多変量回帰の問題の設定
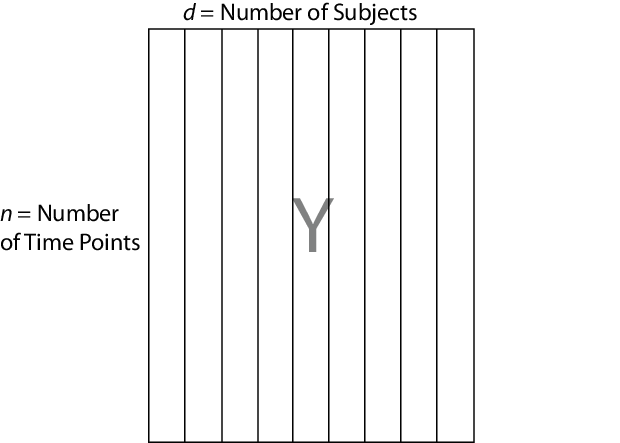
応答行列
mvregress を使用して多変量線形回帰モデルの当てはめを行うには、応答行列と計画行列を特定の方法で設定しなければなりません。正しい形式の入力を指定すると、mvregress ではさまざまな多変量回帰の問題に対処できます。
mvregress は、潜在的に相関する d 次元の応答の n 観測値は、Y などの名前の n 行 d 列の行列になると予測します。つまり、依存関係構造が同じ "行" 内の観測値間に存在するように応答を設定します。Y を長さのベクトル n (行ベクトルまたは列ベクトル) として指定した場合、mvregress は、d = 1 と仮定し、要素を n 個の独立な観測として処理します。ベクトルは相関系列 (時系列など) の 1 つの実現として "モデル化されません"。
応答行列の設定方法の例として、多変量応答が、次の図に示すように複数の時点で被験者に対して繰り返し行われる測定であるとします。
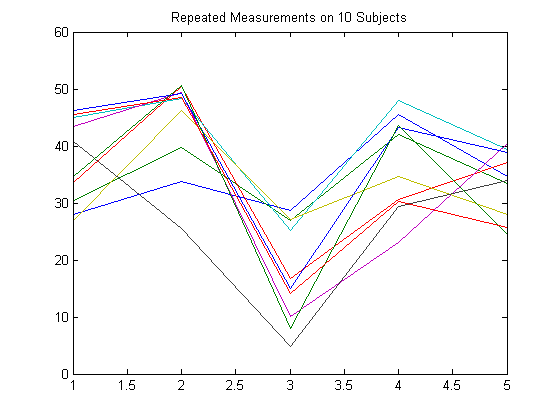
1 人の被験者内の観測は相関するものとします。

この例では、応答行列 Y を、各行が 1 人の被験者を表し、各列が 1 つの時点を表すよう設定します。

ここでも、同時に被験者に行われた観測は相関する (同時相関) ものとします。
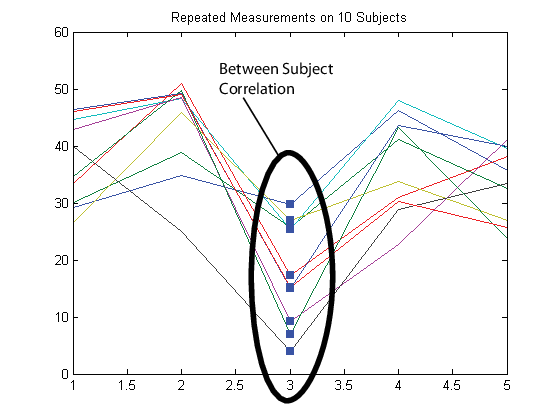
この例では、応答行列 Y を、各行が 1 つの時点を表し、各列が 1 人の被験者を表すよう設定します。
計画行列
多変量線形回帰モデルでは、d 次元の応答ごとに対応する計画行列があります。モデルによっては、計画行列に外因的予測子変数、ダミー変数、ラグ応答、またはこれらとその他の共変量項を組み合わせて構成される場合があります。
d > 1 であり、すべての d 次元で同じ計画行列をもつ場合は、n 行 p 列の計画行列を 1 つ指定します (p は予測子変数の数)。各次元の切片を決定するには、1 の列を計画行列に追加します。この場合、
mvregressは計画行列をすべての d 次元に適用します。d > 1 であり d 次元に同じ計画行列をもたないものがある場合は、d 行 K 列の配列から成る長さ n の cell 配列 (たとえば
Xという名前) を使用して計画行列を指定します。K はモデル内の回帰係数の総数です。X内の配列の行は、応答行列Yの列に対応することに注意してください。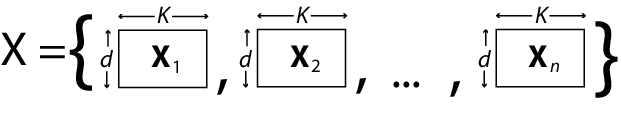
n 回のすべての観測が同じ計画行列をもつ場合、1 つの d 行 K 列の計画行列を含む cell 配列を指定できます。この例では、
mvregressは計画行列を n 回のすべての観測に適用します。たとえば、予測子が時間の関数であるときに、すべての観測が同じ時点で測定された場合に、この状況になる可能性があります。d = 1 となる特殊なケースでは、1 つの n 行 K 列の計画行列 (cell 配列内に含まれていない) を指定できます。ただし、
fitlmを使用して回帰モデルを一変量の連続応答に当てはめることを検討する必要があります。
以下の節では、mvregress を使用して推定の一般的な多変量回帰の問題を設定する方法を示します。
一般的な多変量回帰の問題
多変量一般線形モデル
多変量一般線形モデルは、次の形式になります。
展開された形式は次のとおりです。
つまり、各 d 次元の応答には切片と p 個の予測子変数が、各次元には別々の回帰係数のセットが含まれています。この形式では、最小二乗解は B = X\Y です。mvregress を使用してこのモデルを推定するには、上記のように、応答の n 行 d 列の行列を使用します。
すべての d 次元が同じ計画行列をもつ場合は、上記のように n 行 (p+1) 列の計画行列を使用します。p 個の予測子変数に 1 の列を追加すると、各次元の切片が計算されます。
d 次元に同じ計画行列をもたないものがある場合は、n 行 (p + 1) 列の計画行列を、d 行 K 列の行列から成る長さ n の cell 配列に再構成します。ここで各次元の切片と傾きに対して K = (p + 1)d です。
たとえば、n = 4、d = 3、p = 2 (1 つの切片に加えて 2 つの予測子項) であるとします。次の図は、cell 配列内の i 番目の要素を構成する方法を示しています。
必要に応じて、推定後に、係数の K 行 1 列のベクトルを (p + 1) 行 d 列の行列の形状に戻すことができます。
モデル パラメーターに制約を付けるには、それに合わせて計画行列を調整します。たとえば、前の例の 3 つの次元に 1 つの共通する傾きがあるとします。つまり、 および とします。この場合、次の図に示すように各計画行列は 3 行 5 列になります。
縦方向解析
縦方向解析では、同一の被験者に行われた観測間の相関によって、d 時点の n 人の被験者の応答を測定する場合があります。たとえば、tij、i = 1,...,n および j = 1,...,d 時点の応答 yij を測定するとします。また、各被験者が、指標変数 Gi で指定された 2 つのグループの一方 (男性または女性など) に含まれるとします。グループ固有の切片と傾きを使用すると、次のように Gi および tij の関数として yij をモデル化できます。
ここで
ほとんどの縦方向モデルには、明示的予測子として時間が含まれます。
mvregress を使用してこのモデルを当てはめるには、n 行 d 列の行列の応答を調整します。n は被験者の数で、d は時間点の数です。d 行 K 列の行列の n 長の cell 配列で計画行列を指定します。ここで、K = 4 は 4 つの回帰係数を表します。
たとえば、d = 5 (被験者あたり 5 回の観測) とします。指定されたモデルの i 番目の計画行列と対応するパラメーター ベクトルを次の図に示します。
パネル解析
パネル解析では、d 被験者 (個人または国など) について、n 時間点における応答と共変量を測定する場合もあります。たとえば、t = 1,...,n 時点における被験者 j = 1,...,d に対する応答 ytj および共変量 xtj を測定するとします。被験者固有の固定効果が含まれている固定効果のパネル モデルと同時相関は次のようになります。
ここで
縦方向モデルでは時間を明示的な予測子として使用しますが、一般にパネル解析モデルには各時間点で測定した共変量が含まれます。
mvregress を使用してこのモデルを当てはめるには、n 行 d 列の行列の応答を調整して、各列が 1 人の被験者に対応するようにします。d 行 K 列の行列の n 長の cell 配列で計画行列を指定します。ここで、K = d + 1 は d の切片と傾き項を表します。
たとえば、d = 4 (4 人の被験者) とします。t 番目の計画行列と対応するパラメーター ベクトルを次の図に示します。
見かけ上無関係な回帰
見かけ上無関係な回帰 (SUR) では、切片と傾きがそれぞれ独自であり、誤差の分散共分散行列が共通している d 個の独立した回帰をモデル化します。たとえば、回帰モデル j = 1,...,d の応答 yij と共変量 xij を、i = 1,...,n 観測を使用して測定し、各回帰を近似するとします。SUR モデルは次のようになります。
ここで
このモデルは、各次元の共変量が異なる点を除き、多変量一般線形モデルに似ています。
mvregress を使用してこのモデルを当てはめるには、n 行 d 列の行列の応答を調整して、各列に j 番目の回帰モデルのデータが含まれるようにします。d 行 K 列の行列の n 長の cell 配列で計画行列を指定します。ここで、K = 2d は d 個の切片と d 個の傾きを表します。
たとえば、d = 3 (3 つの回帰) とします。i 番目の計画行列と対応するパラメーター ベクトルを次の図に示します。
ベクトル自己回帰モデル
VAR(p) ベクトル自己回帰モデルでは、d 次元の時系列応答を、前の時間からの p のラグ d 次元応答の線形関数として表します。たとえば、t = 1,...,n 時点における時系列 j = 1,...,d の応答 ytj を測定するとします。VAR(p) モデルは次のようになります。
ここで
一般に、ベクトル自己回帰モデルを推定する場合は、最初の p 観測値を使用してモデルを開始するか、他の事前標本応答値を用意する必要があります。
mvregress を使用してこのモデルを当てはめるには、n 行 d 列の行列の応答を調整して、各列が 1 つの時系列に対応するようにします。d 行 K 列の行列の n 長の cell 配列で計画行列を指定します。ここでは、K = d + pd2 となります。
たとえば、d = 2 (2 つの時系列) および p = 1 (1 ラグ) とします。t 番目の計画行列と対応するパラメーター ベクトルを次の図に示します。
また、Econometrics Toolbox™ には VAR(p) モデルの当てはめと予測のための関数があり、外因的予測子変数を指定するオプションもあります。