機械学習アプリからエクスポートされたモデルを使用したコマンド ラインでのコード生成
分類学習器アプリと回帰学習器アプリは、機械学習モデルを対話的に選択して学習させるのに適しており、コードを生成するための方法がいくつか用意されています。アプリでモデルに学習させた後、[エクスポート] セクションの [関数の生成] ボタンを使用して、新しいデータでモデルに学習させるための MATLAB コードをコマンド ラインで生成できます。モデルの C/C++ コードを生成できるように、[モデルのエクスポート] ボタンから使用可能な [モデルを Coder にエクスポート] オプションにより、学習させたモデルがアプリから MATLAB® Coder™ にエクスポートされます。
アプリによる MATLAB Coder へのエクスポートは、すべてのモデル タイプについてサポートされているわけではありません。また、場合によっては、コード生成オプションをカスタマイズすることもあります。そのような状況では、saveLearnerForCoder 関数、loadLearnerForCoder 関数、および codegen (MATLAB Coder) 関数を使用して、学習済みアプリ モデルの C/C++ コードを MATLAB コマンド ラインで生成する必要があります。
この例では、分類学習器からエクスポートされた分類モデルを使用して、ラベルを予測する関数から C コードを生成する方法を示します。回帰学習器からエクスポートされたモデルを使用する場合もプロセスは同じです。この例では、以下の手順に従って、与えられた各種の財務比率から会社の信用格付けを予測するモデルを構築します。
Statistics and Machine Learning Toolbox™ に含まれているファイル
CreditRating_Historical.dat内の信用格付けデータ セットを使用します。主成分分析 (PCA) を使用して、データの次元を削減します。
ラベル予測についてコード生成をサポートする一連のモデルに学習をさせます。
5 分割交差検証以上の分類精度をもつモデルをエクスポートします。
エントリポイント関数から C コードを生成します。この関数では、新しい予測子データを変換してから、エクスポート済みのモデルを使用して対応するラベルを予測します。
標本データの読み込み
標本データを読み込み、データを分類学習器アプリにインポートします。散布図を使用してデータを確認し、不要な予測子を削除します。
readtable を使用して、ファイル CreditRating_Historical.dat 内の過去の信用格付けデータ セットを table に読み込みます。
creditrating = readtable('CreditRating_Historical.dat');
[アプリ] タブで [分類学習器] をクリックします。
分類学習器の [分類学習器] タブで、[ファイル] セクションの [新規セッション] をクリックし、[ワークスペースから] を選択します。
[ワークスペースからの新規セッション] ダイアログ ボックスで table creditrating を選択します。応答として認識されたものを除くすべての変数は倍精度数値ベクトルです。[セッションの開始] をクリックして 5 分割交差検証の分類精度に基づき、分類モデルを比較します。
分類学習器がデータを読み込み、変数 WC_TA および ID の散布図をプロットします。識別番号はプロットに表示しても有用ではないので、[予測子] の [X] に RE_TA を選択します。
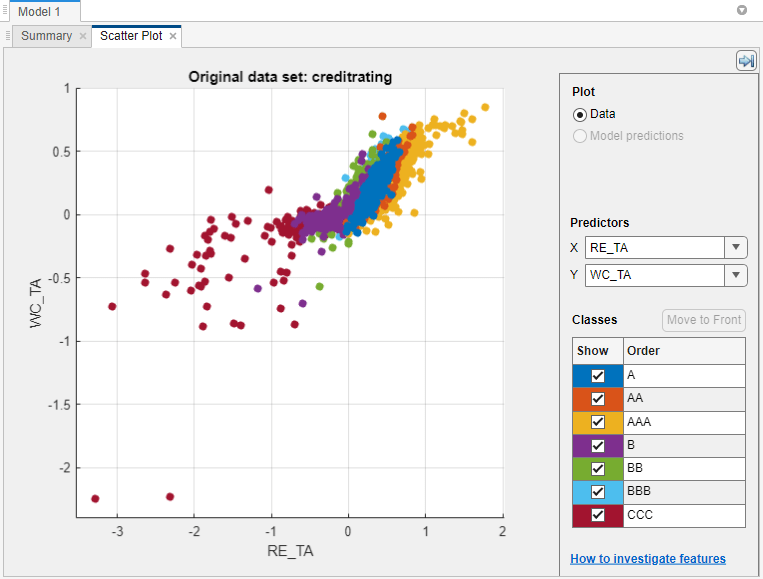
散布図は、2 つの変数がクラス AAA、BBB、BB および CCC をかなり良好に分類できることを示しています。しかし、残りのクラスに対応する観測値は、これらのクラスに混ざっています。
識別番号は予測に有用ではありません。したがって、[分類学習器] タブの [オプション] セクションで [特徴選択] をクリックします。[既定の特徴選択] タブで、[ID] チェック ボックスの選択を解除して [保存して適用] をクリックします。[ワークスペースからの新規セッション] ダイアログ ボックスのチェック ボックスを使用して、不要な予測子をはじめから削除することもできます。この例では、すべての予測子を含めた場合に、コード生成には使用されない予測子を削除する方法を示します。
PCA の有効化
データの次元を削減するため、PCA を有効にします。
[分類学習器] タブの [オプション] セクションで [PCA] をクリックします。[既定の PCA オプション] ダイアログ ボックスで、[主成分分析を有効化] を選択して [保存して適用] をクリックします。これにより PCA が予測子データに適用され、モデルに学習をさせる前にデータが変換されます。分類学習器は、変動性の 95% を総体として説明する成分のみを使用します。
モデルの学習
ラベル予測についてコード生成をサポートする一連のモデルに学習をさせます。コード生成をサポートする分類学習器のモデルの一覧については、Export Classification Model to MATLAB Coder to Generate C/C++ Codeを参照してください。
以下の分類モデルおよびオプションを選択します。これらはラベル予測用のコード生成をサポートします。その後、交差検証を実施します (詳細は統計と機械学習の関数のコード生成の紹介を参照)。各モデルを選択するには、[モデル] セクションで [さらに表示] の矢印をクリックしてからモデルをクリックします。
| 選択するモデルおよびオプション | 説明 |
|---|---|
| [決定木] で [すべての木] を選択 | さまざまな複雑度の分類木 |
| [サポート ベクター マシン] で [すべての SVM] を選択 | さまざまな複雑度でさまざまなカーネルを使用する SVM。複雑な SVM では当てはめに時間が必要。 |
| [アンサンブル分類器] で [ブースティング木] を選択。モデルの [概要] タブの [モデルのハイパーパラメーター] で [最大分割数] を [5] に減らし [学習器の数] を [100] に増やす。 | 分類木のブースティング アンサンブル |
| [アンサンブル分類器] で [バギング木] を選択。モデルの [概要] タブの [モデルのハイパーパラメーター] で [最大分割数] を [50] に減らし [学習器の数] を [100] に増やす。 | 分類木のランダム フォレスト |
モデルを選択してオプションを指定したら、既定の複雑な木のモデル (モデル 1) を削除します。[モデル] ペインでモデルを右クリックして [削除] を選択します。次に、[学習] セクションで、[すべてを学習] をクリックして [すべてを学習] を選択します。
アプリによる各モデル タイプの交差検証後、各モデルおよびその 5 分割交差検証による分類精度が [モデル] ペインに表示されます。アプリで、精度が最も高いモデルの [精度 (検証)] の値が四角で囲まれて強調表示されます。
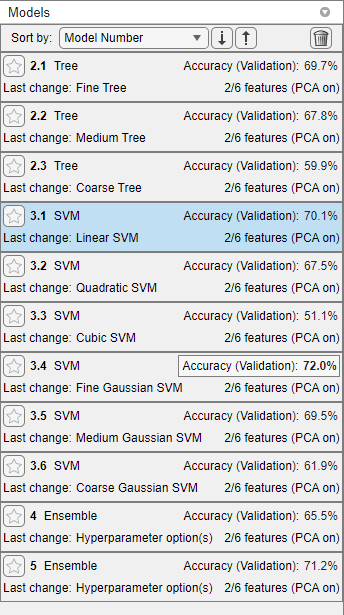
5 分割交差検証による分類精度が最も高いモデル (細かいガウス SVM 学習器の誤り訂正出力符号 (ECOC) モデル) を選択します。PCA を有効にすると、分類学習器は 6 つの予測子のうち 2 つを使用します。
[プロットと解釈] セクションで矢印をクリックしてギャラリーを開き、[検証結果] グループの [混同行列 (検証)] をクリックします。
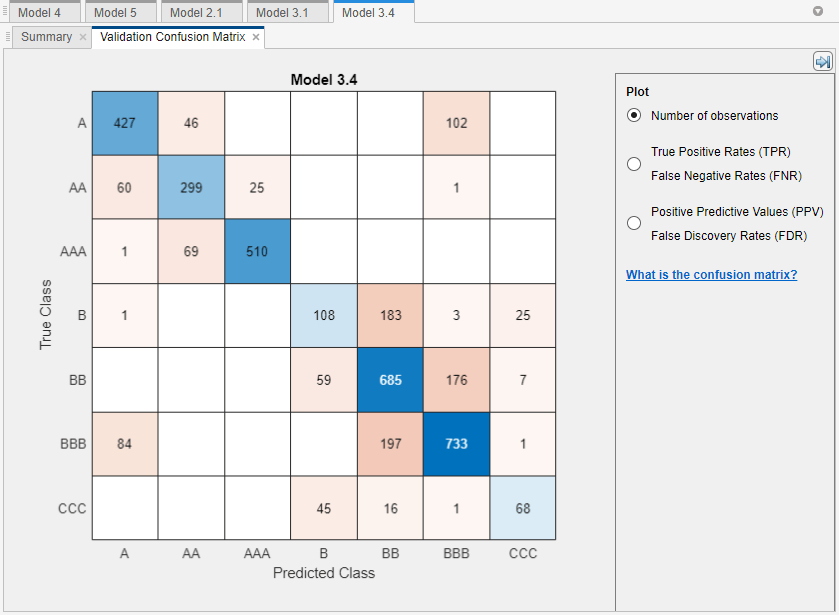
このモデルは、クラス A、B および C を良好に識別します。ただし、これらのグループ内の特定のレベル、特に下の B レベル間では識別が不十分です。
ワークスペースへのモデルのエクスポート
モデルを MATLAB ワークスペースにエクスポートし、saveLearnerForCoder を使用してモデルを保存します。
[分類学習器] タブで、[エクスポート] をクリックして [モデルのエクスポート] をクリックし、[モデルのエクスポート] を選択します。[分類モデルのエクスポート] ダイアログ ボックスでチェック ボックスをクリアして、エクスポートするモデルから学習データを除外します。[OK] をクリックしてコンパクトなモデルをエクスポートします。
構造体 trainedModel が MATLAB のワークスペースに現れます。trainedModel の ClassificationSVM フィールドにコンパクト モデルが含まれています。
コマンド ラインで、現在のフォルダーの ClassificationLearnerModel.mat という名前のファイルにコンパクト モデルを保存します。
saveLearnerForCoder(trainedModel.ClassificationSVM,'ClassificationLearnerModel')予測用の C コードの生成
オブジェクト関数を使用する予測には学習済みのモデル オブジェクトが必要ですが、codegen (MATLAB Coder) の -args オプションはこのようなオブジェクトを受け入れません。saveLearnerForCoder と loadLearnerForCoder を使用して、この制限に対処します。saveLearnerForCoder を使用して、学習済みモデルを保存します。次に、loadLearnerForCoder を使用して保存済みモデルを読み込んで関数 predict を呼び出す、エントリポイント関数を定義します。最後に、codegen を使用して、エントリポイント関数のコードを生成します。
データの前処理
学習データの場合と同じ方法で新しいデータの前処理を行います。
前処理を行うには、次の 3 つのモデル パラメーターが必要です。
removeVars— データから削除する変数のインデックスを識別する、最大でp個の要素がある列ベクトル。pは生データ内の予測子変数の個数pcaCenters— 厳密にq個の PCA の中心から成る行ベクトルpcaCoefficients—q行r列の PCA 係数行列。rは最大でq
分類学習器で [特徴選択] を使用してデータを選択するときに削除した予測子変数のインデックスを指定します。PCA 統計量を trainedModel から抽出します。
removeVars = 1; pcaCenters = trainedModel.PCACenters; pcaCoefficients = trainedModel.PCACoefficients;
モデル パラメーターを現在のフォルダーの ModelParameters.mat という名前のファイルに保存します。
save('ModelParameters.mat','removeVars','pcaCenters','pcaCoefficients');
エントリポイント関数の定義
エントリポイント関数は、コード生成用に定義する関数です。codegen を使用して最上位レベルの関数を呼び出すことはできないので、コード生成に対応する関数を呼び出すエントリポイント関数を定義し、codegen を使用してエントリポイント関数の C/C++ コードを生成しなければなりません。
現在のフォルダー内に、以下を行う mypredictCL.m という名前の関数を定義します。
分類学習器に渡したものと同じ予測子変数が含まれている、生の観測値の数値行列 (
X) を受け入れるClassificationLearnerModel.mat内の分類モデルとModelParameters.mat内のモデル パラメーターを読み込むremoveVars内のインデックスに対応する予測子変数を削除する分類学習器によって推定された PCA の中心 (
pcaCenters) と係数 (pcaCoefficients) を使用して、残りの予測子データを変換するモデルを使用して予測したラベルを返す。
function label = mypredictCL(X) %#codegen %MYPREDICTCL Classify credit rating using model exported from %Classification Learner % MYPREDICTCL loads trained classification model (SVM) and model % parameters (removeVars, pcaCenters, and pcaCoefficients), removes the % columns of the raw matrix of predictor data in X corresponding to the % indices in removeVars, transforms the resulting matrix using the PCA % centers in pcaCenters and PCA coefficients in pcaCoefficients, and then % uses the transformed data to classify credit ratings. X is a numeric % matrix with n rows and 7 columns. label is an n-by-1 cell array of % predicted labels. % Load trained classification model and model parameters SVM = loadLearnerForCoder('ClassificationLearnerModel'); data = coder.load('ModelParameters'); removeVars = data.removeVars; pcaCenters = data.pcaCenters; pcaCoefficients = data.pcaCoefficients; SVM = loadLearnerForCoder('ClassificationLearnerModel'); % Remove unused predictor variables keepvars = 1:size(X,2); idx = ~ismember(keepvars,removeVars); keepvars = keepvars(idx); XwoID = X(:,keepvars); % Transform predictors via PCA Xpca = bsxfun(@minus,XwoID,pcaCenters)*pcaCoefficients; % Generate label from SVM label = predict(SVM,Xpca); end
コードの生成
C および C++ は静的な型の言語なので、エントリポイント関数内のすべての変数のプロパティをコンパイル時に決定しなければなりません。coder.typeof (MATLAB Coder) を使用して可変サイズの引数を指定し、この引数を使用してコードを生成します。
coder.typeof (MATLAB Coder) を使用して、コード生成用の x という名前の倍精度行列を作成します。x の行数が任意であり x の列数が p であることを指定します。
p = size(creditrating,2) - 1; x = coder.typeof(0,[Inf,p],[1 0]);
可変サイズの引数の指定に関する詳細については、機械学習モデルのコード生成用の可変サイズ引数の指定を参照してください。
mypredictCL.m から MEX 関数を生成します。-args オプションを使用して、x を引数として指定します。
codegen mypredictCL -args x
codegen は MEX ファイル mypredictCL_mex.mexw64 を現在のフォルダーに生成します。ファイルの拡張子はプラットフォームによって異なります。
生成されたコードの確認
予期されるラベルを MEX 関数が返すことを確認します。
応答変数を元のデータ セットから削除し、15 個の観測値を無作為に抽出します。
rng('default'); % For reproducibility m = 15; testsampleT = datasample(creditrating(:,1:(end - 1)),m);
分類学習器によって学習をさせた分類モデルで predictFcn を使用して、対応するラベルを予測します。
testLabels = trainedModel.predictFcn(testsampleT);
生成された table を行列に変換します。
testsample = table2array(testsampleT);
testsample の列は、分類学習器で読み込んだ予測子データの列に対応します。
テスト データを mypredictCL に渡します。関数 mypredictCL は、分類学習器で学習をさせた分類モデルと predict を使用して、対応するラベルを予測します。
testLabelsPredict = mypredictCL(testsample);
生成された MEX 関数 mypredictCL_mex を使用して、対応するラベルを予測します。
testLabelsMEX = mypredictCL_mex(testsample);
予測子のセットを比較します。
isequal(testLabels,testLabelsMEX,testLabelsPredict)
ans = logical 1
すべての入力が等しい場合、isequal は logical 1 (true) を返します。predictFcn、mypredictCL、および MEX 関数は同じ値を返します。
参考
loadLearnerForCoder | saveLearnerForCoder | coder.typeof (MATLAB Coder) | codegen (MATLAB Coder) | learnerCoderConfigurer