compare
テスト データを類似性モデルの履歴データ アンサンブルと比較する
説明
compare(___, は、名前と値のペアの引数を 1 つ以上使用してプロット オプションを指定します。Name,Value)
例
学習データを読み込みます。
load('pairwiseTrainTables.mat')学習データは table の cell 配列です。各 table は、コンポーネントの劣化特徴プロファイルです。
ペアワイズ類似性モデルを作成し、学習させます。
mdl = pairwiseSimilarityModel; fit(mdl,pairwiseTrainTables,"Time","Condition")
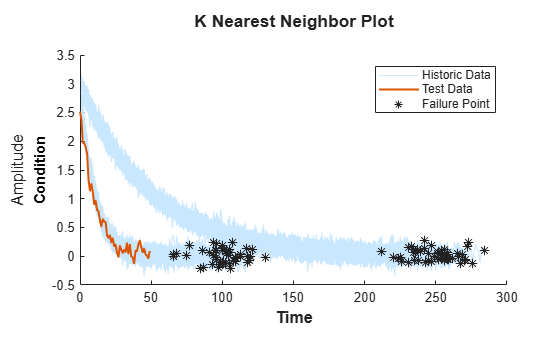
テスト データを読み込みます。
load('pairwiseTestData.mat')テスト データの劣化プロファイルを、履歴データ アンサンブルのプロファイルと比較します。
compare(mdl,pairwiseTestData)
学習データを読み込みます。
load('pairwiseTrainTables.mat')学習データは table の cell 配列です。各 table は、コンポーネントの劣化特徴プロファイルです。
ペアワイズ類似性モデルを作成し、学習させます。
mdl = pairwiseSimilarityModel; fit(mdl,pairwiseTrainTables,"Time","Condition")
テスト データを読み込みます。
load('pairwiseTestData.mat')テスト データの劣化プロファイルを、履歴データ アンサンブルの最も類似した 10 個のメンバーのプロファイルと比較します。
compare(mdl,pairwiseTestData,'NumNearestNeighbors',10)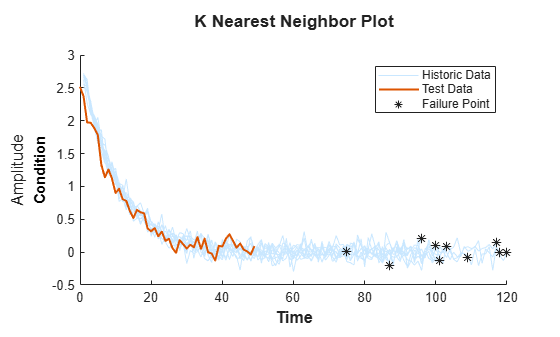
入力引数
名前と値の引数
バージョン履歴
R2018a で導入