linkage
凝集型の階層クラスター ツリー
構文
説明
例
20,000 件の観測値をもつ標本データを無作為に生成します。
rng(0,"twister") % For reproducibility X = rand(20000,3);
ward 連結法を使用して階層クラスター ツリーを作成します。このケースでは、既定によりclusterdata関数の SaveMemory オプションが "on" に設定されます。通常は、X の次元数と使用可能メモリに基づいて SaveMemory に最適な値を指定します。
Z = linkage(X,"ward");データを最大 4 つのグループにクラスター化し、結果をプロットします。
c = cluster(Z,MaxClust=4); scatter3(X(:,1),X(:,2),X(:,3),10,c)
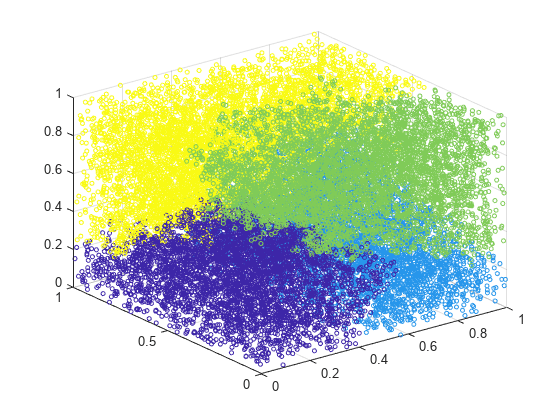
cluster は、データ内のグループを 4 つ識別します。
fisheriris データ セットで最大 3 つのクラスターを求め、花のクラスター割り当てを既知の分類と比較します。
標本データを読み込みます。
load fisheriris"average" 法と "chebychev" 尺度を使用して階層クラスター ツリーを作成します。
Z = linkage(meas,"average","chebychev");
データ内のクラスターを最大 3 つ求めます。
T = cluster(Z,MaxClust=3);
Z のデンドログラム プロットを作成します。3 つのクラスターを表示するため、3 番目から最後までのリンクと 2 番目から最後までのリンクの中間点にカットオフを設定して ColorThreshold を使用します。
cutoff = median([Z(end-2,3) Z(end-1,3)]); dendrogram(Z,ColorThreshold=cutoff,ShowCut=true)
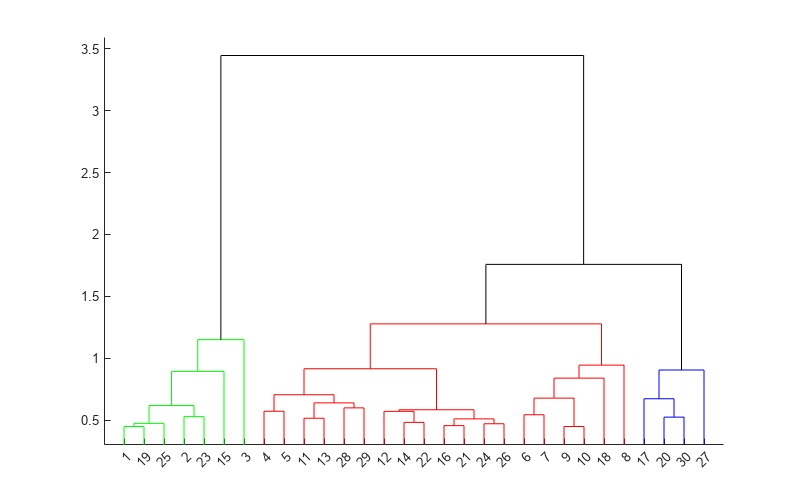
3 つのクラスターがどのようにして 1 つに結合されるかを調べるため、Z の最後の 2 行を表示します。linkage は、293 番目のクラスター (オレンジ) を 297 番目のクラスター (青) と結合し、1.7583 というリンクで 298 番目のクラスターを形成します。そして、linkage は 296 番目のクラスター (赤) を 298 番目のクラスターと結合します。
lastTwo = Z(end-1:end,:)
lastTwo = 2×3
293.0000 297.0000 1.7583
296.0000 298.0000 3.4445
クラスターの割り当てが 3 つの種類に対応しています。たとえば、クラスターの 1 つには、2 番目の種類の花が 50 本、3 番目の種類の花が 40 本含まれています。
crosstab(T,species)
ans = 3×3
0 0 10
0 50 40
50 0 0
examgrades データ セットを読み込みます。
load examgradeslinkage を使用して階層ツリーを作成します。'single' 法と指数が 3 のミンコフスキー計量を使用します。
Z = linkage(grades,'single',{'minkowski',3});
25 番目のクラスタリング手順を観察します。
Z(25,:)
ans = 1×3
86.0000 137.0000 4.5307
linkage は、86 番目の観測値と 137 番目のクラスターを結合して、インデックス のクラスターを形成します。120 は grades 内の観測値の総数、25 は Z の行番号です。86 番目の観測値と 137 番目のクラスター内の任意の点の間の最小距離は 4.5307 です。
非類似度行列を使用して凝集型階層クラスター ツリーを作成します。
非類似度行列として X を使用します。squareform を使用して、linkage が受け入れるベクトル形式にこの行列を変換します。
X = [0 1 2 3; 1 0 4 5; 2 4 0 6; 3 5 6 0]; y = squareform(X);
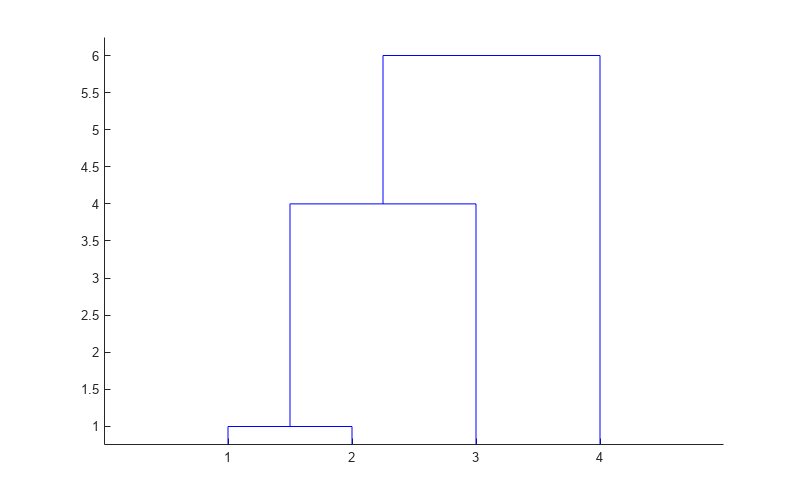
linkage を使用してクラスター ツリーを作成します。'complete' 法でクラスター間の距離を計算します。Z の最初の 2 列は、linkage がどのようにクラスターを結合したかを示します。Z の 3 列目は、クラスター間の距離を与えます。
Z = linkage(y,'complete')Z = 3×3
1 2 1
3 5 4
4 6 6
Z のデンドログラム プロットを作成します。x 軸はツリーの葉ノードに、y 軸はクラスター間のリンク距離に対応します。
dendrogram(Z)
入力引数
出力引数
詳細
ヒント
linkage(y)が距離行列のベクトル表現である場合、yの計算速度が低下する可能性があります。'centroid'、'median'、および'ward'メソッドの場合、linkageはyがユークリッド距離かどうかを確認します。時間のかかるチェックを回避するには、yではなくXを渡してください。'centroid'および'median'メソッドは、単調ではないクラスター ツリーを作成できます。このようになるのは、2 つのクラスター r および s の結合から 3 番目のクラスターまでの距離が r と s の間の距離より小さい場合です。この場合、既定の方向に描画したデンドログラムでは、葉からルート ノードへのパスは下向きになります。これを回避するには、別の方法を使用してください。次の図に非単調のクラスター ツリーを示します。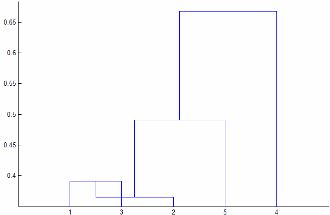
この場合、クラスター 1 とクラスター 3 が結合され新しいクラスターになっていて、この新しいクラスターとクラスター 2 の間の距離はクラスター 1 とクラスター 3 の間の距離よりも短くなっています。これは、非単調なツリーになります。
ツリーを表示する関数
dendrogram、クラスターに点を割り当てる関数cluster、不整合の程度を計算する関数inconsistentおよびコーフェン相関係数を計算する関数cophenetなどを含む、その他の関数に出力Zを提供することができます。
バージョン履歴
R2006a より前に導入
参考
cluster | clusterdata | cophenet | dendrogram | inconsistent | kmeans | pdist | silhouette | squareform