cluster
リンケージによる凝集型クラスターの構築
説明
T = cluster(Z,Cutoff=cutoff)Z からクラスターを定義します。入力 Z は、入力データ行列 X に対する linkage 関数の出力です。cluster は、ツリー内のノードの不整合係数 (または inconsistent の値) のしきい値として cutoff を使用して、Z をクラスターに分割します。出力 T には、各観測値 (X の行) のクラスター割り当てが格納されます。
T = cluster(___,Name=Value)cluster(Z,MaxClust=5,Depth=3) と指定します。
例
各ノードで深さ 4 まで不整合値を評価することにより、無作為に生成したデータに対して凝集型クラスタリングを実行します。
標本データを無作為に生成します。
rng(0,"twister"); % For reproducibility X = [(randn(20,2)*0.75)+1; (randn(20,2)*0.25)-1];
データの散布図を作成します。
scatter(X(:,1),X(:,2));
title("Randomly Generated Data");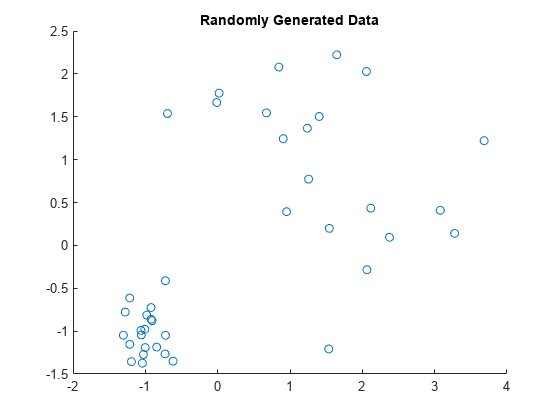
ward 連結法を使用して階層クラスター ツリーを作成します。
Z = linkage(X,"ward");データのデンドログラム プロットを作成します。
dendrogram(Z)

散布図とデンドログラム プロットでは、データに 2 つのクラスターがあるように見えます。
不整合係数のしきい値として 3 を使用し、各ノードで深さ 4 まで調べることにより、データをクラスター化します。生成されたクラスターをプロットします。
T = cluster(Z,Cutoff=3,Depth=4); gscatter(X(:,1),X(:,2),T)

cluster は、データ内のクラスターを 2 つ識別します。
クラスターを定義する基準として "distance" を使用することにより、fisheriris データ セットに対して凝集型クラスタリングを実行します。データのクラスター割り当てを可視化します。
fisheriris データ セットを読み込みます。
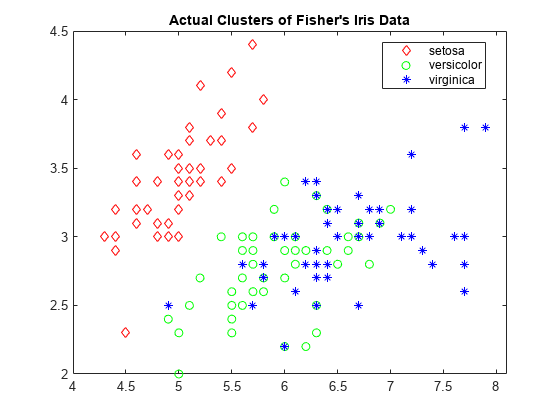
load fisheriris種をグループ化変数として使用して、データの 2 次元散布図を可視化します。3 つの異なる種についてマーカーの色と記号を指定します。
gscatter(meas(:,1),meas(:,2),species,"rgb","do*") title("Actual Clusters of Fisher's Iris Data")
"average" 法と "chebychev" 尺度を使用して階層クラスター ツリーを作成します。
Z = linkage(meas,"average","chebychev");
"distance" 基準のしきい値として 1.5 を使用して、データをクラスター化します。
T = cluster(Z,Cutoff=1.5,Criterion="distance")T = 150×1
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
⋮
T には、クラスター割り当てに対応する番号が格納されます。cluster が識別したクラス数を求めます。
length(unique(T))
ans = 3
cluster は、指定された値の cutoff および Criterion に対して 3 つのクラスを識別します。
T をグループ化変数として使用して、クラスター化の結果の 2 次元散布図を可視化します。3 つの異なるクラスについてマーカーの色と記号を指定します。
gscatter(meas(:,1),meas(:,2),T,"rgb","do*") title("Cluster Assignments of Fisher's Iris Data")

クラスター化により、setosa クラス (クラス 2) は独立したクラスターに属するように正しく識別されますが、versicolor クラス (クラス 1) と virginica クラス (クラス 3) の区別は不十分です。散布図におけるクラスのラベル付けには T に格納されている番号が使用されることに注意してください。
fisheriris データ セットで最大 3 つのクラスターを求め、花のクラスター割り当てを既知の分類と比較します。
標本データを読み込みます。
load fisheriris"average" 法と "chebychev" 尺度を使用して階層クラスター ツリーを作成します。
Z = linkage(meas,"average","chebychev");
データ内のクラスターを最大 3 つ求めます。
T = cluster(Z,MaxClust=3);
Z のデンドログラム プロットを作成します。3 つのクラスターを表示するため、3 番目から最後までのリンクと 2 番目から最後までのリンクの中間点にカットオフを設定して ColorThreshold を使用します。
cutoff = median([Z(end-2,3) Z(end-1,3)]); dendrogram(Z,ColorThreshold=cutoff,ShowCut=true)
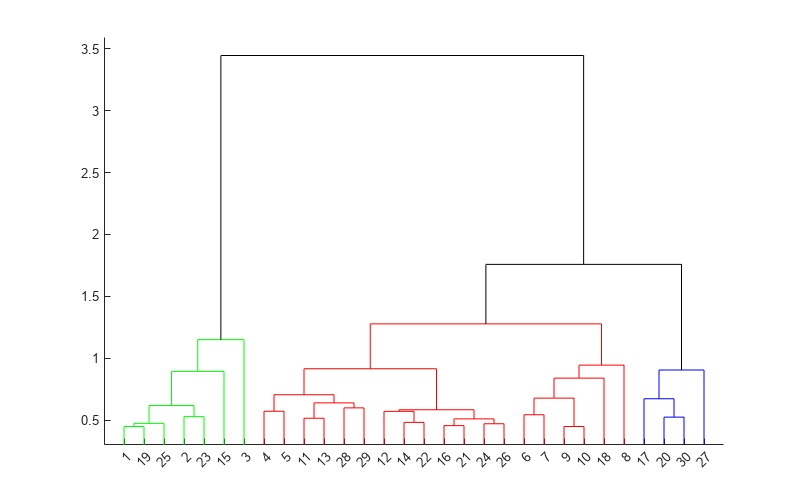
3 つのクラスターがどのようにして 1 つに結合されるかを調べるため、Z の最後の 2 行を表示します。linkage は、293 番目のクラスター (オレンジ) を 297 番目のクラスター (青) と結合し、1.7583 というリンクで 298 番目のクラスターを形成します。そして、linkage は 296 番目のクラスター (赤) を 298 番目のクラスターと結合します。
lastTwo = Z(end-1:end,:)
lastTwo = 2×3
293.0000 297.0000 1.7583
296.0000 298.0000 3.4445
クラスターの割り当てが 3 つの種類に対応しています。たとえば、クラスターの 1 つには、2 番目の種類の花が 50 本、3 番目の種類の花が 40 本含まれています。
crosstab(T,species)
ans = 3×3
0 0 10
0 50 40
50 0 0
20,000 件の観測値をもつ標本データを無作為に生成します。
rng(0,"twister") % For reproducibility X = rand(20000,3);
ward 連結法を使用して階層クラスター ツリーを作成します。このケースでは、既定によりclusterdata関数の SaveMemory オプションが "on" に設定されます。通常は、X の次元数と使用可能メモリに基づいて SaveMemory に最適な値を指定します。
Z = linkage(X,"ward");データを最大 4 つのグループにクラスター化し、結果をプロットします。
c = cluster(Z,MaxClust=4); scatter3(X(:,1),X(:,2),X(:,3),10,c)
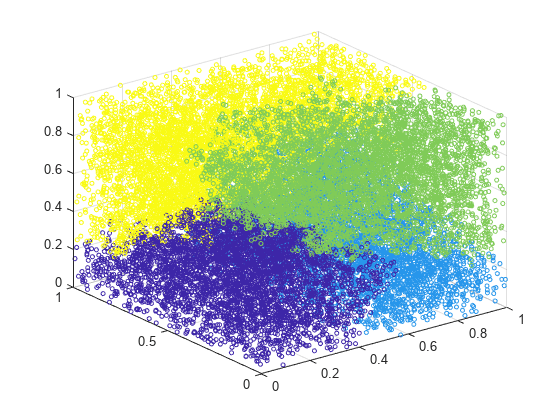
cluster は、データ内のグループを 4 つ識別します。
入力引数
名前と値の引数
出力引数
代替機能
入力データ行列 X がある場合、clusterdata を使用すると、凝集型クラスタリングを実行して、X 内の各観測値 (行) のクラスター インデックスを取得できます。関数 clusterdata は必要な手順をすべて実行するので、関数 pdist、linkage および cluster を個別に実行する必要はありません。