対話的なデータの当てはめおよびモデルの可視化
基本的な近似ツールにより、スプライン内挿、形状維持内挿、または多項式 (最高 10 次) を使用して、2 次元プロットのデータを対話的にモデル化できます。このツールを使用すると、以下のことができます。
モデル係数を計算する。
元のデータを使用して 1 つ以上のモデルをプロットする。
モデルの残差をプロットする。
決定係数の値と残差のノルムを計算する。
モデルを使用してデータ範囲外での内挿または外挿を行う。
係数および計算された値を MATLAB ワークスペースに保存する。
データの読み込みとプロット
サンプル予測子変数 x とサンプル応答変数 y を作成します。散布図でデータを可視化します。
データ セットが大きく、値が昇順に並べ替えられていない場合、基本的な近似ツールで近似前のデータの前処理にかかる時間が長くなります。先にデータを並べ替えることで基本的な近似ツールを高速化できます。
x = [0:0.5:5]'; y = [2.73 2.50 3.79 3.98 4.21 7.18 6.95 9.63 12.39 14.10 19.93]'; scatter(x,y)
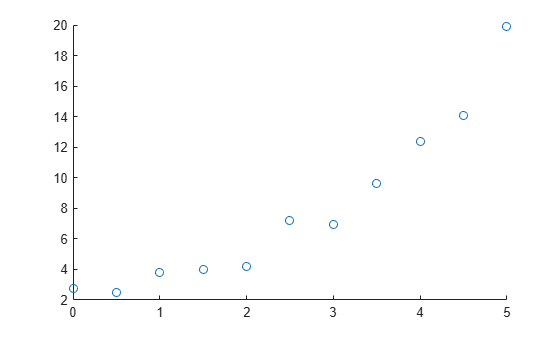
線形モデルおよび 2 次モデルによる近似
基本的な近似ツールを使用するには、Figure の [ツール] タブで、[基本的な近似] をクリックします。基本的な近似ツールを使用して、1 つ以上のモデルをデータに当てはめることができます。このツールを使用して、モデルおよび対応する方程式をプロット上に表示することもできます。
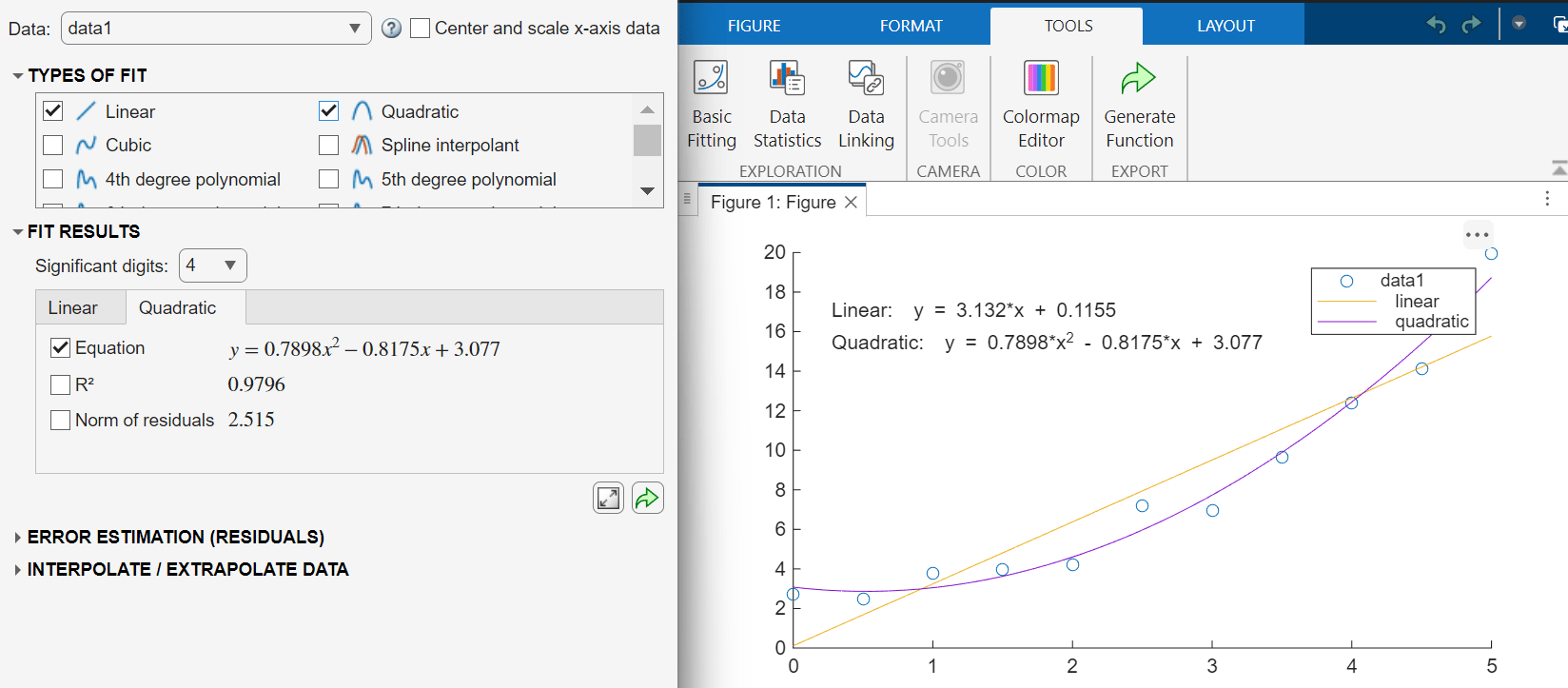
たとえば、線形モデルおよび 2 次モデルをサンプル データに当てはめます。[近似タイプ] セクションで [線形] モデルおよび [2 次] モデルを選択します。
モデルの検証
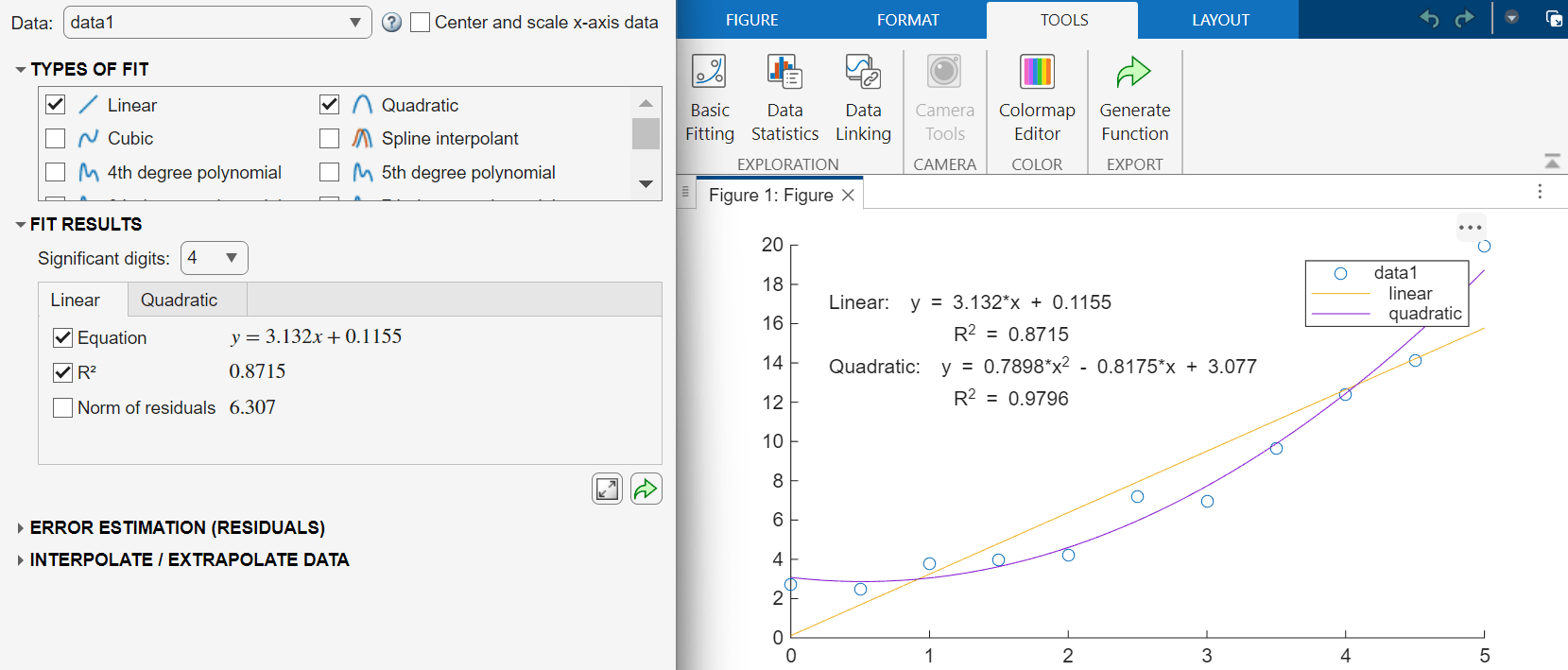
モデルを検証するには、決定係数を計算します。値が 1 に近い場合は、近似度が高いことを示しています。
プロット上にモデルの決定係数の値を表示するには、[近似の結果] セクションでモデルのタブを選択し、 を選択します。たとえば、線形モデルおよび 2 次モデルの決定係数の値を表示します。
高次モデルの場合、基本的な決定係数の値ではモデルの複雑度が十分に考慮されません。そうしたモデルを検証するためにより適した尺度は、自由度調整済み決定係数の値です。詳細については、1 つの予測子変数を含む線形回帰を参照してください。
ワークスペースへのモデル パラメーターの保存
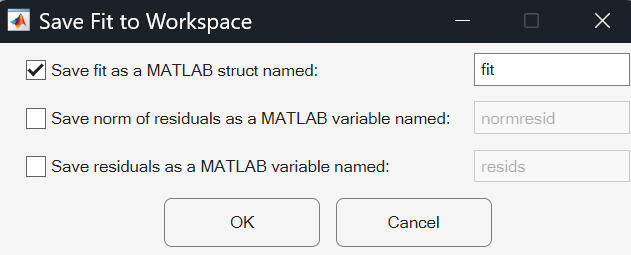
基本的な近似ツールの外部からモデルにアクセスするには、モデル データを MATLAB ワークスペースに保存します。[近似の結果] セクションの [結果をワークスペースにエクスポート] ボタンをクリックします。表示された [近似をワークスペースに保存] ダイアログ ボックスで、保存するパラメーターを選択し、[OK] をクリックします。
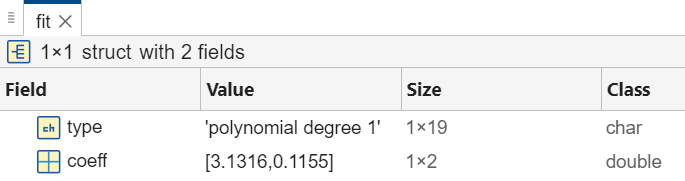
たとえば、線形モデルのモデル パラメーターをスカラー構造体 fit として保存します。
結果として得られる構造体には、2 つのフィールド type および coeff が含まれます。係数を使用してデータを内挿または外挿できます。たとえば、xSample のサンプル データ点について多項式を評価します。構造体の内容は変数エディターで表示できます。
polyval(fit.coeff,xSample)
openvar fit
ドット表記を使用して、構造体内のデータにアクセスできます。たとえば、係数のベクトルにアクセスします。
c = fit.coeff
データの内挿と外挿
モデルを使用してデータを内挿または外挿できます。基本的な近似ツールの [データの内挿/外挿] セクションで、クエリ点のベクトルを入力します。次に、[評価データのプロット] を選択して、プロット上にデータ点を表示できます。[評価をワークスペースにエクスポート] ボタンをクリックして、データ点を MATLAB ワークスペースにエクスポートすることもできます。
たとえば、クエリ点 [0.2 2.2 3.4] で 2 次モデルを評価します。[近似の結果] セクションの [2 次] タブを選択します。次に、[データの内挿/外挿] セクションで、[X] フィールドにクエリ点ベクトルを入力します。基本的な近似ツールに、内挿された y 値を含むテーブルが表示されます。[評価データのプロット] を選択して、内挿された値をプロットに追加します。
![The Basic Fitting tool appears to the left. In the Interpolate/Extrapolate Data section, the X field contains the vector [0.2 2.2 3.4] and the Plot evaluated data option is selected. At the right, a figure window displays a scatter plot as well as the fit, equation, and R-squared value for the linear and quadratic models. Three interpolated values are plotted on the linear (OR quadratic) model.](../../examples/matlab/win64/InteractivelyFitDataAndVisualizeModelExample_06.png)
生成されたコードを使用した新しいデータの近似
新しいデータで近似を再計算し、基本的な近似ツールを使用して作成したプロットを再現する MATLAB コードを生成できます。
Figure ウィンドウの [ツール] タブで [関数の生成] ![]() をクリックします。これにより、
をクリックします。これにより、createfigure という名前の関数が作成され、MATLAB エディターに表示されます。コードにより、基本的な近似ツールを使用して対話的に実行した操作がプログラムで再現されます。必要に応じて、関数の名前を変更し、コード ファイルを保存します。
次に、新しいデータでモデルを再計算してプロットを再現するために、関数を呼び出して、新しい "x" および "y" のデータを入力引数として指定します。
createfigure(xQuery,yQuery)