nfindr
N-FINDR を使用したエンドメンバー シグネチャの抽出
構文
説明
Add-On Required: この機能にはが必要です。
endmembers = nfindr(inputData,numEndmembers)inputData からエンドメンバー シグネチャを抽出します。numEndmembers は N-FINDR アルゴリズムを使用して抽出するエンドメンバー シグネチャの数です。N-FINDR 法の詳細については、アルゴリズムを参照してください。
endmembers = nfindr(inputData,numEndmembers,Name=Value)
メモ
Hyperspectral Imaging Library for Image Processing Toolbox™ は、MATLAB® Online™ および MATLAB Mobile™ によってサポートされないため、デスクトップの MATLAB が必要です。
例
ハイパースペクトル データをワークスペースに読み取ります。
hcube = imhypercube("paviaU.hdr");関数 countEndmembersHFC を使用して、ハイパースペクトル データ キューブ内に存在する、スペクトル的に異なるエンドメンバーの数を求めます。
numEndmembers = countEndmembersHFC(hcube,PFA=10^-7);
N-FINDR 法を使用してエンドメンバーを計算します。既定では、関数 nfindr は最大ノイズ フラクション (MNF) 変換を使用して前処理を行います。反復回数の既定値は、推定されたエンドメンバー数の 3 倍です。
datacube = gather(hcube); endmembers = nfindr(datacube,numEndmembers);
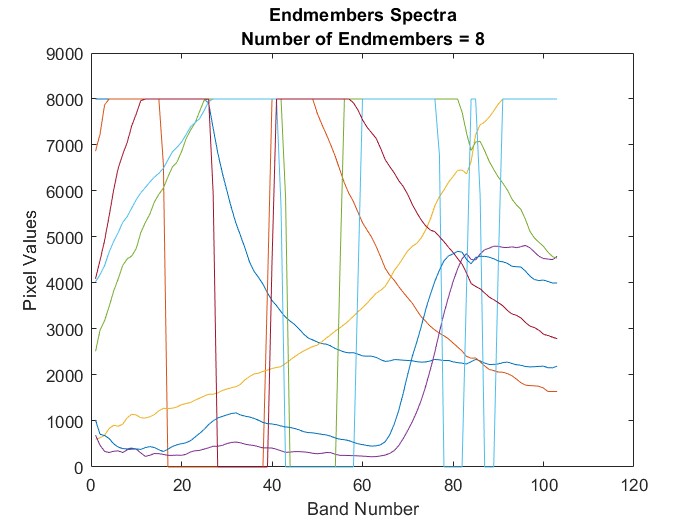
ハイパースペクトル データのエンドメンバーをプロットします。
figure plot(endmembers) xlabel("Band Number") ylabel("Pixel Values") ylim([0 9000]) title({"Endmembers Spectra","Number of Endmembers = "+num2str(numEndmembers)});
ハイパースペクトル データをワークスペースに読み取ります。
hcube = imhypercube("paviaU.hdr");関数 countEndmembersHFC を使用して、ハイパースペクトル データ キューブ内に存在する、スペクトル的に異なるエンドメンバーの数を求めます。
numEndmembers = countEndmembersHFC(hcube,PFA=10^-7);
N-FINDR 法を使用してエンドメンバーを計算します。反復回数の値を 1000 に指定します。次元削減方法として主成分分析 (PCA) を選択して前処理を行います。
datacube = gather(hcube);
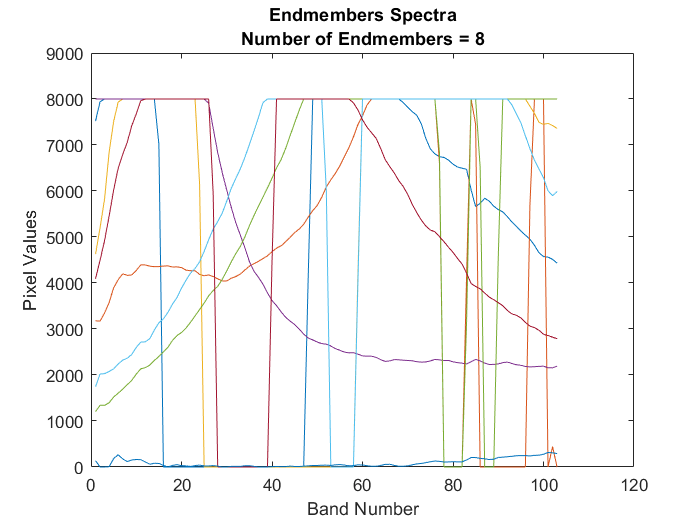
endmembers = nfindr(datacube,numEndmembers,NumIterations=1000,ReductionMethod="PCA");ハイパースペクトル データのエンドメンバーをプロットします。
figure plot(endmembers) xlabel("Band Number") ylabel("Pixel Values") ylim([0 9000]) title({"Endmembers Spectra","Number of Endmembers = "+num2str(numEndmembers)});
入力引数
名前と値の引数
出力引数
アルゴリズム
N-FINDR はハイパースペクトル データのエンドメンバーを求めるための反復手法です。この方法は、エンドメンバー (最もピュアなピクセル) により構成されるシンプレックスのボリュームが、他のピクセルの組み合わせで定義される他のどのボリュームよりも大きいことを前提とします [1]。含まれる手順をまとめると以下のとおりです。
主成分バンドを計算し、MNF または PCA を使用して入力データのスペクトル次元を削減します。抽出する主成分バンドの数は、抽出するエンドメンバーの数と等しく設定されます。エンドメンバーは主成分バンドから抽出されます。
削減されたデータから、エンドメンバーの初期セットとして n 個のピクセル スペクトルをランダムに選択します。
反復 1 では、エンドメンバーの初期セットを と記述します。
エンドメンバーをシンプレックスの頂点と考え、次を使用してボリュームを計算します。
ここで、 です。
反復 2 では、新しいピクセル スペクトル r を選択します。ただし、 です。
セット内の各エンドメンバーを r で置き換え、シンプレックスのボリューム V(E(2)) を計算します。
計算されたボリューム V(E(2)) が V(E(1)) より大きい場合は、セット内の ith 番目のエンドメンバーを r で置き換えます。これにより、エンドメンバーのセットが更新されます。たとえば、i = 2 の場合、2 回目の反復の最後に導出された新しいエンドメンバーのセットは です。
各反復で、新しいピクセル スペクトル r を選択し、手順 5 と 6 を繰り返します。反復するごとにエンドメンバーのセットが更新されます。総反復回数が、指定された値
NumIterationsに達すると反復が終了します。
参照
[1] Winter, Michael E. “N-FINDR: An Algorithm for Fast Autonomous Spectral End-Member Determination in Hyperspectral Data.” Proc. SPIE Imaging Spectrometry V 3753, (October 1999): 266–75. https://doi.org/10.1117/12.366289.
バージョン履歴
R2020a で導入
参考
hypercube | ppi | countEndmembersHFC | fippi