回帰学習器におけるモデルの性能の可視化と評価
回帰学習器アプリで回帰モデルに学習させた後で、モデルのメトリクスに基づくモデルの比較、応答プロットまたは予測応答と実際の応答のプロットによる結果の可視化、残差プロットによるモデルの評価を行うことができます。
"k" 分割交差検証を使用した場合、"k" 個の検証分割内の観測値を結合したセットを使用してモデルのメトリクス (平方根平均二乗誤差 (RMSE) など) が計算されます。検証分割内の観測値に対する予測が行われ、その予測がプロットに表示されます。検証分割内の観測値を使用して残差も計算されます。
データをアプリにインポートすると、既定では自動的に交差検証が使用されます。別の検証方式を選択するには、Select Validation Scheme in Classification Learner or Regression Learnerを参照してください。
ホールドアウト検証を使用した場合、検証セット内の観測値を使用して予測が行われ、モデルのメトリクスが計算されます。その予測がプロットで使用され、予測に基づいて残差の計算も行われます。
再代入検証を使用した場合、完全なモデルの学習に使用したものと同じ学習データ セットを使用して予測が行われ、モデルのメトリクスが計算されます。
[モデル] ペインにおける性能のチェック
回帰学習器でモデルに学習をさせた後で、[モデル] ペインをチェックして、どのモデルの総合スコアが最適かを調べます。[RMSE (検証)] が最高のスコアは、ボックスで強調表示されます。このスコアは検証セットの平方根平均二乗誤差 (RMSE) です。新しいデータに対する学習済みモデルの性能をスコアによって推定できます。このスコアは、最適なモデルの選択に役立ちます。

総合スコアが最高でも、目標に最適なモデルではないことがあります。総合スコアがわずかに低いモデルが目標に最適なモデルである場合もあります。過適合を回避するため、データ収集が高価または困難である予測子のいくつかを除外することが考えられます。
[概要] タブと [モデル] ペインでのモデル メトリクスの表示
モデル メトリクスをモデルの [概要] タブおよび [モデル] ペインに表示し、これらのメトリクスを使用してモデルの評価と比較を行うことができます。代わりに、結果の比較プロットと [結果テーブル] タブを使用してモデルを比較することもできます。詳細については、結果の比較プロットでのモデル情報と結果の表示とテーブル ビューでのモデル情報と結果の比較を参照してください。
[学習結果] のメトリクスは検証セットに対して計算されます。[テスト結果] のメトリクス (表示される場合) はテスト セットに対して計算されます。詳細については、Test Trained Models in Classification Learner or Regression Learnerを参照してください。
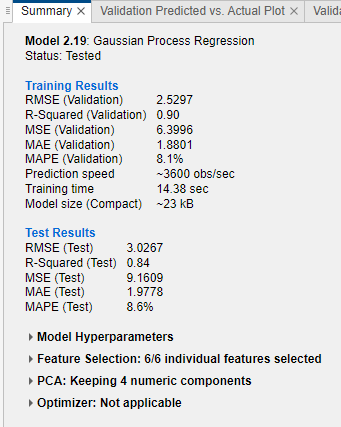
モデル メトリクス
| 統計 | 説明 | ヒント |
|---|---|---|
| RMSE | 平方根平均二乗誤差。RMSE は常に正であり、単位は応答の単位に一致します。 | 値が小さい RMSE を探します。 |
| 決定係数 (R2) | 決定係数。通常の (自由度未調整) R2 の値が計算されます。R2 は常に 1 より小さく、通常は 0 より大きくなります。学習済みモデルを、応答が一定で学習応答の平均に等しいモデルと比較します。この定数モデルよりモデルが劣っている場合、R2 は負になります。R2 統計量は、ほとんどの非線形回帰モデルにとって役立つメトリクスではありません。詳細については、Rsquared を参照してください。 | 1 に近い R2 の値を探します。 |
| MSE | 平均二乗誤差。MSE は RMSE の 2 乗です。 | 値が小さい MSE を探します。 |
| MAE | 平均絶対誤差。MAE は常に正であり、RMSE に似ていますが、外れ値の影響は少なくなります。 | 値が小さい MAE を探します。 |
| MAPE | 平均絶対誤差率。MAPE は常に非負であり、予測誤差の応答との比較を示します。詳細については、平均絶対誤差率を参照してください。 | 値が小さい MAPE を探します。 |
| 予測速度 | 検証データ セットの予測時間に基づく新しいデータの推定予測速度 | この推定にはアプリの内外のバックグラウンド処理が影響する可能性があるため、より正しい比較のために同様の条件でモデルに学習させます。 |
| 学習時間 | モデルの学習の所要時間 | この推定にはアプリの内外のバックグラウンド処理が影響する可能性があるため、より正しい比較のために同様の条件でモデルに学習させます。 |
| モデル サイズ (コンパクト) | 機械学習モデル オブジェクトをコンパクトなモデル (つまり学習データなし) としてエクスポートした場合のサイズ。モデルをワークスペースにエクスポートすると、エクスポートされた構造体にはモデル オブジェクトと追加フィールドが含まれます。アプリで表示されるモデル オブジェクトのサイズ (バイト数) は whos 関数から返されるものです。learnersize 関数では、モデル オブジェクトで gather を呼び出してから whos を呼び出すため、一部のモデル タイプについて異なるサイズが返される場合があることに注意してください。 | ターゲット アプリケーションのメモリ要件に合ったモデル サイズの値を探します。 |
| モデル サイズ (Coder) | MATLAB® Coder™ で生成される C/C++ コードでのモデルの概算サイズ (バイト数)。アプリで表示されるサイズ (バイト数) は type="coder" を指定した learnersize 関数から返されるものです。コード生成でサポートされていないモデル タイプについては、Coder のモデル サイズは NaN になります。 | サポートされているモデル タイプの一覧については、Export Regression Model to MATLAB Coder to Generate C/C++ Codeを参照してください。 |
[モデル] ペインでは、さまざまなモデル メトリクスに基づいてモデルを並べ替えることができます。並べ替えに使用するメトリクスを選択するには、[モデル] ペインの上部にある [並べ替え] リストを使用します。[モデル] ペインでのモデルの並べ替えに、すべてのメトリクスを使用できるわけではありません。[結果テーブル] では、他のメトリクスでもモデルを並べ替えることができます (テーブル ビューでのモデル情報と結果の比較を参照)。
[モデル] ペインにリストされている不要なモデルの削除もできます。削除するモデルを選択してペインの右上にある [選択したモデルの削除] ボタンをクリックするか、モデルを右クリックして [削除] を選択します。[モデル] ペインに最後に残ったモデルは削除できません。
テーブル ビューでのモデル情報と結果の比較
[概要] タブまたは [モデル] ペインを使用してモデル メトリクスを比較する代わりに、結果のテーブルを使用できます。[学習] タブの [プロットと結果] セクションで [結果テーブル] をクリックします。[結果テーブル] タブでは、モデルを学習やテストの結果のほか、それらのオプション (モデル タイプ、選択した特徴、PCA など) で並べ替えることもできます。たとえば、モデルを平方根平均二乗誤差で並べ替えるには、[RMSE (検証)] 列ヘッダーの並べ替え矢印をクリックします。上向き矢印は、RMSE が最も低いモデルから RMSE が最も高いモデルの順に並べ替えられていることを示します。
テーブルの列のオプションをさらに表示するには、テーブルの右上にある [表示する列の選択] ボタン  をクリックします。[表示する列の選択] ダイアログ ボックスで、結果テーブルに表示する列のボックスをオンにします。新しく選択した列はテーブルの右側に追加されます。
をクリックします。[表示する列の選択] ダイアログ ボックスで、結果テーブルに表示する列のボックスをオンにします。新しく選択した列はテーブルの右側に追加されます。
結果テーブル内でテーブルの列を手動でドラッグ アンド ドロップして、希望する順序で表示することができます。
[お気に入り] 列を使用して、いくつかのモデルをお気に入りとしてマークできます。お気に入りのモデルの選択内容は、結果テーブルと [モデル] ペインで一致するように維持されます。他の列と異なり、[お気に入り] 列と [モデル番号] 列はテーブルから削除できません。
テーブルから行を削除するには、行内のいずれかのエントリを右クリックし、[行を非表示] (行が強調表示されている場合は [選択した行を非表示]) をクリックします。連続する行を削除するには、削除する最初の行内のいずれかのエントリをクリックし、Shift キーを押して、削除する最後の行内のいずれかのエントリをクリックします。次に、強調表示されたエントリのいずれかを右クリックし、[選択した行を非表示] をクリックします。削除したすべての行を元に戻すには、テーブル内のいずれかのエントリを右クリックし、[すべての行を表示] をクリックします。復元された行はテーブルの一番下に追加されます。
テーブルの情報をエクスポートするには、テーブルの右上にあるいずれかのエクスポート ボタン  を使用します。テーブルをワークスペースとファイルのどちらにエクスポートするかを選択します。エクスポートしたテーブルには、表示されている行と列のみが含まれます。
を使用します。テーブルをワークスペースとファイルのどちらにエクスポートするかを選択します。エクスポートしたテーブルには、表示されている行と列のみが含まれます。
結果の比較プロットでのモデル情報と結果の表示
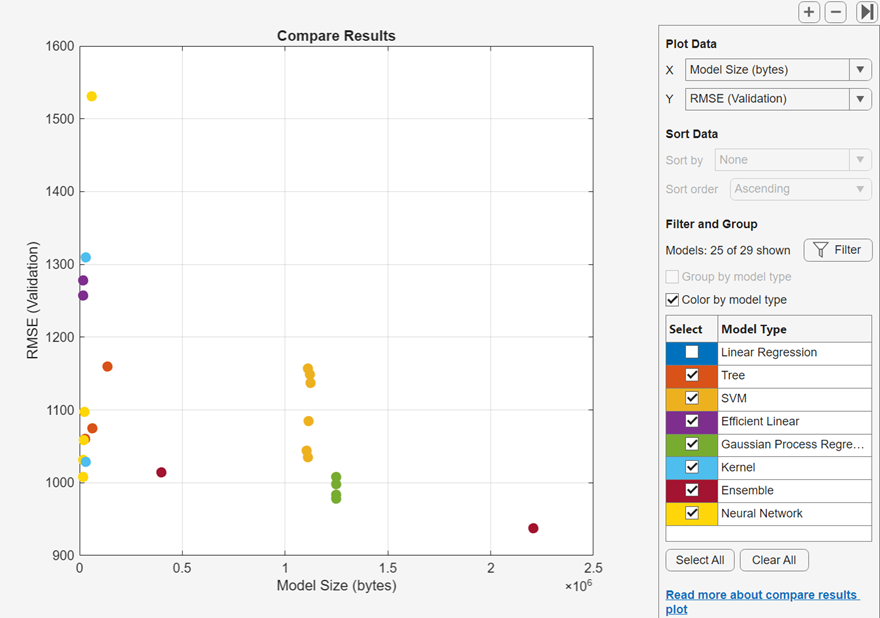
結果の比較プロットでモデル情報と結果を表示できます。[学習] タブまたは [テスト] タブの [プロットと結果] セクションで [結果の比較] をクリックします。あるいは、[結果テーブル] タブの [結果のプロット] ボタンをクリックします。プロットには、モデルの検証 RMSE の棒グラフが、RMSE 値の低いものから順に表示されます。[データの並べ替え] の [並べ替え] リストを使用して、モデルを他の学習やテストの結果で並べ替えることができます。同じタイプのモデルをグループ化するには、[モデル タイプでグループ化] を選択します。すべてのモデル タイプに同じ色を割り当てるには、[モデル タイプ別に色を指定] をオフにします。
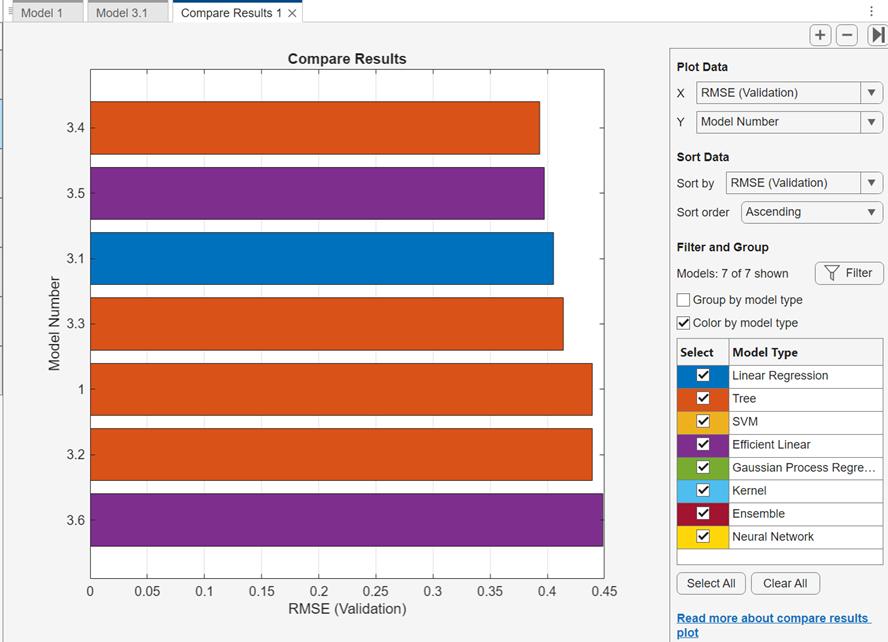
表示するモデル タイプを選択するには、[選択] のチェック ボックスを使用します。表示されているモデルを非表示にするには、プロット内の棒を右クリックして [モデルを非表示] を選択します。
[フィルターの適用とグループ化] の [フィルター] ボタンをクリックし、表示されているモデルを選択してフィルターを適用することもできます。[モデルのフィルター適用と選択] ダイアログ ボックスで、[メトリクスの選択] をクリックし、ダイアログ ボックスの上部にあるモデルのテーブルに表示するメトリクスを選択します。テーブル内でテーブルの列をドラッグして、希望する順序で表示できます。テーブルを並べ替えるには、テーブル ヘッダーの並べ替え矢印をクリックします。メトリクス値によるフィルターをモデルに適用するには、まず、[フィルター] 列でメトリクスを選択します。次に、[モデルへのフィルター適用] テーブルで条件を選択し、[値] フィールドに値を入力して、[フィルターの適用] をクリックします。モデルのテーブルで、選択内容が更新されます。追加の条件を指定するには、[フィルターの追加] ボタンをクリックします。[OK] をクリックして、更新されたプロットを表示します。
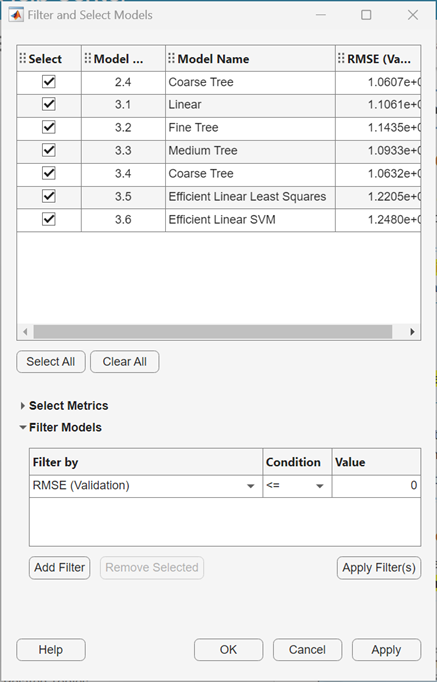
[データのプロット] の [X] と [Y] のリストで、プロットする他のメトリクスを選択します。[X] または [Y] で Model Number を選択しない場合は、散布図が表示されます。
結果の比較プロットを Figure にエクスポートするには、回帰学習器アプリのプロットのエクスポートを参照してください。
結果テーブルをワークスペースにエクスポートするには、[プロットのエクスポート] をクリックして [プロット データのエクスポート] を選択します。必要な場合は、エクスポートする変数の名前を [結果メトリクス プロット データのエクスポート] ダイアログ ボックスで編集します。[OK] をクリックします。結果テーブルを含む構造体配列が作成されます。
応答プロットにおけるデータと結果の確認
応答プロットを使用して回帰モデルの結果を確認します。応答プロットには、予測された応答とレコード番号が表示されます。回帰モデルに学習させた後、そのモデルの応答プロットがアプリで自動的に開きます。"すべて" のモデルに学習させた場合は、最初のモデルの応答プロットのみが開きます。別のモデルの応答プロットを表示するには、[モデル] ペインでモデルを選択します。[学習] タブの [プロットと結果] セクションで矢印をクリックしてギャラリーを開き、[検証結果] グループの [応答] をクリックします。ホールドアウト検証または交差検証を使用している場合、予測された応答の値はホールドアウトされた (検証) 観測値に対する予測です。つまり、ソフトウェアでは、対応する観測値を使用せずに学習させたモデルを使用して各予測値を取得します。
結果を調べるには、右にあるコントロールを使用します。次が可能です。
予測された応答および/または真の応答をプロットします。[プロット] のチェック ボックスを使用して選択を行います。
[誤差] チェック ボックスを選択すると、予測された応答と真の応答の間の垂直線として予測誤差が表示されます。
x 軸にプロットする変数を [X 軸] で選択します。レコード番号またはいずれかの予測子変数を選択できます。
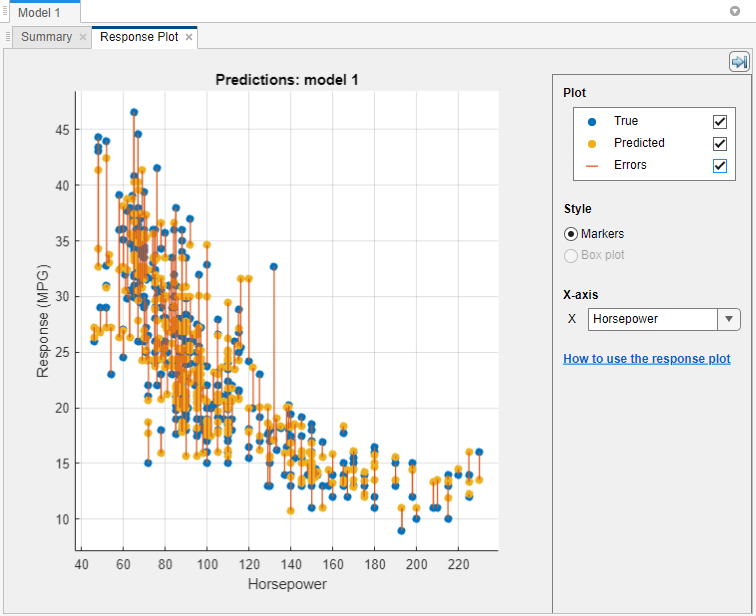
[スタイル] で応答をマーカーまたは箱ひげ図としてプロットします。[箱ひげ図] を選択できるのは、x 軸の変数に一意な値がほとんど含まれていない場合だけです。
箱ひげ図には、応答の代表的な値と外れ値の可能性がある値が表示されます。中央の印は中央値を、ボックスの上下の端はそれぞれ 25 番目と 75 番目の百分位数を示します。垂直線はひげと呼ばれ、ボックスから、外れ値とは見なされない最も極端なデータ点まで伸びます。外れ値は
"o"記号を使用して個別にプロットされます。箱ひげ図の詳細については、boxchartを参照してください。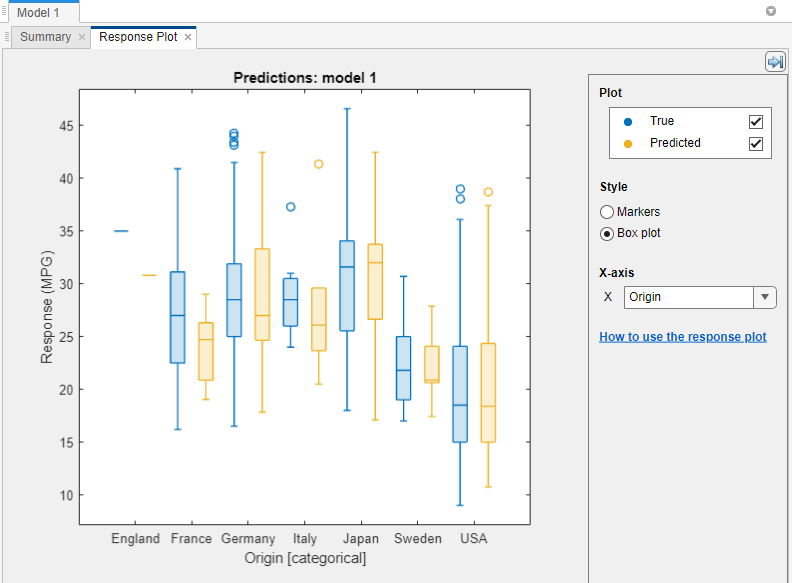
アプリで作成した応答プロットを Figure にエクスポートする方法については、回帰学習器アプリのプロットのエクスポートを参照してください。
予測された応答と実際の応答のプロット
予測と実際のプロットを使用してモデルの性能をチェックします。このプロットを使用して、異なる応答値について回帰モデルがどの程度適切に予測を行うかを調べます。モデルに学習させた後で予測と実際のプロットを表示するには、[プロットと結果] セクションで矢印をクリックしてギャラリーを開き、[検証結果] グループの [予測と実際 (検証)] をクリックします。
プロットを開くと、モデルの予測された応答が実際の真の応答に対してプロットされます。完璧な回帰モデルでは、予測された応答が真の応答と等しくなるので、すべての点が対角線上に配置されます。この線から点までの垂直距離は、その点についての予測誤差です。優れたモデルは誤差が小さく、予測が対角線の近くに分布します。
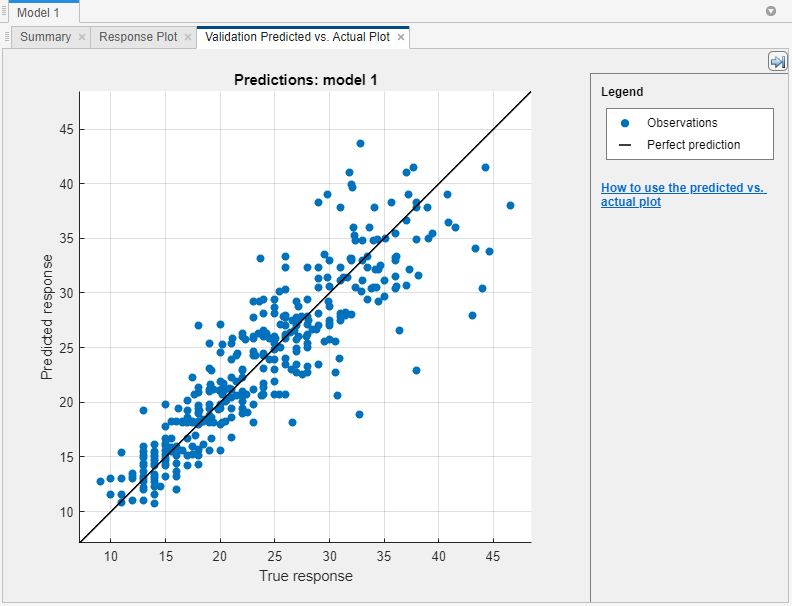
通常、優れたモデルでは点が対角線の近くでほぼ対称的に配置されます。プロットに明確なパターンがある場合、モデルを改善できる可能性があります。別のモデル タイプに学習させるか、モデルを複製してからモデルの [概要] タブの [モデルのハイパーパラメーター] オプションを使用して現在のモデル タイプをより柔軟にします。モデルを改善できない場合は、さらにデータが必要であるか、重要な予測子が欠けている可能性があります。
アプリで作成した予測と実際のプロットを Figure にエクスポートする方法については、回帰学習器アプリのプロットのエクスポートを参照してください。
残差プロットの使用によるモデルの評価
残差プロットを使用してモデルの性能をチェックします。モデルに学習させた後で残差プロットを表示するには、[プロットと結果] セクションで矢印をクリックしてギャラリーを開き、[検証結果] グループの [残差 (検証)] をクリックします。残差プロットには、予測された応答と真の応答の差が表示されます。x 軸にプロットする変数を [X 軸] で選択します。真の応答、予測された応答、レコード番号、またはいずれかの予測子を選択します。
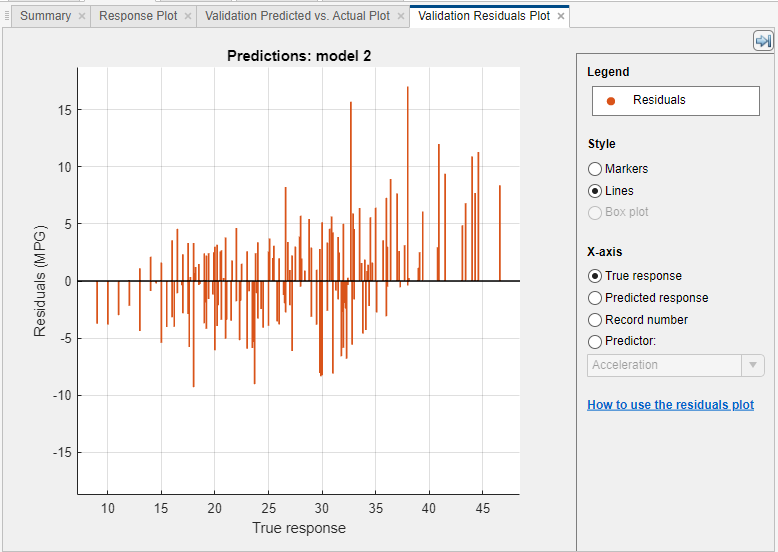
通常、優れたモデルでは残差が 0 の近くでほぼ対称的に配置されます。残差に明確なパターンがある場合、モデルを改善できる可能性があります。次のようなパターンを探します。
0 の近くで対称的になっている残差ではない。
プロットの左から右に残差のサイズが大きく変化している。
外れ値がある。つまり、他の残差よりはるかに大きい残差がある。
明確な非線形パターンが残差にある。
別のモデル タイプに学習させるか、モデルを複製してからモデルの [概要] タブの [モデルのハイパーパラメーター] オプションを使用して現在のモデル タイプをより柔軟にします。モデルを改善できない場合は、さらにデータが必要であるか、重要な予測子が欠けている可能性があります。
アプリで作成した残差プロットを Figure にエクスポートする方法については、回帰学習器アプリのプロットのエクスポートを参照してください。
レイアウトの変更によるモデル プロットの比較
[学習] タブの [プロットと結果] セクションのプロット オプションを使用して、回帰学習器で学習させたモデルの結果を可視化します。プロットのレイアウトを再編成して複数のモデルの結果を比較できます。[レイアウト] ボタンのオプションを使用するか、プロットをドラッグ アンド ドロップするか、モデル プロットのタブの右にある [ドキュメント アクション] ボタン  に表示されるオプションを選択します。
に表示されるオプションを選択します。
たとえば、回帰学習器で 2 つのモデルに学習させた後、次のいずれかの手順を使用して、各モデルのプロットを表示し、プロットのレイアウトを変更してプロットを比較します。
[プロットと結果] セクションで [レイアウト] をクリックし、[モデルの比較] を選択します。
2 つ目のモデルのタブ名をクリックし、2 つ目のモデルのタブを右にドラッグ アンド ドロップします。
モデル プロットのタブの右端にある [ドキュメント アクション] ボタン
をクリックします。[すべて並べて表示]オプションを選択し、1 行 2 列のレイアウトを指定します。
プロットの右上にある [プロット オプションを非表示] ボタン  をクリックするとプロットのスペースを大きくできることに注意してください。
をクリックするとプロットのスペースを大きくできることに注意してください。
テスト データ セットを使用したモデルの性能の評価
回帰学習器でモデルに学習させた後、アプリでテスト データ セットにおけるモデルの性能を評価できます。詳細については、Test Trained Models in Classification Learner or Regression Learnerを参照してください。