乗算器のリソース共有による面積の削減
この例では、HDL Coder™ でリソース共有最適化を使用する方法を示します。この最適化では、MATLAB® コードに含まれる機能的に等価な乗算器の演算を特定し、設計面積を最適化するためにそれらを共有します。設計で共有する乗算器の数を制御できます。
はじめに
リソース共有は、面積効率の高いハードウェアを実装するために HDL Coder™ でサポートされている設計全体の最適化です。
この最適化を使用すると、ユーザーは N 個の機能的に等価な MATLAB 演算子 (この例では乗算器) を単一の演算子にマッピングしてハードウェア リソースを共有できます。
ユーザーは最適化パネルで Resource Sharing Factor オプションを使用して N を指定します。
次の対称 FIR フィルターのモデル例について考えます。機能的に等価な 4 つの Product ブロックがあり、ハードウェアの 4 つの乗算器にマッピングされています。リソース利用レポートに、設計から推定される乗算器の数が表示されます。
この例では、MATLAB 設計 mlhdlc_sharing で固定小数点変換を実行してから HDL Coder に進みます。この前提条件の手順により、固定小数点コードで使用されているすべての乗算器が正規化されます。この固定小数点変換のフェーズでは、推奨された型の設定を入力します。
MATLAB 設計
この例で使用する MATLAB コードは MATLAB で記述されたシンプルな対称 FIR フィルターであり、このフィルターを使用するテストベンチも含まれています。
design_name = 'mlhdlc_sharing'; testbench_name = 'mlhdlc_sharing_tb';
MATLAB 設計を確認します。
type(design_name);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% MATLAB design: Symmetric FIR Filter
%
% Key Design pattern covered in this example:
% (1) Filter states represented using the persistent variables
% (2) Filter coefficients passed in as parameters
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Copyright 2011-2015 The MathWorks, Inc.
%#codegen
function [y_out, x_out] = mlhdlc_sharing(x_in, h)
% Symmetric FIR Filter
persistent ud1 ud2 ud3 ud4 ud5 ud6 ud7 ud8;
if isempty(ud1)
ud1 = 0; ud2 = 0; ud3 = 0; ud4 = 0; ud5 = 0; ud6 = 0; ud7 = 0; ud8 = 0;
end
x_out = ud8;
a1 = ud1 + ud8;
a2 = ud2 + ud7;
a3 = ud3 + ud6;
a4 = ud4 + ud5;
% filtered output
y_out = (h(1) * a1 + h(2) * a2) + (h(3) * a3 + h(4) * a4);
% update the delay line
ud8 = ud7;
ud7 = ud6;
ud6 = ud5;
ud5 = ud4;
ud4 = ud3;
ud3 = ud2;
ud2 = ud1;
ud1 = x_in;
end
type(testbench_name);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% MATLAB test bench for the FIR filter
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Copyright 2011-2015 The MathWorks, Inc.
clear mlhdlc_sharing;
% input signal with noise
x_in = cos(3.*pi.*(0:0.001:2).*(1+(0:0.001:2).*75)).';
len = length(x_in);
y_out = zeros(1,len);
x_out = zeros(1,len);
% Define a regular MATLAB constant array:
%
% filter coefficients
h = [-0.1339 -0.0838 0.2026 0.4064];
for ii=1:len
data = x_in(ii);
% call to the design 'mlhdlc_sfir' that is targeted for hardware
[y_out(ii), x_out(ii)] = mlhdlc_sharing(data, h);
end
figure('Name', [mfilename, '_plot']);
plot(1:len,y_out);
HDL Coder プロジェクトの新規作成
次のコマンドを実行して新しいプロジェクトを作成します。
coder -hdlcoder -new mlhdlc_sfir_sharing
次に、mlhdlc_sharing.m ファイルを MATLAB 関数としてプロジェクトに追加し、mlhdlc_sharing_tb.m を MATLAB テスト ベンチとして追加します。
MATLAB HDL Coder プロジェクトの作成と入力に関する詳細なチュートリアルについては、MATLAB から HDL へのワークフロー入門を参照してください。
リソース共有を最適化するためのデータ型の設定
リソース共有を最適化するには、変数の numerictype データ型を必ず同じにします。
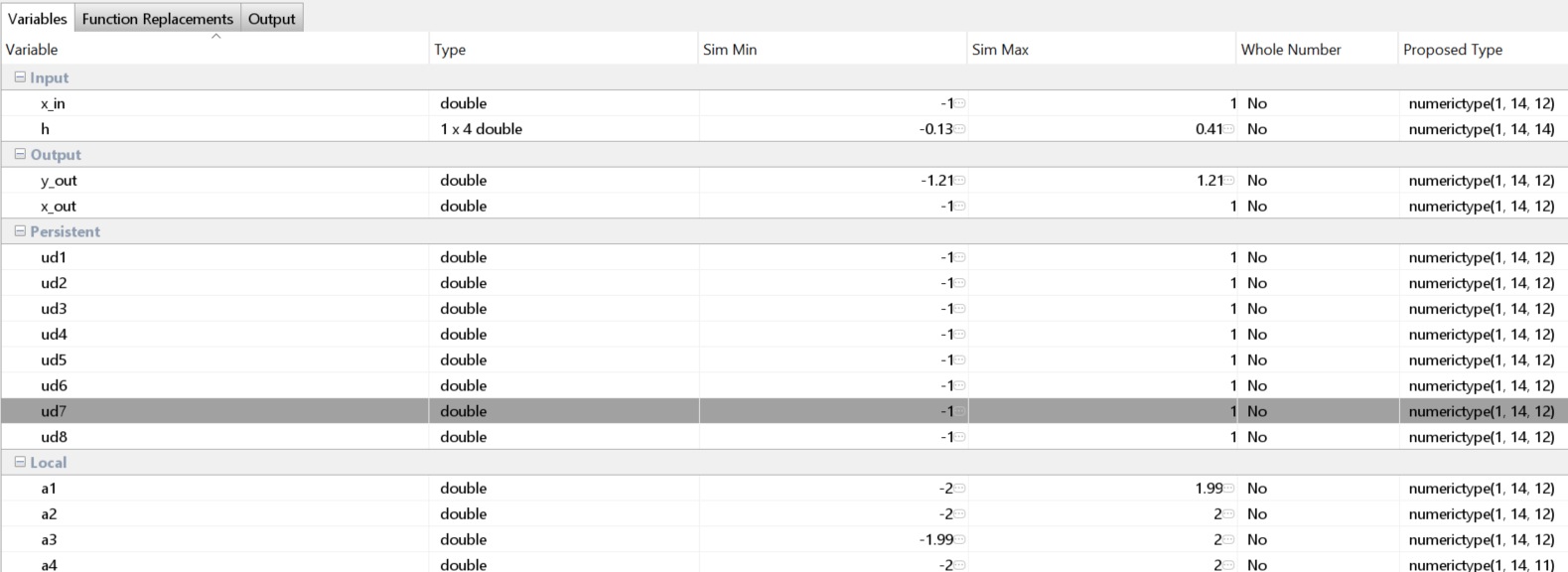
乗算器の N 対 1 のマッピングの実現
[リソース共有係数] を正の整数値に設定してリソース共有最適化をオンにします。
このパラメーターは、N 対 1 のハードウェア マッピングにおける N を指定します。N > 1 の値を選択します。
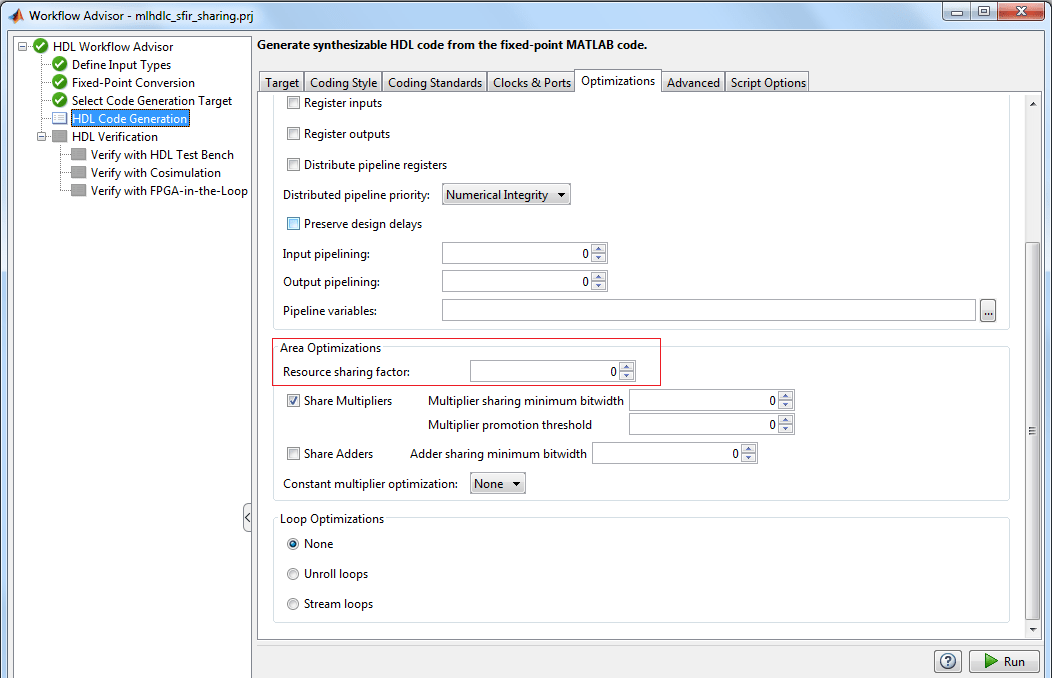
リソース レポートの確認
この例の設計には乗算演算子が 4 つあります。SharingFactor を 4 にして HDL を生成すると、生成されたコードでは乗算器が 1 つだけになります。

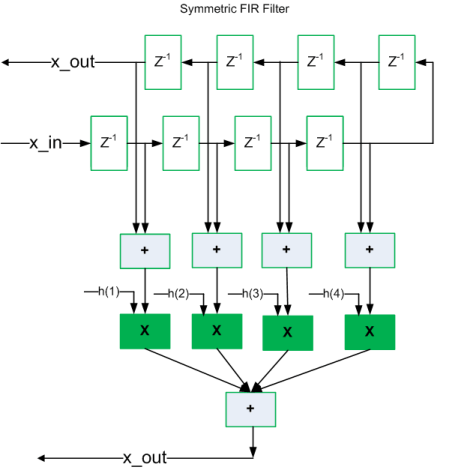
共有アーキテクチャ
次の図は、生成されたコードを共有最適化をオンにせずに合成した場合のハードウェアへのアルゴリズムの実装を示しています。
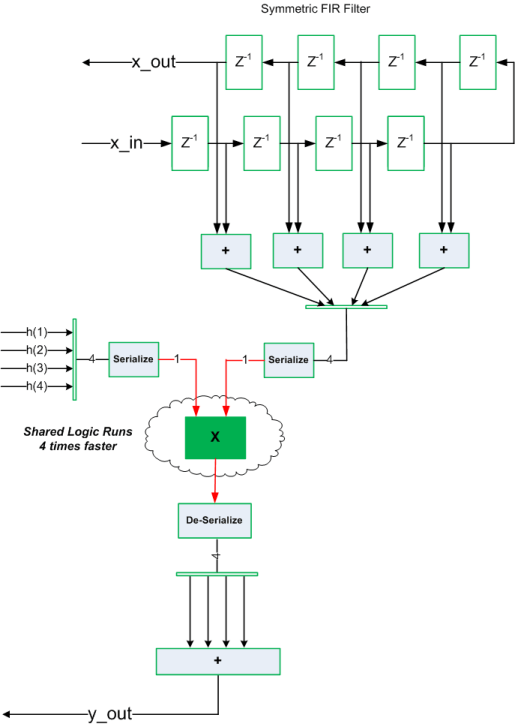
次の図は、共有最適化オプションをオンにした場合に HDL Coder で自動的に実装される共有アーキテクチャを示しています。
共有乗算器への入力が速いレートで時間多重化されます (この例では 4 倍の速さであり、赤で示してあります)。その後、出力がそれぞれのコンシューマーに遅いレートで送られます (緑の部分)。
固定小数点変換と HDL コード生成の実行
ワークフロー アドバイザーを起動して [コード生成] の手順を右クリックします。[選択したタスクまで実行] オプションを選択して、最初から HDL コード生成までのすべての手順を実行します。
詳細な例については、Fixed-Point Type Conversion and Derived Rangesを参照してください。固定小数点変換で型の推奨に関する設定を更新するチュートリアルを提供しています。
語長の異なる乗算器を共有する場合は、HDL コンフィギュレーション パラメーターの [最適化]、[リソース共有] タブで [乗算器拡張のしきい値] を指定することに注意してください。
合成の実行と合成結果の確認
この最適化をオフにした設計とオンにした設計から生成されたコードをそれぞれ合成し、リソース レポートで面積の数値を調べます。