margin
ガウス カーネル分類モデルの分類マージン
説明
例
ionosphere データ セットを読み込みます。このデータ セットには、レーダー反射についての 34 個の予測子と、不良 ('b') または良好 ('g') という 351 個の二項反応が含まれています。
load ionosphereデータ セットを学習セットとテスト セットに分割します。テスト セット用に 30% のホールドアウト標本を指定します。
rng('default') % For reproducibility Partition = cvpartition(Y,'Holdout',0.30); trainingInds = training(Partition); % Indices for the training set testInds = test(Partition); % Indices for the test set
学習セットを使用してバイナリ カーネル分類モデルに学習をさせます。
Mdl = fitckernel(X(trainingInds,:),Y(trainingInds));
学習セットのマージンとテストセットのマージンを推定します。
mTrain = margin(Mdl,X(trainingInds,:),Y(trainingInds)); mTest = margin(Mdl,X(testInds,:),Y(testInds));
箱ひげ図を使用して、両方のマージンのセットをプロットします。
boxplot([mTrain; mTest],[zeros(size(mTrain,1),1); ones(size(mTest,1),1)], ... 'Labels',{'Training set','Test set'}); title('Training-Set and Test-Set Margins')
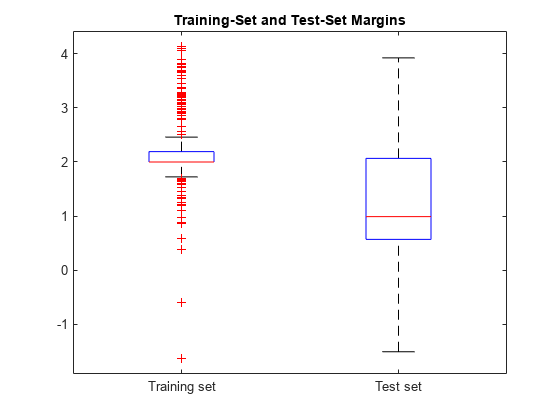
学習セットのマージン分布はテスト セットのマージン分布より高い位置にあります。
複数のモデルによるテストセットのマージンを比較することにより、特徴選択を実行します。この基準のみに基づくと、マージンが大きい方が分類器として優れています。
ionosphere データ セットを読み込みます。このデータ セットには、レーダー反射についての 34 個の予測子と、不良 ('b') または良好 ('g') という 351 個の二項反応が含まれています。
load ionosphereデータ セットを学習セットとテスト セットに分割します。テスト セット用に 15% のホールドアウト標本を指定します。
rng('default') % For reproducibility Partition = cvpartition(Y,'Holdout',0.15); trainingInds = training(Partition); % Indices for the training set XTrain = X(trainingInds,:); YTrain = Y(trainingInds); testInds = test(Partition); % Indices for the test set XTest = X(testInds,:); YTest = Y(testInds);
予測子変数の 10% を無作為に選択します。
p = size(X,2); % Number of predictors
idxPart = randsample(p,ceil(0.1*p));2 つのバイナリ カーネル分類モデルに学習をさせます。1 つではすべての予測子を、もう 1 つではランダムな 10% の予測子を使用します。
Mdl = fitckernel(XTrain,YTrain); PMdl = fitckernel(XTrain(:,idxPart),YTrain);
Mdl および PMdl は ClassificationKernel モデルです。
各分類器についてテストセットのマージンを推定します。
fullMargins = margin(Mdl,XTest,YTest); partMargins = margin(PMdl,XTest(:,idxPart),YTest);
箱ひげ図を使用して、マージン セットの分布をプロットします。
boxplot([fullMargins partMargins], ... 'Labels',{'All Predictors','10% of the Predictors'}); title('Test-Set Margins')
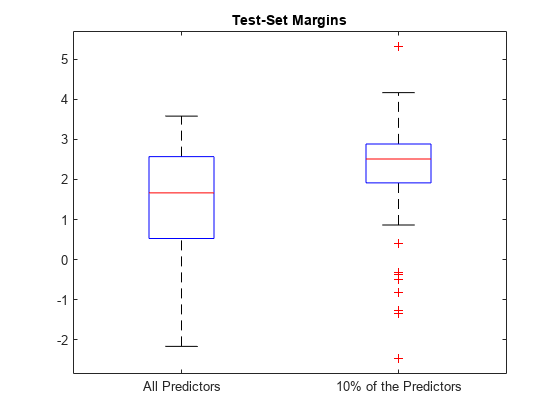
PMdl のマージン分布は Mdl のマージン分布より高い位置にあります。したがって、PMdl モデルの方が優れた分類器です。