kmedoids
k-medoid クラスタリング
構文
説明
idx = kmedoids(X,k)X の観測を k クラスターに分割し、各観測のクラスター インデックスを含む n 行 1 列のベクトル (idx) を返します。X の行は観測に対応し、列は変数に対応します。既定の設定では、kmedoids は初期クラスター medoid 位置の選択に二乗ユークリッド距離計量および k-means++ アルゴリズムを使用します。
idx = kmedoids(X,k,Name,Value)Name,Value 引数のペアによって指定された追加オプションを使用します。
例
データを無作為に生成します。
rng('default'); % For reproducibility X = [randn(100,2)*0.75+ones(100,2); randn(100,2)*0.55-ones(100,2)]; figure; plot(X(:,1),X(:,2),'.'); title('Randomly Generated Data');
kmedoids を使用してデータを 2 つのクラスターにグループ化します。cityblock 距離計量を使用します。
opts = statset('Display','iter'); [idx,C,sumd,d,midx,info] = kmedoids(X,2,'Distance','cityblock','Options',opts);
rep iter sum
1 1 209.856
1 2 209.856
Best total sum of distances = 209.856
info は、アルゴリズムの実行方法に関する情報を含む struct です。たとえば、bestReplicate フィールドは最終的な解を出すために使用される複製を示します。この例では、既定アルゴリズムの場合に既定の複製数が 1 なので、複製番号 1 を使用します。ここでは、pam です。
info
info = struct with fields:
algorithm: 'pam'
start: 'plus'
distance: 'cityblock'
iterations: 2
bestReplicate: 1
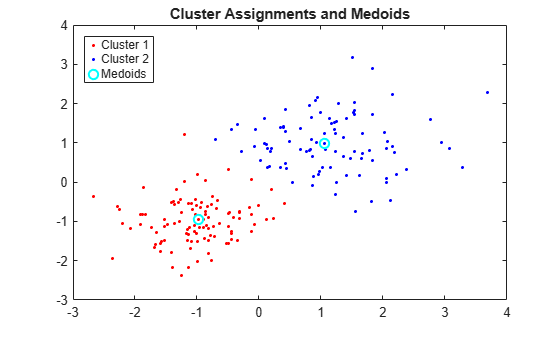
クラスターとクラスター medoid をプロットします。
figure; plot(X(idx==1,1),X(idx==1,2),'r.','MarkerSize',7) hold on plot(X(idx==2,1),X(idx==2,2),'b.','MarkerSize',7) plot(C(:,1),C(:,2),'co',... 'MarkerSize',7,'LineWidth',1.5) legend('Cluster 1','Cluster 2','Medoids',... 'Location','NW'); title('Cluster Assignments and Medoids'); hold off
次の例では、UCI 機械学習アーカイブ[7]の "キノコ" のデータ セット[3][4][5][6][7](詳細についてはhttps://archive.ics.uci.edu/dataset/73/mushroomを参照) を使用します。このデータ セットには、8,124 個のさまざまなキノコの観測値に対する 22 の予測子が含まれています。予測子はカテゴリカル データ型です。たとえば、かさの形状が釣り鐘形の場合は 'b'、円錐形のかさの場合は 'c' の特徴量で分類されます。またキノコの色は、茶色の場合に 'n'、ピンクの場合に 'p' の特徴量で分類されます。データ セットには、各キノコが食用か有毒かの分類も含まれます。
キノコのデータ セットでは特徴量が categorical なので、複数のデータ点の平均を定義できません。また、広く利用されている k-means クラスタリング アルゴリズムをこのデータ セットに有意義に適用することはできません。k-medoid は関連するアルゴリズムで、データ内の点と最も近い medoid の間の非類似度の合計が最小になる medoid を探索することにより、データを k 個の異なるクラスターに分割します。
セットの medoid は、セットの他のメンバーとの平均非類似度が最小のセットのメンバーです。類似度は、平均を計算できない多くの種類のデータに対して定義することができ、k medoid は k-means よりも広い範囲の問題に対して使用できます。
次の例では、k medoid を使用して、指定された予測子に基づき、キノコを 2 つのグループにクラスタリングします。次に、これらのクラスター間の関係と、キノコが食用または有毒かの分類を検索します。
次の例では、UCI データベース (https://archive.ics.uci.edu/dataset/73/mushroom) の "キノコ" のデータ セット[3][4][5][6][7]をダウンロードし、現在のディレクトリにテキスト ファイル agaricus-lepiota.data および agaricus-lepiota.names を保存したと想定しています。データには列ヘッダーの行がありません。したがって readtable は既定の変数名を使用します。
clear all data = readtable('agaricus-lepiota.data','ReadVariableNames',false);
いくつかの最初の特徴によって 5 個のキノコを最初に表示します。
data(1:5,1:10)
ans =
Var1 Var2 Var3 Var4 Var5 Var6 Var7 Var8 Var9 Var10
____ ____ ____ ____ ____ ____ ____ ____ ____ _____
'p' 'x' 's' 'n' 't' 'p' 'f' 'c' 'n' 'k'
'e' 'x' 's' 'y' 't' 'a' 'f' 'c' 'b' 'k'
'e' 'b' 's' 'w' 't' 'l' 'f' 'c' 'b' 'n'
'p' 'x' 'y' 'w' 't' 'p' 'f' 'c' 'n' 'n'
'e' 'x' 's' 'g' 'f' 'n' 'f' 'w' 'b' 'k'最初の列を抽出し、食用および有毒グループのデータをラベル付けします。次に、列を削除します。
labels = data(:,1);
labels = categorical(labels{:,:});
data(:,1) = [];予測子 (特徴量) の名前を格納します。agaricus-lepiota.names に記述されています。
VarNames = {'cap_shape' 'cap_surface' 'cap_color' 'bruises' 'odor' ...
'gill_attachment' 'gill_spacing' 'gill_size' 'gill_color' ...
'stalk_shape' 'stalk_root' 'stalk_surface_above_ring' ...
'stalk_surface_below_ring' 'stalk_color_above_ring' ...
'stalk_color_below_ring' 'veil_type' 'veil_color' 'ring_number' ....
'ring_type' 'spore_print_color' 'population' 'habitat'};変数名を設定します。
data.Properties.VariableNames = VarNames;
'?' として表示される欠損値は合計で 2480 あります。
sum(char(data{:,:}) == '?')ans =
2480データ セットの検査とその説明によると、欠損値は 11 番目の変数 (stalk_root) にのみ属します。テーブルから列を削除します。
data(:,11) = [];
kmedoids は数値データを受け入れるのみです。現在のデータのカテゴリを数値型にキャストします。データの非類似度を定義するために使用する距離関数は、カテゴリカル データの double 表現に基づきます。
cats = categorical(data{:,:});
data = double(cats);kmedoids は、クラスタリングのために pdist2 によってサポートされる任意の距離計量を使用します。次の例では、ハミング距離を使用してデータをクラスタリングします。以下に示すとおり、カテゴリカル データの場合は適切な距離計量であるためです。2 つのベクトル間のハミング距離は、異なるベクトル成分の比率です。たとえば、次の 2 つのベクトルについて考えます。
v1 = [1 0 2 1];
v2 = [1 1 2 1];
第 1、第 3、第 4 座標で等しくなっています。4 座標のうち 1 座標が異なるので、この 2 つのベクトル間のハミング距離は 0.25 です。
関数 pdist2 を使用して、データの 1 行目と 2 行目の間のハミング距離 (キノコのカテゴリカル データの数値表現) を測定できます。値 .2857 は、キノコの 21 の特徴のうち 6 つが異なることを意味します。
pdist2(data(1,:),data(2,:),'hamming')ans =
0.2857次の例では、特徴に基づきキノコのデータを 2 つのクラスターにクラスタリングし、クラスタリングが食用に対応しているか確認します。関数 kmedoids は、クラスタリング基準のローカルな最小値に収束することが保証されています。しかし、これは問題に対してグローバルな最小値ではない可能性があります。'replicates' パラメーターを使用して問題を数回クラスタリングすることをお勧めします。'replicates' が 1 より大きい値 n に設定されている場合、k-medoid アルゴリズムは n 回実行され、最適な結果が返されます。
ハミング距離に基づきデータを 2 つのクラスターにクラスタリングする kmedoids を実行し、3 つの複製に最適な結果を返すには、以下を実行します。
rng('default'); % For reproducibility [IDX, C, SUMD, D, MIDX, INFO] = kmedoids(data,2,'distance','hamming','replicates',3);
予測されたグループ 1 のキノコは有毒で、グループ 2 のキノコはすべて食用であると仮定します。クラスタリングした結果のパフォーマンスを決定するには、グループ 1 の実際に有毒なキノコの数とグループ 2 の食用のキノコの数を既知のラベルに基づき計算します。すなわち、真陽性および真陰性と同様に偽陽性、偽陰性の数を計算します。
混同行列 (またはマッチング行列) を構築します。ここで、対角要素はそれぞれ真陽性および真陰性の数を表します。非対角要素は、それぞれ偽陰性および偽陽性を表します。便宜上、confusionmat 関数を使用することで、既知のラベルおよび予測ラベルが与えられた混同行列を計算します。IDX 変数から予測ラベルの情報を取得します。IDX には各データ点の 1 と 2 の値が含まれ、それぞれ有毒グループおよび食用のグループを表します。
predLabels = labels; % Initialize a vector for predicted labels. predLabels(IDX==1) = categorical({'p'}); % Assign group 1 to be poisonous. predLabels(IDX==2) = categorical({'e'}); % Assign group 2 to be edible. confMatrix = confusionmat(labels,predLabels)
confMatrix =
4176 32
816 31004208 個の食用のキノコのうち 4176 個はグループ 2 (食用のグループ) であると正しく予測されましたが、32 個はグループ 1 (有毒のグループ) であると間違って予測されました。同様に、3916 個の有毒なキノコのうち 3100 個はグループ 1 (有毒のグループ) であると正しく予測され、816 個はグループ 2 (食用のグループ) であると間違って予測されました。
次の混同行列の場合、全体のデータに対する真の結果 (真陽性と真陰性の両方) の比率である正確性と、すべての正の結果 (真陽性と偽陽性) に対する真陽性の比率である精度を計算します。
accuracy = (confMatrix(1,1)+confMatrix(2,2))/(sum(sum(confMatrix)))
accuracy =
0.8956precision = confMatrix(1,1) / (confMatrix(1,1)+confMatrix(2,1))
precision =
0.8365この結果は、キノコのカテゴリカル特徴量に k-medoid アルゴリズムを適用すると、クラスターは食用に関連付けられること示しています。
入力引数
名前と値の引数
出力引数
詳細
参照
[1] Kaufman, L., and Rousseeuw, P. J. (2009). Finding Groups in Data: An Introduction to Cluster Analysis. Hoboken, New Jersey: John Wiley & Sons, Inc.
[2] Park, H-S, and Jun, C-H. (2009). A simple and fast algorithm for K-medoids clustering. Expert Systems with Applications. 36, 3336-3341.
[3] Schlimmer,J.S. (1987). Concept Acquisition Through Representational Adjustment (Technical Report 87-19). Doctoral dissertation, Department of Information and Computer Science, University of California, Irvine.
[4] Iba,W., Wogulis,J., and Langley,P. (1988). Trading off Simplicity and Coverage in Incremental Concept Learning. In Proceedings of the 5th International Conference on Machine Learning, 73-79. Ann Arbor, Michigan: Morgan Kaufmann.
[5] Duch W, A.R., and Grabczewski, K. (1996) Extraction of logical rules from training data using backpropagation networks. Proc. of the 1st Online Workshop on Soft Computing, 19-30, pp. 25-30.
[6] Duch, W., Adamczak, R., Grabczewski, K., Ishikawa, M., and Ueda, H. (1997). Extraction of crisp logical rules using constrained backpropagation networks - comparison of two new approaches. Proc. of the European Symposium on Artificial Neural Networks (ESANN'97), Bruge, Belgium 16-18.
[7] Bache, K. and Lichman, M. (2013). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
拡張機能
バージョン履歴
R2014b で導入
参考
clusterdata | kmeans | linkage | silhouette | pdist | linkage | evalclusters