mvncdf
多変量正規累積分布関数
構文
説明
例
すべての次元で座標の値を増加させた点で、4 次元の標準多変量正規分布の cdf を評価します。
座標の値が増加する 5 つの 4 次元点が含まれている行列 X を作成します。
firstDim = (-2:2)'; X = repmat(firstDim,1,4)
X = 5×4
-2 -2 -2 -2
-1 -1 -1 -1
0 0 0 0
1 1 1 1
2 2 2 2
X 内の点における cdf を評価します。
p = mvncdf(X)
p = 5×1
0.0000
0.0006
0.0625
0.5011
0.9121
すべての次元で点の座標が増加するので、cdf 値が増加します。
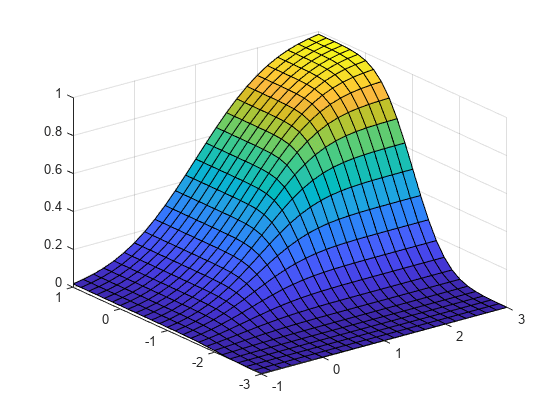
二変量正規分布の cdf を計算してプロットします。
平均ベクトル mu と共分散行列 Sigma を定義します。
mu = [1 -1]; Sigma = [.9 .4; .4 .3];
2 次元平面内に 625 個の点が均等間隔で配置されているグリッドを作成します。
[X1,X2] = meshgrid(linspace(-1,3,25)',linspace(-3,1,25)'); X = [X1(:) X2(:)];
グリッドの点における正規分布の cdf を評価します。
p = mvncdf(X,mu,Sigma);
cdf の値をプロットします。
Z = reshape(p,25,25); surf(X1,X2,Z)
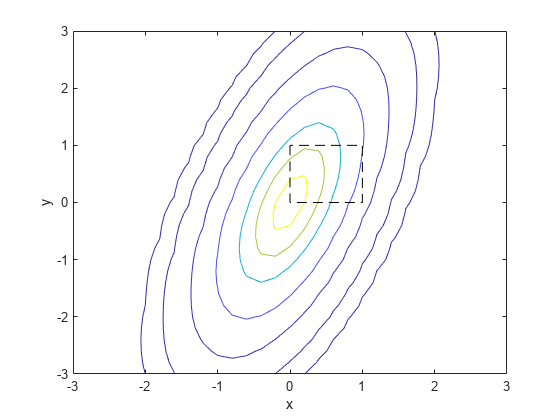
二変量正規分布の単位正方形における確率を計算し、結果の等高線図を作成します。
二変量正規分布のパラメーター mu および Sigma を定義します。
mu = [0 0]; Sigma = [0.25 0.3; 0.3 1];
単位正方形における確率を計算します。
p = mvncdf([0 0],[1 1],mu,Sigma)
p = 0.2097
結果を可視化するため、2 次元平面内に点が均等間隔で配置されているグリッドをはじめに作成します。
x1 = -3:.2:3; x2 = -3:.2:3; [X1,X2] = meshgrid(x1,x2); X = [X1(:) X2(:)];
次に、グリッドの点における正規分布の pdf を評価します。
y = mvnpdf(X,mu,Sigma); y = reshape(y,length(x2),length(x1));
そして、単位正方形が含まれている多変量正規分布の等高線図を作成します。
contour(x1,x2,y,[0.0001 0.001 0.01 0.05 0.15 0.25 0.35]) xlabel('x') ylabel('y') line([0 0 1 1 0],[1 0 0 1 1],'Linestyle','--','Color','k')
多変量累積確率を計算する場合、一変量確率を計算するよりも非常に多くの計算量を必要とします。既定の設定では、関数 mvncdf はマシンの最大精度に満たない値まで計算し、オプションの 2 番目の出力として誤差の推定値を返します。このケースにおける推定誤差を表示します。
[p,err] = mvncdf([0 0],[1 1],mu,Sigma)
p = 0.2097
err = 1.0000e-08
ランダムな点における多変量正規分布の cdf を評価し、cdf の計算に関連する推定誤差を表示します。
平均ベクトル mu および共分散行列 Sigma をもつ 5 次元の多変量正規分布から、4 つのランダムな点を生成します。
mu = [0.5 -0.3 0.2 0.1 -0.4]; Sigma = 0.5*eye(5); rng('default') % For reproducibility X = mvnrnd(mu,Sigma,4);
X 内の点における cdf 値 p と、関連する推定誤差 err を求めます。数値計算の概要を表示します。
[p,err] = mvncdf(X,mu,Sigma,statset('Display','final'))
Successfully satisfied error tolerance of 0.0001 in 8650 function evaluations. Successfully satisfied error tolerance of 0.0001 in 8650 function evaluations. Successfully satisfied error tolerance of 0.0001 in 8650 function evaluations. Successfully satisfied error tolerance of 0.0001 in 8650 function evaluations.
p = 4×1
0.1520
0.0407
0.0002
0.1970
err = 4×1
10-16 ×
0.5949
0.1487
0
0.1983
入力引数
出力引数
詳細
ヒント
1 次元の場合、
Sigmaは標準偏差ではなく分散です。たとえば、mvncdf(1,0,4)はnormcdf(1,0,2)と同じであり、4は分散、2は標準偏差です。
アルゴリズム
二変量分布と三変量分布の場合、mvncdf は、Drezner および Wesolowsky[1][2]と Genz[3]が開発した手法に基づいて、t 密度の変換に適応求積法を使用します。4 次元以上の場合、mvncdf は、Genz と Bretz[4][5]が開発した手法に基づいて、準モンテカルロ積分アルゴリズムを使用します。
参照
[1] Drezner, Z. “Computation of the Trivariate Normal Integral.” Mathematics of Computation. Vol. 63, 1994, pp. 289–294.
[2] Drezner, Z., and G. O. Wesolowsky. “On the Computation of the Bivariate Normal Integral.” Journal of Statistical Computation and Simulation. Vol. 35, 1989, pp. 101–107.
[3] Genz, A. “Numerical Computation of Rectangular Bivariate and Trivariate Normal and t Probabilities.” Statistics and Computing. Vol. 14, No. 3, 2004, pp. 251–260.
[4] Genz, A., and F. Bretz. “Numerical Computation of Multivariate t Probabilities with Application to Power Calculation of Multiple Contrasts.” Journal of Statistical Computation and Simulation. Vol. 63, 1999, pp. 361–378.
[5] Genz, A., and F. Bretz. “Comparison of Methods for the Computation of Multivariate t Probabilities.” Journal of Computational and Graphical Statistics. Vol. 11, No. 4, 2002, pp. 950–971.
[6] Kotz, S., N. Balakrishnan, and N. L. Johnson. Continuous Multivariate Distributions: Volume 1: Models and Applications. 2nd ed. New York: John Wiley & Sons, Inc., 2000.
拡張機能
バージョン履歴
R2006a で導入