cvloss
分類木モデルの交差検証による分類誤差
説明
E = cvloss(tree,Name=Value)
例
既定の分類木について交差検証誤差を計算します。
ionosphere データ セットを読み込みます。
load ionosphereデータ セット全体を使用して分類木を成長させます。
Mdl = fitctree(X,Y);
交差検証誤差を計算します。
rng(1); % For reproducibility
E = cvloss(Mdl)E = 0.1140
E は 10 分割の誤分類誤差です。
k 分割の交差検証を適用して、すべての部分木について最適な分類木の枝刈りレベルを探索します。
ionosphere データ セットを読み込みます。
load ionosphereデータ セット全体を使用して分類木を成長させます。生成された木を表示します。
Mdl = fitctree(X,Y); view(Mdl,'Mode','graph')
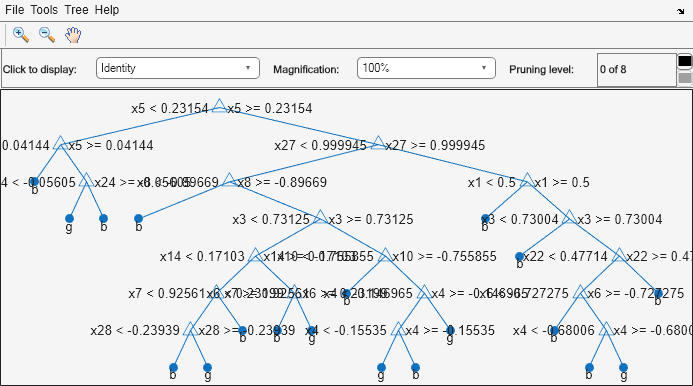
最大の枝刈りレベルを除く各部分木について、5 分割の交差検証誤差を計算します。すべての部分木で最適な枝刈りレベルを返すように指定します。
rng(1); % For reproducibility
m = max(Mdl.PruneList) - 1m = 7
[E,~,~,bestLevel] = cvloss(Mdl,'Subtrees',0:m,'KFold',5)
E = 8×1
0.1282
0.1254
0.1225
0.1282
0.1282
0.1197
0.0997
0.1738
bestLevel = 6
7 個の枝刈りレベルの中で、最適な枝刈りレベルは 6 です。
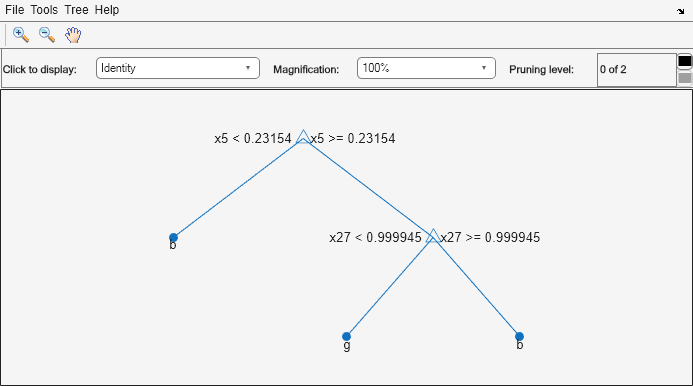
最適なレベルまで木を枝刈りします。生成された木を表示します。
MdlPrune = prune(Mdl,'Level',bestLevel); view(MdlPrune,'Mode','graph')
入力引数
名前と値の引数
出力引数
代替方法
crossval を使用して交差検証ツリーのモデルを構築し、cvloss の代わりに kfoldLoss を呼び出すことができます。交差検証を行った木を複数回調べる場合、この代替方法では時間が節約できる可能性があります。
しかし、cvloss と異なり、kfoldLoss は SE、Nleaf および BestLevel を返しません。また、kfoldLoss では分類誤差以外の誤差を調べることはできません。
拡張機能
バージョン履歴
R2011a で導入
参考
fitctree | crossval | loss | kfoldLoss | ClassificationTree