モデル アーキテクチャの理解
プロジェクトのモデリング ガイドラインを評価する場合は、機能/サブ機能レイヤー、スケジュール レイヤー、制御フロー レイヤー、セクション レイヤー、データ フロー レイヤーなど、コントローラー モデルのアーキテクチャを理解することが重要です。
コントローラー モデルの階層構造
この節では、コントローラー モデルを例に使用して、基本モデルにおける階層構造の概要を説明します。以下の表に、階層におけるレイヤーの概念の定義を示します。
| レイヤー概念 | レイヤーの目的 | |
上位 レイヤー | 機能レイヤー | 広範囲の機能の分割 |
| スケジュール レイヤー | 実行タイミング (サンプリング、注文) の表現 | |
下位 レイヤー | サブ機能レイヤー | 詳細な機能の分割 |
| 制御フロー レイヤー | 処理順序 (入力 → 判断 → 出力など) に従った分割 | |
| 選択レイヤー | アクティブとなるサブシステムを切り替えてアクティブにする形式に分割 ([マージ] で出力を選択) | |
| データ フロー レイヤ | 分割できない 1 つの計算を実行するレイヤー |
レイヤー概念を適用する場合は、次に注意します。
レイヤー概念はレイヤーに割り当て、それに応じてサブステムを分割します。
レイヤー概念が必要ない場合、レイヤーに割り当てる必要はありません。
複数のレイヤー概念を 1 つのレイヤーに割り当てることができます。
階層を作成する場合は、レイヤー内のスペースを節約する目的でサブシステムに分割しないでください。
上位レイヤー
上位レイヤーのレイアウト方法は、次のとおりです。
簡易な制御モデル — 機能レイヤーとスケジュール レイヤーの両方を同じレイヤーで表します。ここでは、機能が実行単位です。たとえば、制御モデルのサンプリング サイクルは 1 つだけで、すべての機能が実行順に配置されています。
複雑な制御モデル タイプ α — スケジュール レイヤーが最上位に配置されます。この方法では、コードとの統合が容易ですが、機能は分割され、モデルの可読性が低下します。
複雑な制御モデル タイプ β — 機能レイヤーが最上位に配置され、スケジュール レイヤーは個々の機能レイヤーの下位に配置されます。

機能レイヤーとサブ機能レイヤー
機能レイヤーとサブ機能レイヤーをモデル化する場合は、次のようにします。
サブシステムは機能別に分割し、各サブシステムは 1 つの機能を表します。
1 つの機能は必ずしも実行単位ではないため、個々のサブシステムは必ずしも Atomic サブシステムにはなりません。以下のタイプ β では、機能レイヤー サブシステムをバーチャル サブシステムにするのが適しています。これらを Atomic サブシステムに変更すると、代数ループが作成されます。
個々の機能単位を記述します。
モデルに複数の大きい機能が含まれる場合は、各機能のモデル参照を使用してモデルを分割することを検討します。

スケジュール レイヤー
スケジュール レイヤーを使用する場合は、以下のようにします。
システムのサンプリング間隔と実行の優先順位を設定します。複数のサンプリング間隔を設定するときは注意が必要です。異なるサンプリング間隔のシステムが接続されている場合、システムがサンプリング間隔ごとに分割されているか確認します。これにより、信号値の処理が高速サイクルと低速サイクルで異なる場合に、前の値を保存するために必要な RAM が最小化されます。
優先順位ランクを設定します。これは、複数の独立した機能を設計する場合に重要です。可能な場合は、サブシステムの接続に基づいてすべてのサブシステムの計算順序を指定しなければなりません。
2 種類の優先順位ランクを設定し、1 つは異なるサンプリング間隔用、もう 1 つは同一のサンプリング レート用にします。
サンプリング間隔と優先順位ランクを設定するために使用できる次の 2 種類の方法があります。
サブシステムとブロックの場合は、ブロック パラメーター [サンプル時間] とブロック プロパティ [優先順位] を設定します。
条件付きサブシステムを使用する場合は、スケジューラに対応する独立した優先順位ランクを設定します。
コンフィギュレーション パラメーターのカスタム サンプリング間隔、Atomic サブシステム設定、モデル参照の使用など、多くの異なる条件のパターンが存在します。特定のパターンの使用は、コードの実装方法に密接に関連し、プロジェクトのステータスに応じて大きく異なります。通常影響を受けるモデルは次のとおりです。
複数のサンプリング間隔を含むモデル
複数の独立した機能を含むモデル
モデル参照の使用の有無
モデルの数 (および生成されたコードのセットが複数あるかどうか)
生成されたコードの場合、影響を受ける要素は次のとおりです。
リアルタイム オペレーティング システムの適用の有無
使用可能なサンプリング間隔と、実装される計算サイクルの整合性
適用可能な領域 (アプリケーション ドメインまたは基本ソフトウェア)
ソース コード タイプ: AUTOSAR 準拠 - 非準拠 - 非サポート。
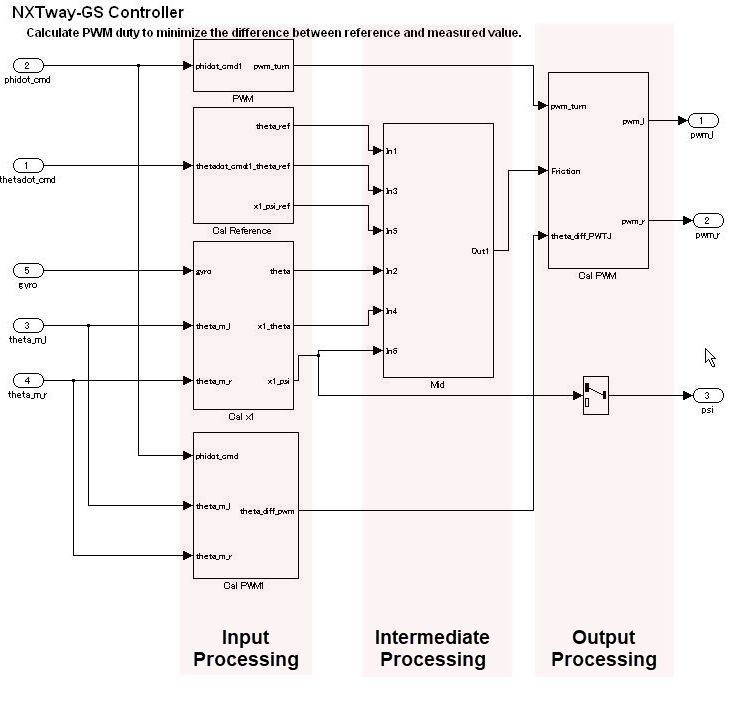
制御フロー レイヤー
階層内では、制御レイヤーはすべての入力処理、中間処理、および出力処理を 1 つの機能を使用して表します。このレイヤーではブロックとサブシステムの配置が重要です。複数の、混在する小さな機能は、制御の概念的基盤を形成する、入力処理、中間処理、および出力処理の 3 つの大きな段階に分割してグループ化しなければなりません。一般的な構成はデータ フロー レイヤーの近くで行われ、水平線で表されます。サブシステム データ フロー レイヤーとの違いは、複数のサブシステムとブロックで構成されている点です。
制御フロー レイヤーでは、水平方向は意味が異なる処理を示し、意味が同じブロックは垂直に配置されます。
ブロック グループは水平に配置され、仮の意味が与えられます。赤い枠線は、表示されない処理の区切り記号を示し、バーチャル オブジェクトと呼ばれるオブジェクトに対応します。注釈を使用して区切り記号にマークを付けると、分かりやすくなります。
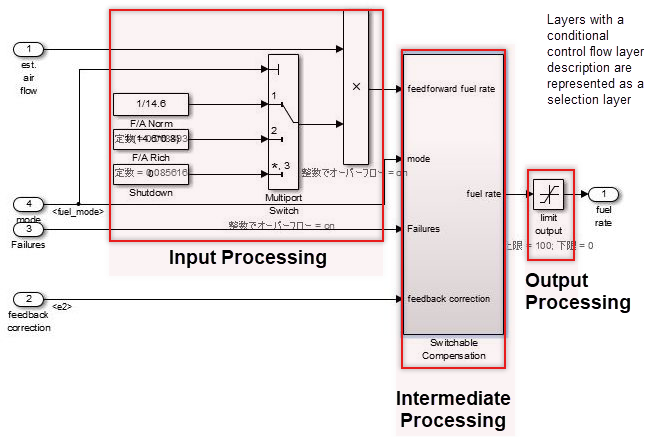
制御フロー レイヤーは、機能を含むブロックと共存できます。このレイヤーは、サブ機能レイヤーとデータ フロー レイヤーの間に配置されます。制御フロー レイヤーは、次の場合に使用されます。
ブロックの数が多すぎる
すべてがデータ フロー レイヤー内に記述されている
最小の部分的な意味を与えることができる単位がサブシステムになる
階層内の配置によって、内部レイヤーの構成を整理し、分かりやすくします。また、不要なレイヤーの作成を回避すると、保守性が向上します。
モデルがブロックのみで構成され、サブシステムと混在していない場合、水平レイアウトを入力処理、中間処理、出力処理に分割できる場合は、制御フロー レイヤーと見なされます。
選択レイヤー
モデリングの選択レイヤーでは、次のようになります。
選択レイヤーは縦または横並びに記述しなければなりません。並びの方向に意味はありません。
選択レイヤーは制御フロー レイヤーと混在します。
サブシステムに、赤い枠線内の条件付き制御フローに応じて 1 つのサブシステムしか動作できないスイッチ機能が含まれる場合、選択レイヤーと見なされます。また、入力処理、中間処理 (条件付き制御フロー)、出力処理で構成されるため、制御フロー レイヤーとしても記述されます。
制御フロー レイヤーでは、横方向は意味の異なる処理を示します。同じ意味の並列処理は、縦に配置されます。選択レイヤーでは、横方向または縦方向に意味はなく、1 つのサブシステムのみが動作できるレイヤーを示します。以下に例を示します。
時系列に変化する、上下に動作する連動機能の切り替え
1 回目 (リセットの直後) と 2 回目の後に計算タイプが切り替わる設定の切り替え
宛先 A と宛先 B 間の切り替え
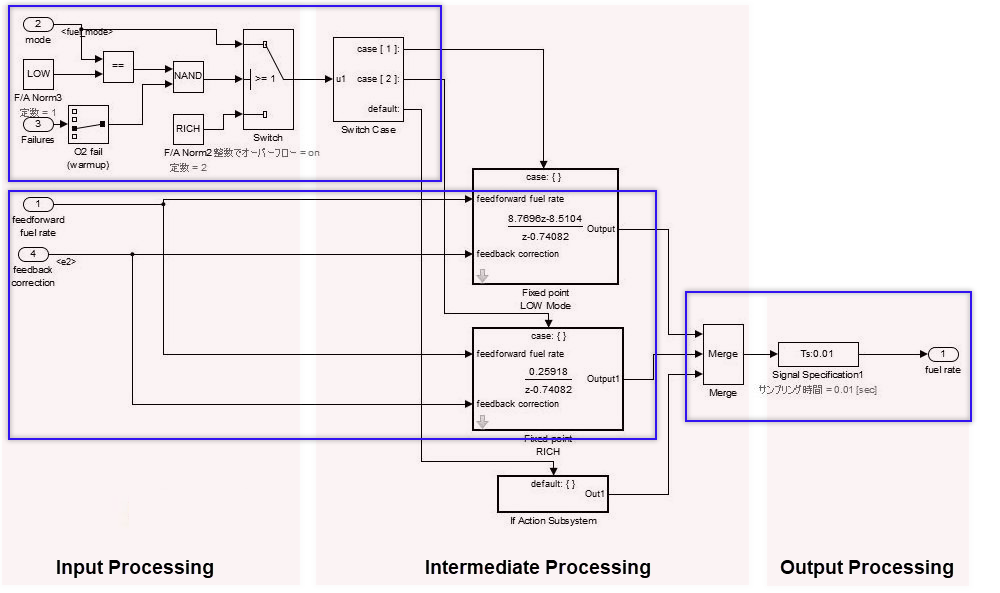
データ フロー レイヤー
データ フロー レイヤーは、制御フロー レイヤーと選択レイヤーの下位にあるレイヤーです。
データ フロー レイヤーは全体で 1 つの機能を表し、入力処理、中間処理、および出力処理は分割されません。たとえば、分割できない 1 つの連続する計算を実行するシステムです。
データ フロー レイヤーは、除外条件が適用されるサブシステム以外のサブシステムと共存できません。除外条件には、次が含まれます。
再利用可能な関数が設定されているサブシステム
Simulink® 標準ライブラリに登録されているマスク サブシステム
ユーザーによりライブラリに登録されるマスク サブシステム
単純なデータ フロー レイヤーの例
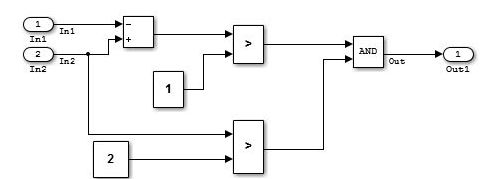
複雑なデータ フロー レイヤーの例
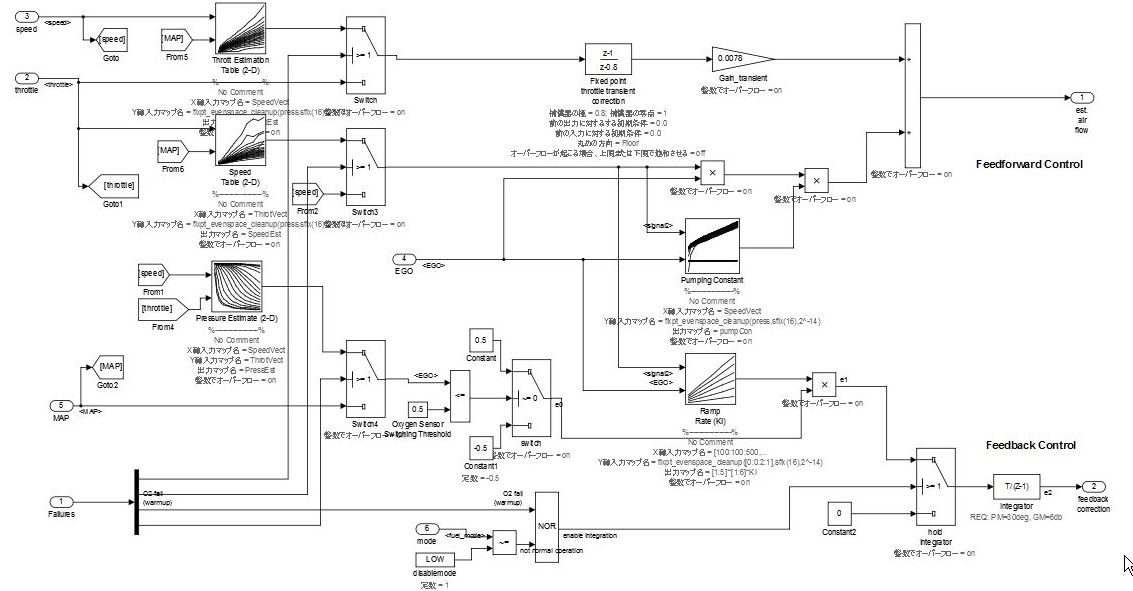
入力処理と中間処理が前述の説明のように明確に分割できない場合、これらの処理はデータ フロー レイヤーとして表されます。
同じ信号からのフィード フォワード応答とフィードバック応答の両方が同時に計算される場合、データ フロー レイヤーは複雑になります。このタイプのケースのブロック数が多い場合でも、機能を明確に分割できないときは、サブシステムの作成を設計に含めるべきではありません。分割によって意味を持たせる場合は、制御フロー レイヤーとして指定しなければなりません。
Simulink モデルと組み込み実装の関係
実際のマイクロ コントローラーを実行するには、Simulink モデルから生成されるコードをマイクロ コントローラーに組み込む必要があります。この要件は、Simulink モデルの構成に影響し、次に依存します。
Simulink モデルが機能をどの程度までモデル化するか
生成されるコードの組み込み方法
組み込まれるマイクロ コントローラーのスケジュール設定
組み込まれるマイクロ コントローラーのタスクが Simulink でモデル化されるタスクと異なる場合、構成に大きく影響します。
組み込みソフトウェアのスケジューラ設定
組み込みソフトウェアのスケジューラにはシングルタスク設定とマルチタスク設定があります。
シングルタスク スケジュール設定
シングルタスク スケジューラは、基本サンプリングを使用してすべての処理を実行します。したがって、より長いサンプリングの処理が必要な場合は、CPU 負荷ができる限り均等に分散されるように機能が分割されて、基本サンプリングを使用して処理されます。ただし、同じ設定が必ずしも可能でないため、機能はすべてのサイクルに割り当てることができない場合があります。
たとえば、基本サンプリングが 2 ミリ秒で、モデル内に 2 ミリ秒、8 ミリ秒、および 10 ミリ秒のサンプリング レートが存在するとします。8 ミリ秒の機能は、2 ミリ秒のサイクルで 4 サイクルごとに 1 回、10 ミリ秒の機能は 5 サイクルごとに 1 回実行されます。実行回数が 2 ミリ秒ごとにカウントされ、この頻度で指定されたサンプリングの機能が実行されます。2 ミリ秒、8 ミリ秒、および 10 ミリ秒のサイクルは、すべて同じ 2 ミリ秒で計算される点に注意する必要があります。すべての計算は 2 ミリ秒以内に完了する必要があるため、8 ミリ秒の機能と 10 ミリ秒の機能はいくつかに分割されて、すべての 2 ミリ秒の計算がほぼ均一のボリュームになるように調整されます。
以下の図は、4 つに分割された 8 ミリ秒の機能と、5 つに分割された 10 ミリ秒の機能を示しています。
| 機能 | 基本周波数 | オフセット |
| 8 ミリ秒 | 0 ミリ秒 | |
| 2-2 | 8 ミリ秒 | 2 ミリ秒 |
| 2-3 | 8 ミリ秒 | 4 ミリ秒 |
| 2-4 | 8 ミリ秒 | 6 ミリ秒 |
| 3-1 | 10 ミリ秒 | 0 ミリ秒 |
| 3-2 | 10 ミリ秒 | 2 ミリ秒 |
| 3-3 | 10 ミリ秒 | 4 ミリ秒 |
| 3-4 | 10 ミリ秒 | 6 ミリ秒 |
| 3-5 | 10 ミリ秒 | 8 ミリ秒 |
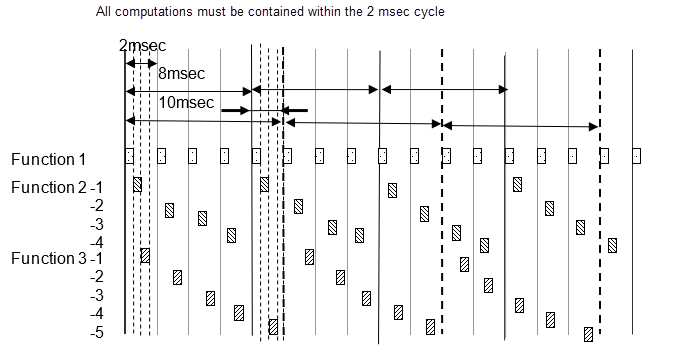
周波数分割タスクを設定するには、次のようにします。
コンフィギュレーション パラメーター各離散レートを個別のタスクとして扱うをクリアします。
Atomic Subsystem ブロック パラメーター [サンプル時間] に対して、サンプリング周期のオフセット値を入力します。サンプリング周期を指定できるサブシステムは、Atomic サブシステムと呼ばれます。

マルチタスク スケジューラ設定
マルチタスク サンプリングは、マルチタスク サンプリングをサポートするリアルタイム OS を使用して実行されます。シングル タスク サンプリングでは、CPU 負荷の均一化は自動的に実行されず、ユーザーが機能を分割して、それらを指定されたタスクに割り当てます。マルチタスク サンプリングでは、CPU は現在のステータスに合わせて計算を自動的に実行します。詳細な設定は必要ありません。構成が実行されて、結果は優先順位が最も高いタスクから始まる出力になりますが、タスクの優先度はユーザーが指定します。通常、最初のタスクに最も高い優先順位が割り当てられます。このタスクの実行順序は、ユーザーが指定します。

低速のタスクを含め、サイクル内に計算が完了することが重要です。優先度の高い計算の処理が完了し、CPU が使用可能である場合、次の優先順位ランクをもつシステムの計算が開始されます。優先度の高い計算プロセスは、優先度の低い計算を中断できます。これにより、優先度の低い計算は中止され、優先度の高い計算プロセスが最初に実行されます。
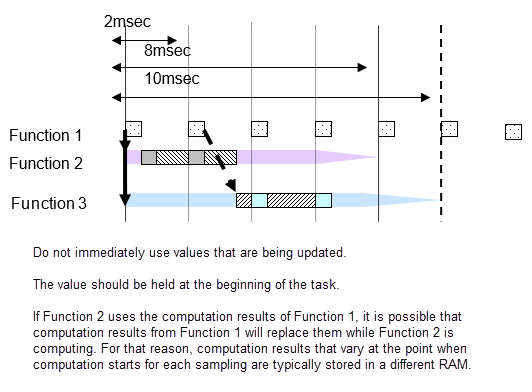
サンプリングが異なるサブシステムを接続する影響
サンプリング間隔が 20 ミリ秒のサブシステム B が、サンプリング間隔が 10 ミリ秒のサブシステム A の出力を使用している場合、サブシステム B の計算中にサブシステム A の出力結果が変更される可能性があります。値が途中で変更された場合、サブシステム B の計算結果が予想と異なる可能性があります。たとえば、システム B の最初の計算とサブシステム A の出力の比較が行われ、結果はこの出力に基づいて、条件判定で計算されます。この時点で、比較結果は true です。サブシステム B 側の端でもう一度比較されます。A からの出力が異なる場合は、比較の結果が false になる可能性があります。一般的に、このタイプの機能開発では、true、true で作成されるロジックが true、false になり、想定外の計算結果が生成される可能性があります。このような誤作動を回避するために、タスクに変化がある場合、サブシステム A からの出力結果は、サブシステム B で使用される直前に修正されます。これは、サブシステム A の出力信号で使用される RAM とは別の RAM で使用されるためです。つまり、サブシステム A の値がプロセス中に変化しても、サブシステム B が見ている値が別の RAM 内にあるため、影響は見られません。
モデルが Simulink で作成されて、サブシステムが Simulink で異なるサンプリング間隔を持つようにサブシステムが接続される場合、Simulink は必要な RAM を自動的に予約します。
ただし、ハンドコードされたコードとの統合により異なるサンプリング間隔の入力値を取得する場合、作業の組み込みを実行しているエンジニアはこれらの設定を設計しなければなりません。たとえば、AUTOSAR を使用する RTW の概念では、すべて受け取り側およびエクスポート側で異なる RAM が定義されます。
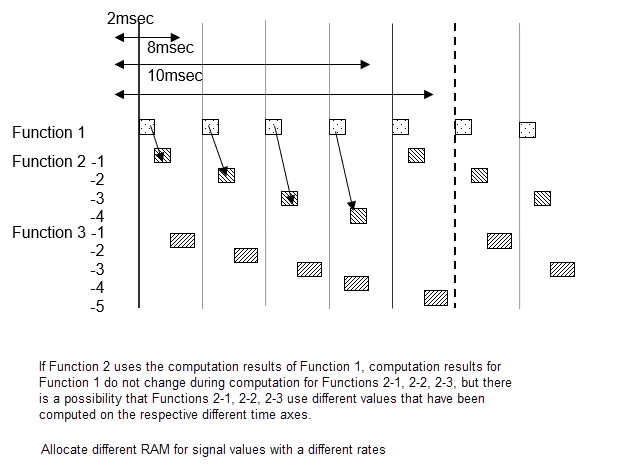
シングルタスクのスケジューラ設定
信号値は、2 ミリ秒サイクル内で同じですが、異なる 2 ミリ秒サイクルがある場合、計算値は前の値と異なります。機能 2-1 と 2-2 で機能 1 の信号 A を使用する場合は、2-1 および 2-2 は異なる時間の結果を使用します。
マルチタスク スケジューラ設定
マルチタスクの場合は、いつの時点の計算結果を使用しているか指定できません。マルチタスクでは、必ずタスクが異なる信号を常に新しい RAM に格納します。
タスク内で新しい計算を実行する前に、新しい値がコピーされます。