meanEffectSize
説明
例
株式収益データを読み込み、平均差効果量を計算する変数を定義します。
load stockreturns
x = stocks(:,1);既定の平均値 0 と比較した株式収益の平均差効果量を計算し、効果量の 95% 信頼区間を計算します。
effect = meanEffectSize(x)
effect=1×2 table
Effect ConfidenceIntervals
________ ______________________
MeanDifference -0.20597 -0.41283 0.00087954
平均差効果量を使用する場合、関数 meanEffectSize は厳密法を使用して信頼区間を推定します。
比較する平均値を指定することもできます。
effect = meanEffectSize(x,Mean=-1)
effect=1×2 table
Effect ConfidenceIntervals
_______ ___________________
MeanDifference 0.79403 0.58717 1.0009
フィッシャーのアヤメのデータを読み込み、中央値差効果量を計算する変数を定義します。
load fisheriris species2 = categorical(species); x = meas(species2=='setosa'); y = meas(species2=='virginica');
2 つの独立した標本から観測値の中央値差効果量を計算します。
effect = meanEffectSize(x,y,Effect="mediandiff")effect=1×2 table
Effect ConfidenceIntervals
______ ___________________
MedianDifference -1.5 -1.8 -1.3
既定では、関数 meanEffectSize は標本が独立している (つまり Paired=false) と仮定します。効果のタイプが中央値差の場合、この関数はブートストラッピングを使用して信頼区間を推定します。
ガードナー-アルトマン プロットを使用して中央値差効果量を可視化します。
gardnerAltmanPlot(x,y,Effect="mediandiff");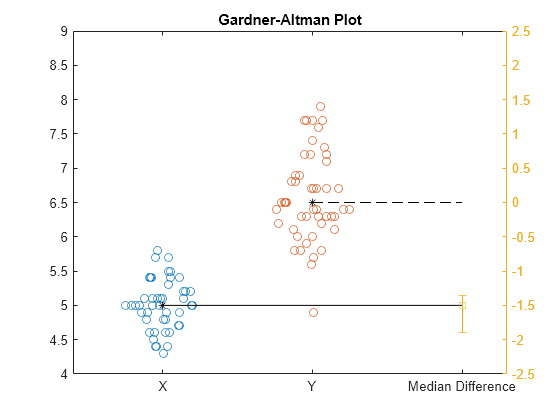
ガードナー-アルトマン プロットの左側に 2 つのデータ標本が表示されます。標本 Y の中央値は、効果量の軸 (右側にある黄色の軸の線) における効果量ゼロに対応します。標本 X の中央値は、効果量の軸における効果量の値に対応します。実際の中央値差効果量の値と信頼区間が垂直方向の誤差範囲と共にプロットに表示されます。
フィッシャーのアヤメのデータを読み込み、Cohen の d 効果量を比較する変数を定義します。
load fisheriris species2 = categorical(species); x = meas(species2=='setosa'); y = meas(species2=='virginica');
2 つの独立した標本から観測値の Cohen の d 効果量を計算し、効果量の 95% 信頼区間を計算します。既定では、効果量のタイプが Cohen の d の場合、meanEffectSize 関数は非心 "t" 分布に基づく厳密な式を使用して信頼区間を推定します。ブートストラッピング オプションを次のように指定します。
meanEffectSizeでの信頼区間の計算にブートストラッピングを使用するように設定します。ブートストラッピングの計算に並列計算を使用します。このオプションには Parallel Computing Toolbox™ が必要です。
3000 のブートストラップ複製を使用します。
rng(123) % For reproducibility effect = meanEffectSize(x,y,Effect="cohen",ConfidenceIntervalType="bootstrap", ... BootstrapOptions=statset(UseParallel=true),NumBootstraps=3000)
effect=1×2 table
Effect ConfidenceIntervals
_______ ___________________
CohensD -3.0536 -3.6232 -2.4073
ガードナー-アルトマン プロットで同じオプションの設定を使用して Cohen の d 効果量を可視化します。
gardnerAltmanPlot(x,y,Effect="cohen",ConfidenceIntervalType="bootstrap", ... BootstrapOptions=statset(UseParallel=true),NumBootstraps=3000);
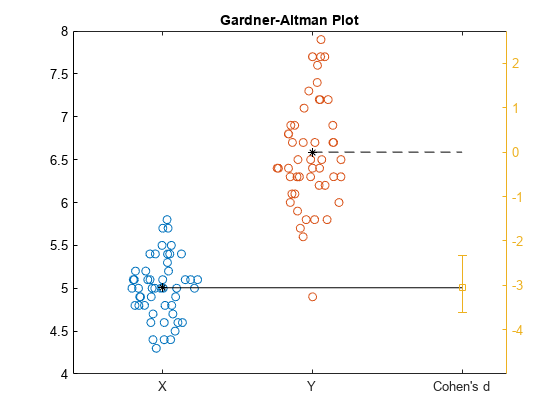
ガードナー-アルトマン プロットの左側に 2 つのデータ標本が表示されます。標本 Y の平均値は、効果量の軸 (右側にある黄色の軸の線) における効果量ゼロに対応します。標本 X の平均値は、効果量の軸における効果量の値に対応します。Cohen の d 効果量の値と信頼区間が垂直方向の誤差範囲と共にプロットに表示されます。
試験採点データを読み込み、比較する変数を定義します。
load examgrades
x = grades(:,1);
y = grades(:,2);標本ペアから採点の平均差効果量を計算し、効果量の 95% 信頼区間を計算します。
effect = meanEffectSize(x,y,Paired=true)
effect=1×2 table
Effect ConfidenceIntervals
________ ___________________
MeanDifference 0.016667 -1.3311 1.3644
平均差効果量を使用する場合、関数 meanEffectSize は厳密法を使用して信頼区間を推定します。
別の効果量のタイプを指定できます。(標本ペアに Glass のデルタは使用できないことに注意してください。) ロバストな Cohen の d を使用して標本ペアの平均値を比較します。効果量の 97% 信頼区間を計算します。
effect = meanEffectSize(x,y,Paired=true,Effect="robustcohen",Alpha=0.03)effect=1×2 table
Effect ConfidenceIntervals
________ ___________________
RobustCohensD 0.059128 -0.1405 0.26573
効果量のタイプがロバストな Cohen の d の場合、関数 meanEffectSize はブートストラッピングを使用して信頼区間を推定します。
ガードナー-アルトマン プロットを使用して効果量を可視化します。ロバストな Cohen の d を効果量として指定し、97% 信頼区間を計算します。
gardnerAltmanPlot(x,y,Paired=true,Effect="robustcohen",Alpha=0.03);
ガードナー-アルトマン プロットの左側にペアになったデータが表示されます。1 つ目の標本の値をペアになった標本の対応する値と比較して、増加している値は青い線、減少している値は赤い線でそれぞれ示されます。プロットの右側に、ロバストな Cohen の d の 97% 信頼区間の効果量が表示されます。
入力引数
名前と値の引数
出力引数
アルゴリズム
参照
[1] Cousineau, Denis, and Jean-Christophe Goulet-Pelletier. "A Study of Confidence Intervals for Cohen's d in Within-Subject Designs with New Proposals." The Quantitative Methods for Psychology 17, no. 1 (March 2021): 51--75. https://doi.org/10.20982/tqmp.17.1.p051.
[2] Algina, James, H. J. Keselman, and R. D. Penfield. "An Alternative to Cohen's Standardized Mean Difference Effect Size: A Robust Parameter and Confidence Interval in the Two Independent Groups Case." Psychological Methods 10, no. 3 (Sept 2005): 317–28. https://doi.org/10.1037/1082-989X.10.3.317.
[3] Hess, Melinda, and Jeffrey Kromrey. "Robust Confidence Intervals for Effect Sizes: A Comparative Study of Cohen's d and Cliff's Delta Under Non-normality and Heterogeneous Variances." Annual Meeting of the American Educational Research Association. 2004.
[4] Delacre, Marie, Daniel Lakens, Christophe Ley, Limin Liu, and Christophe Leys. "Why Hedges G's Based on the Non-pooled Standard Deviation Should Be Reported with Welch's T-test." 2021.
[5] Gardner, M. J., and D. G. Altman. Confidence Intervals Rather Than P Values; Estimation Rather Than Hypothesis Testing." BMJ, 292 no. 6522 (March 1986): 746–50. https://doi.org/10.1136/bmj.292.6522.746.
拡張機能
バージョン履歴
R2022a で導入