histcounts2
二変量ヒストグラムのビンのカウント数
構文
説明
[ は、前述の任意の構文について名前と値の引数を 1 つ以上使用して、追加のパラメーターを指定します。たとえば、N,Xedges,Yedges] = histcounts2(___,Name,Value)BinWidth を 2 要素ベクトルとして指定して、各次元のビンの幅を調整します。
例
入力引数
名前と値の引数
出力引数
ビンのカウント数。配列として返されます。
ビン化スキームでは、各ビンの先頭の x 次元と y 次元のエッジに加え、x 次元と y 次元の最後のビンに対する後方のエッジが含められます。
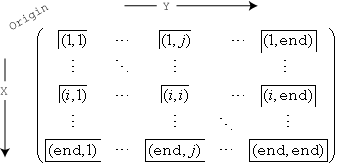
たとえば、(1,1) のビンは各次元の最初のエッジ上にある値を含み、右下の最後のビンはその任意のエッジ上にある値をすべて含みます。
x 次元のビンのエッジ。ベクトルとして返されます。最初の要素は、x 次元の最初のビンの先頭のエッジです。最後の要素は、x 次元の最後のビンの後方のエッジです。
y 次元のビンのエッジ。ベクトルとして返されます。最初の要素は、y 次元の最初のビンの先頭のエッジです。最後の要素は、y 次元の最後のビンの後方のエッジです。
x 次元のビン インデックス。X と同じサイズの配列として返されます。binX および binY の対応する要素は、X および Y の対応する値を含む番号付きビンを表します。binX または binY に値 0 が含まれる場合、これは要素がいずれのビンにも属さないことを示します (NaN 値など)。
たとえば、binX(1) および binY(1) は値 [X(1),Y(1)] のビンの位置を表します。
y 次元のビン インデックス。Y と同じサイズの配列として返されます。binX および binY の対応する要素は、X および Y の対応する値を含む番号付きビンを表します。binX または binY に値 0 が含まれる場合、これは要素がいずれのビンにも属さないことを示します (NaN 値など)。
たとえば、binX(1) および binY(1) は値 [X(1),Y(1)] のビンの位置を表します。
拡張機能
バージョン履歴
R2015b で導入参考
histogram | histcounts | discretize | histogram2 | morebins | fewerbins