強化学習のワークフロー
強化学習を使用してエージェントに学習させる一般的なワークフローには、以下のステップが含まれます。
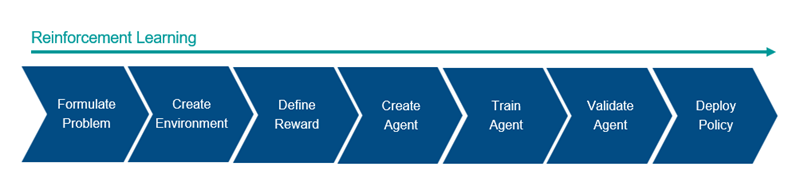
問題の定式化 — エージェントと環境のやり取りの方法やエージェントが達成しなければならない主な目標や 2 次的な目標など、エージェントに学習させるタスクを定義します。
環境の作成 — エージェントと環境の間のインターフェイスや環境の動的モデルなど、エージェントが動作する環境を定義します。詳細については、Reinforcement Learning Environmentsを参照してください。
報酬の定義 — タスク目標に対するパフォーマンスを測定するためにエージェントが使用する報酬信号と、環境からのこの信号を計算する方法を指定します。詳細については、Define Observation and Reward Signals in Custom Environmentsを参照してください。
エージェントの作成 — エージェントを作成します。既定の組み込みエージェントを作成することも、カスタムのアクター オブジェクトとクリティック オブジェクトを使用する組み込みエージェントを作成することもできます。詳細については、Create Actors, Critics, and Policy Objectsと強化学習エージェントを参照してください。
エージェントの学習 — 定義された環境、報酬、エージェント学習アルゴリズムを使用して、エージェント近似器に学習させます。詳細については、Train Reinforcement Learning Agentsを参照してください。
エージェントのシミュレーション — エージェントと環境を一緒にシミュレーションすることにより、学習済みエージェントのパフォーマンスを評価します。詳細については、Train Reinforcement Learning Agentsを参照してください。
方策の展開 — 生成された GPU コードなどを使用して、学習済みの方策近似器を展開します。詳細については、Generate Code from Trained Reinforcement Learning Policiesを参照してください。
強化学習を使用したエージェントの学習は、反復プロセスです。後段での判定や結果によっては、学習ワークフローの初期の段階に戻らなければならないことがあります。たとえば、学習プロセスが妥当な時間内に最適な方策に収束しない場合、エージェントに再学習させる前に以下のいくつかを更新する必要があるかもしれません。
学習の設定
学習アルゴリズムの構成
方策と価値関数 (アクターとクリティック) の近似器
報酬信号の定義
アクションと観測値の信号
環境ダイナミクス