1 つの予測子変数を含む線形回帰
単純な線形回帰は、単一の予測子変数と 1 つの応答変数間の関係を記述します。線形回帰モデルは、予測子の変化が応答にどのように影響するのかを理解するのに役立ちます。
この例では、polyfit 関数および polyval 関数を使用して、さまざまな次数の単純な線形回帰モデルの近似、可視化、および検証を行う方法を示します。代わりに基本的な近似ツールを使用してモデルを近似および可視化する方法の詳細については、対話的なデータの当てはめおよびモデルの可視化を参照してください。
次の場合には単純な線形回帰を使用します。
予測子変数が 1 つである。
予測子と応答の関係が係数において線形である。
予測子が応答に与える影響を定量化する。
データのプロット
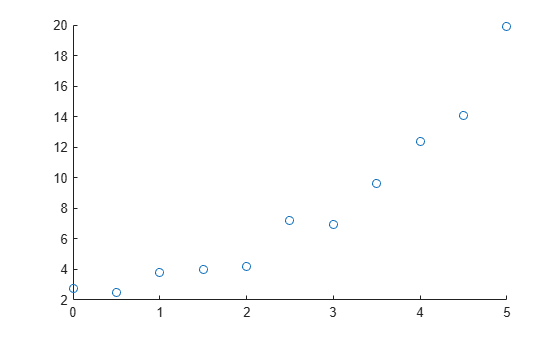
まず、データをプロットして、多項式近似の可能な次数を特定することからはじめます。
たとえば、サンプル予測子変数 x とサンプル応答変数 y を作成して可視化します。この可視化では、線形近似または 2 次近似によって予測子変数と応答変数の関係を記述できる可能性があることが示されています。
x = [0:0.5:5]'; y = [2.73 2.50 3.79 3.98 4.21 7.18 6.95 9.63 12.39 14.10 19.93]'; scatter(x,y)
1 次モデルの近似
polyfit 関数を使用して、1 次 (線形) モデルをデータに近似します。多項式係数と誤差推定構造体を返すために 2 つの出力引数を指定します。
[pLinear,SLinear] = polyfit(x,y,1)
pLinear = 1×2
3.1316 0.1155
SLinear = struct with fields:
R: [2×2 double]
df: 9
normr: 6.3071
rsquared: 0.8715
近似モデルを表示します。
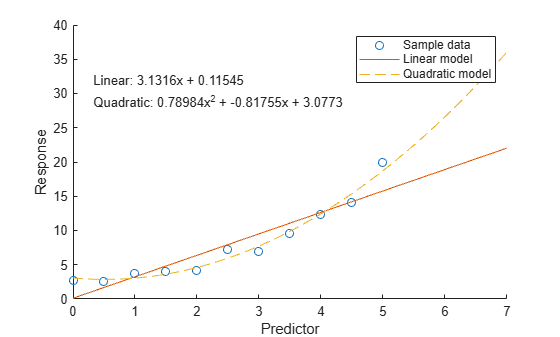
eqLinear = "Linear: " + pLinear(1) + "x + " + pLinear(2)
eqLinear = "Linear: 3.1316x + 0.11545"
高次モデルの近似
1 次モデルで予測子変数と応答変数の関係を適切に記述できない場合は、より高次のモデルを近似できます。たとえば、polyfit 関数を使用して、2 次モデルをデータに近似します。多項式係数と誤差推定構造体を返すために 2 つの出力引数を指定します。
[pQuad,SQuad] = polyfit(x,y,2)
pQuad = 1×3
0.7898 -0.8175 3.0773
SQuad = struct with fields:
R: [3×3 double]
df: 8
normr: 2.5152
rsquared: 0.9796
近似モデルを表示します。
eqQuad = "Quadratic: " + pQuad(1) + "x^2 + " + pQuad(2) + "x + " + pQuad(3)
eqQuad = "Quadratic: 0.78984x^2 + -0.81755x + 3.0773"
モデルの比較
プロットを使用してモデルを比較するには、まずクエリ点で各モデルを評価し、polyval 関数を使用して予測応答値を返します。次に、データおよび両方のモデルを可視化します。
たとえば、より細かい範囲の x 値における線形モデルおよび 2 次モデルの応答値を取得します。
xQuery = [0:0.05:7]'; yLinear = polyval(pLinear,xQuery); yQuad = polyval(pQuad,xQuery);
高次モデルで応答値が適切に予測されない場合は、過適合を示している可能性があります。モデルの検証と適切なモデルの複雑度の選択については、モデルの検証セクションを参照してください。
次に、サンプル データおよびモデル データをプロットします。
scatter(x,y) hold on plot(xQuery,yLinear,"-") plot(xQuery,yQuad,"--") hold off xlabel("Predictor") ylabel("Response") legend(["Sample data" "Linear model" "Quadratic model"]) text(0.3,30,[eqLinear eqQuad])
モデルの検証
モデルを検証するには、決定係数または自由度調整済み決定係数を計算します。値が 1 に近い場合は、近似度が高いことを示しています。
決定係数による線形モデルの検証
1 次モデルの場合、polyfit 関数によって返される誤差推定構造体を使用して決定係数の値にアクセスできます。たとえば、SLinear の rsquared フィールドをクエリします。
linearR2 = SLinear.rsquared
linearR2 = 0.8715
自由度調整済み決定係数による高次モデルの検証
より多くの項を持つ高次モデルの場合、通常、決定係数の値が大きくなり、観測データへの近似度が高いことが示されます。ただし、これらのモデルでは "過適合" のリスクが高くなります。
"過適合" は、モデルが元のデータ (ノイズを含む) をあまりにも綿密に記述し、新しいデータを適切に予測できない場合に発生します。
予測の品質とモデルの複雑度のバランスをとるために、予測子の数に対するペナルティを含む自由度調整済み決定係数の値を使用してモデルを検証することを検討します。次の式を使用して自由度調整済み決定係数の値を計算できます。ここで、 は誤差推定構造体の rsquared フィールドの値、 はデータ内の観測値の数、 はモデルの次数です。
たとえば、2 次モデルの自由度調整済み決定係数の値を計算します。
quadAdjRsq = 1 - (1 - SQuad.rsquared) * (numel(y) - 1) / (numel(y) - 2 - 1)
quadAdjRsq = 0.9744
各モデルの最大予測誤差の計算
モデルの予測とサンプル データ間の最大誤差を計算してモデルを検証することもできます。データ値に対する最大誤差が小さいということは、近似度が高いことを示します。
たとえば、線形モデルと 2 次モデルの両方の最大誤差を計算します。
Lia = ismember(xQuery,x); linearMaxError = max(abs(yLinear(Lia) - y))
linearMaxError = 4.1564
quadMaxError = max(abs(yQuad(Lia) - y))
quadMaxError = 1.2926
参考
関数
トピック
- 対話的なデータの当てはめおよびモデルの可視化
- Linear Regression with Nonpolynomial Terms
- Linear Regression with Multiple Predictor Variables
- 多項式の作成および評価
- 線形回帰ワークフロー (Statistics and Machine Learning Toolbox)
- 多項式モデルの当てはめ (Curve Fitting Toolbox)