plot
オプションのグループ化によるデータのプロット
説明
plot( は各被験者の反復測定モデル rm)rm の測定値を時間の関数としてプロットします。単一の被験者内数値要因がある場合、plot はこの要因の値を時間値として使用します。それ以外の場合、plot は 1 ~ r の離散値を時間値として使用します (r は反復測定の回数です)。
plot( では、1 つ以上の名前と値の引数を使用して追加オプションを指定します。たとえば、グループ化の基準となる要因を指定したり、線の色を変更することができます。rm,Name,Value)
H = plot(___)H を返します。
例
標本データを読み込みます。
load fisheriris列ベクトル species は、3 種類のアヤメ (setosa、versicolor、virginica) で構成されています。double 行列 meas は、花に関する 4 種類の測定値、がく片の長さと幅 (cm) と花弁の長さと幅 (cm) で構成されています。
データを table 配列に保存します。
t = table(species,meas(:,1),meas(:,2),meas(:,3),meas(:,4),... VariableNames=["species","meas1","meas2","meas3","meas4"]); Meas = table([1 2 3 4]',VariableNames="Measurements");
反復予測モデルを当てはめます。ここで、測定が応答、種類が予測子変数となります。
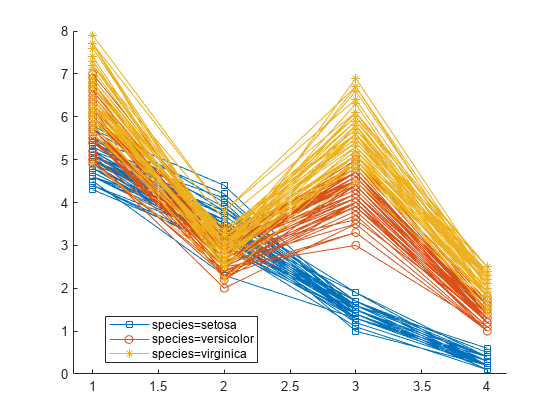
rm = fitrm(t,"meas1-meas4~species",WithinDesign=Meas);因子となる種類ごとにデータをグループ化してプロットします。
plot(rm,"group","species")
各グループのライン スタイルを変更します。
plot(rm,"group","species",LineStyle=["-","--",":"])

標本データを読み込みます。
load repeatedmeasテーブル between には、被験者間変数である年齢、IQ、グループ、性別、および 8 件の反復測定値 y1 ~ y8 が応答として含まれています。テーブル within には被験者内変数 w1 および w2 が含まれています。このデータは、シミュレーションされたものです。
反復測定モデルを当てはめます。ここで、反復測定値 y1 ~ y8 は応答であり、年齢、IQ、グループ、性別、およびグループと性別の交互作用は予測子変数です。また、被験者内計画行列も指定します。
rm = fitrm(between,'y1-y8 ~ Group*Gender + Age + IQ','WithinDesign',within);
Group を色別、Gender をライン タイプ別に区分してデータをプロットします。
plot(rm,'group',{'Group' 'Gender'},'Color','rrbbgg',... 'LineStyle',{'-' ':' '-' ':' '-' ':'},'Marker','.')
