制御システム用途での強化学習
強化学習方策の動作、つまり方策が環境を観測し、最適な方法でタスクを完了するためのアクションを生成する方法は、制御システムのコントローラーの動作に似ています。強化学習は、以下の対応付けによって、制御システム表現に変換することができます。
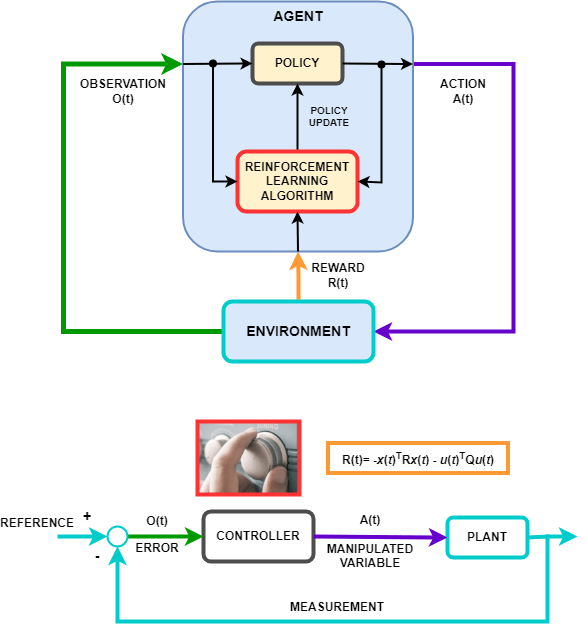
| 強化学習 | 制御システム |
|---|---|
| 方策 | コントローラー |
| 環境 | コントローラー以外のすべて — 上の図では、環境にプラント、基準信号、誤差の計算が含まれています。一般に、環境には次のような追加の要素も含めることができます。
|
| 観測値 | エージェントから可視の環境からの測定可能な任意の値 — 上の図では、コントローラーは環境からのエラー信号を確認できます。たとえば、基準信号、測定信号、および測定信号の変化率を観測するエージェントを作成することもできます。 |
| アクション | 操作変数または制御アクション |
| 報酬 | 測定値、誤差信号、またはその他のパフォーマンス メトリクスの関数 — たとえば、最小限の制御操作で定常状態誤差を最小限に抑える報酬関数を実装できます。コスト関数や制約関数などの制御仕様が利用可能な場合、generateRewardFunction 関数を使用して、MPC オブジェクトまたはモデル検証ブロックから報酬関数を生成できます。その後、たとえば重みやペナルティ関数を変更するなどして、生成された報酬関数を報酬設計の開始点として使用できます。 |
| 学習アルゴリズム | 適応型コントローラーの適応メカニズム |
ロボティクスや自動運転などの分野で遭遇する多くの制御問題には、複雑な非線形制御アーキテクチャが必要です。そのような問題には、ゲイン スケジューリング、ロバスト制御、非線形モデル予測制御 (MPC) などの技術を応用できますが、多くの場合、制御エンジニアの高度な専門知識を必要とします。たとえば、ゲインやパラメーターの調整は困難です。結果として得られるコントローラーは、非線形 MPC の計算量などの実装上の課題をもたらす可能性があります。
強化学習を使用して学習済みの深層ニューラル ネットワークを使用することで、そのような複雑なコントローラーを実装できます。このシステムでは、専門の制御エンジニアの介入なしで自己学習できます。また、システムに学習させた後は、計算効率の高い方法で強化学習方策を展開できます。
強化学習を使用して、イメージなどの生データから直接アクションを生成するエンドツーエンド コントローラーを作成することもできます。このアプローチは、イメージの特徴を手動で定義して選択する必要がないため、自動運転のようにビデオが多用される用途に適しています。
参考
トピック
- Compare DDPG Agent to LQR Controller
- 離散カートポールの平衡化のための既定の DQN エージェントの学習
- 離散振子の振り上げと平衡化のための既定の DQN エージェントの学習
- 強化学習を使用した複数の操作点における単一の PI コントローラー ゲインの調整
- Train Default TD3 Agent to Control Quanser QUBE Pendulum
- 強化学習とは
- 強化学習のワークフロー
- Reinforcement Learning Environments
- Create Custom Simulink Environments
- Define Observation and Reward Signals in Custom Environments
- 強化学習エージェント
- Train Reinforcement Learning Agents