel Computing Toolbox™
MATLAB® Parallel Server™
MATLAB Compiler™