このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
nlmefitsa
確率的な EM アルゴリズムを使用した非線形混合効果モデルの近似
構文
[BETA,PSI,STATS,B] = nlmefitsa(X,Y,GROUP,V,MODELFUN,BETA0)
[BETA,PSI,STATS,B] = nlmefitsa(X,Y,GROUP,V,MODELFUN,BETA0,'Name',Value)
説明
[ は、非線形混合効果の回帰モデルを当てはめ、BETA,PSI,STATS,B] = nlmefitsa(X,Y,GROUP,V,MODELFUN,BETA0)BETA に固定効果の推定を返します。既定の設定では、nlmefitsa は、各モデル パラメーターが対応する固定効果と変量効果の和となり、変量効果の共分散行列が対角行列、すなわち、無相関の変量効果となるモデルを当てはめます。
この関数が返す BETA、PSI、およびその他の値は、パラメーターの最尤推定値に収束するように設計されているランダム (モンテカルロ) シミュレーションの結果です。結果はランダムであるため、結果に対するシミュレーションのプロットを調べて、シミュレーションが収束したことを確認してください。また、複数の開始値を使用して関数を複数回実行したり、'Replicates' パラメーターを使用して複数のシミュレーションを実行することもお勧めします。
[ は、コンマで区切られたパラメーターの名前と値のペアを 1 つまたは複数受け入れます。一重引用符で囲んで BETA,PSI,STATS,B] = nlmefitsa(X,Y,GROUP,V,MODELFUN,BETA0,'Name',Value)Name を指定します。
入力引数
定義
次に示す引数のリストでは、以下の変数定義が適用されます。
n — 観測数
h — 予測子変数の数
m — グループ数
g — グループ固有の予測子変数の数
p — パラメーター数
f — 固定効果の数
| h 個の予測子変数上の n 個の観測の n 行 h 列の行列。 |
| n 行 1 列の応答ベクトル。 |
| m 個のグループのどれに各観測値が属するかを示すグループ化変数。 |
| データ内の m 個のグループごとの g 個のグループ固有の予測子変数の m 行 g 列の行列。これらは、グループ内のすべての観測に対して同じ値を取る予測子値です。 |
| 予測子値とモデル パラメーターを受け入れ、近似値を返す関数のハンドル。
|
| f の固定効果に対する初期推定をもつ f 行 1 列のベクトル。既定の設定では、f はモデル パラメーターの数 p に等しくなります。 |
名前と値の引数
出力引数
| 固定効果の推定。 |
| 変量効果に対する r 行 r 列の推定された共分散行列。既定の設定では、r はモデル パラメーター数 p と等しくなります。 |
| 構造体には次のフィールドがあります。
|
例
標本データを読み込みます。
load indomethacin8 時間にわたり 6 人の被験者の血流内における薬物インドメタシンの濃度に関するデータにモデルを当てはめます。
model = @(phi,t)(phi(:,1).*exp(-phi(:,2).*t)+phi(:,3).*exp(-phi(:,4).*t)); phi0 = [1 1 1 1]; xform = [0 1 0 1]; % log transform for 2nd and 4th parameters [beta,PSI,stats,br] = nlmefitsa(time,concentration, ... subject,[],model,phi0,'ParamTransform',xform)

beta = 4×1
0.8630
-0.7897
2.7762
1.0785
PSI = 4×4
0.0585 0 0 0
0 0.0248 0 0
0 0 0.5068 0
0 0 0 0.0139
stats = struct with fields:
logl: []
aic: []
bic: []
sebeta: []
dfe: 57
covb: []
errorparam: 0.0811
rmse: 0.0772
ires: [66x1 double]
pres: [66x1 double]
iwres: [66x1 double]
pwres: [66x1 double]
cwres: [66x1 double]
br = 4×6
-0.2302 -0.0033 0.1625 0.1774 -0.3334 0.1129
0.0363 -0.1502 0.0071 0.0471 0.0068 -0.0481
-0.7631 -0.0553 0.8780 -0.8120 0.5429 0.1695
-0.0030 -0.0223 0.0192 -0.0830 0.0505 -0.0066
データを母集団全体の当てはめに沿ってプロットします。
figure phi = [beta(1),exp(beta(2)),beta(3),exp(beta(4))]; h = gscatter(time,concentration,subject); xlabel('Time (hours)') ylabel('Concentration (mcg/ml)') title('{\bf Indomethacin Elimination}') xx = linspace(0,8); line(xx,model(phi,xx),'linewidth',2,'color','k')
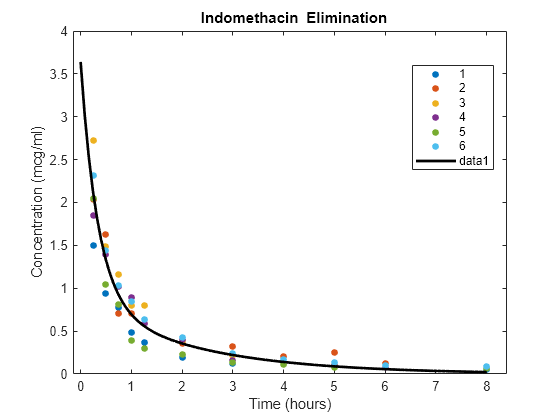
変量効果推定値に基づいて個別曲線をプロットします。
for j=1:6 phir = [beta(1)+br(1,j), exp(beta(2)+br(2,j)), ... beta(3)+br(3,j), exp(beta(4)+br(4,j))]; line(xx,model(phir,xx),'color',get(h(j),'color')) end

アルゴリズム
非線形混合効果モデルのパラメーターを推定するために、尤度関数を最大にするパラメーター値を選択する必要があります。これらの値は、最尤推定値と呼ばれます。尤度関数は、次の形式で記述できます。
ここで
y は、応答データです。
β は、母集団係数のベクトルです。
σ2 は、残差分散です。
∑ は、変量効果に対する共分散行列です。
b は、観測されない変量効果のセットです。
右側の各関数 p() は、共変量因子に応じた正規 (ガウス) 尤度関数です。
積分は閉形式でないため、最大になるパラメーターを見つけることは困難です。Delyon、Lavielle、および Moulines [1] は、E ステップを確率的な手順で置き換える期待値最大化 (EM) アルゴリズムを使用して、最尤推定値を見つけることを提案しています。彼らはこの方法をアルゴリズム SAEM (確率的近似 EM) と名付けました。また、実際条件における収束や尤度関数のローカル最大値への収束など、このアルゴリズムには望ましい理論特性があることを示しました。彼らの提案には、以下の 3 つのステップがあります。
シミュレーション: 現在のパラメーター推定値を前提として事後密度 p(b|Σ) から変量効果 b の値をシミュレートして生成します。
確率近似: 前のステップの値を使用し、シミュレートした変量効果から計算した対数尤度の平均値に近づけて、対数尤度関数の期待値を更新します。
最大化ステップ: シミュレートした変量効果の値を使用して対数尤度関数が最大になるように新しいパラメーター推定値を選択します。
参考文献
[1] Delyon, B., M. Lavielle, and E. Moulines, "Convergence of a stochastic approximation version of the EM algorithm." Annals of Statistics, 27, 94-128, 1999.
[2] Mentré, F., and M. Lavielle, "Stochastic EM Algorithms in Population PKPD analyses." American Conference on Pharmacometrics, 2008.
バージョン履歴
R2010a で導入