このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
AXI-Stream インターフェイスを使用した IP コアの生成
この例では、Zynq® ハードウェアのプロセッサと FPGA の間の高速データ転送を可能にする AXI4-Stream インターフェイスの使用方法を説明します。
はじめる前に
この例を実行するには、次のソフトウェアとハードウェアをインストールして設定していなければなりません。
HDL の言語サポートおよびサポートされるサードパーティ製ツールとハードウェアにリストされている、サポートされているバージョンの Xilinx Vivado® Design Suite
ZedBoard (ZedBoard を設定するには、Simulink モデルからの IP コアの生成入門の例の「Zynq ハードウェアとツールの設定」セクションを参照)
はじめに
以下の例では、次のような操作方法を説明します。
簡易ストリーミング プロトコルを使用したストリーミング アルゴリズムのモデル化。
AXI4-Stream インターフェイスを使用した HDL IP コアの生成。
DMA コントローラーを使用した Zedboard リファレンス設計への生成された IP コアの統合。
AXI4-Stream ドライバー ブロックを使用した ARM プロセッサで実行する C コードの生成。
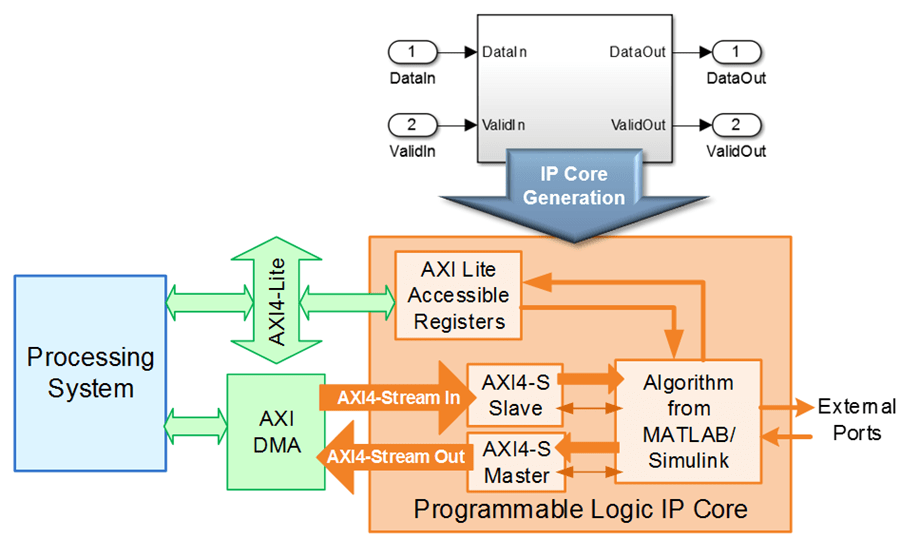
上記の図は、Zynq プラットフォームでのプロセッサと FPGA ファブリックの間のストリーミング データ転送を示すアーキテクチャの概要図です。通常、AXI4-Stream インターフェイスは、プロセッサから FPGA に大規模なデータのチャンクを転送するために、直接メモリ アクセス (DMA) コントローラーと共に使用されます。データは通常、ソフトウェアでベクトル データとして表されます。DMA コントローラーは、メモリからベクトル データを読み取り、それを AXI4-Stream インターフェイスを介して FPGA IP にストリーミングします。ストリーミング プロセスは、サンプルあたり 1 つのデータ要素を送信します。これは、FPGA IP のストリーミング アルゴリズムのデータ パスがスカラー データ型を使用していることを意味します。
FPGA IP には、制御信号またはパラメーター調整のために AXI4-Lite インターフェイスを含めることもできます。AXI4-Lite インターフェイスと比べて、AXI4-Stream インターフェイスは、データをより高速に転送するため、アルゴリズムのデータ パスにより適しています。
プロセッサへの接続以外に、AXI4-Stream インターフェイスをもつ FPGA IP を AXI4-Stream インターフェイスをもつその他の IP にも接続して、FPGA 内部のデータを転送することができます。
簡易ストリーミング プロトコルを使用するストリーミング アルゴリズムのモデル化
Zynq ハードウェアで単純な対称 FIR フィルターを展開するには、そのフィルターを FPGA に実装します。ARM プロセッサはソース データを生成し、AXI4-Stream インターフェイスを介してそれを FPGA にストリーミングします。
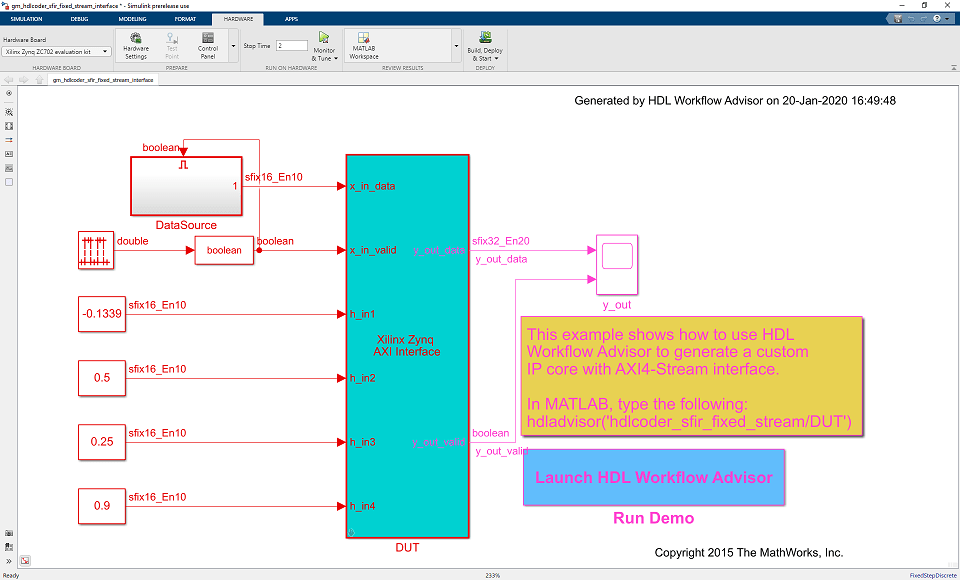
sfir_fixed モデルを考えます。
open_system('sfir_fixed') set_param('sfir_fixed', 'SimulationCommand', 'Update')

このモデルのデータ パス (x_in から y_out まで) は、スカラーの入力データを処理していることに注意してください。これは、ストリーミング インターフェイスに適しています。
ソフトウェアからフィルター アルゴリズムへのデータ転送を有効にするために、データ パス端子を AXI4-Stream インターフェイスにマッピングする必要があります。AXI4-Stream インターフェイスにはデータ (Data) に加え、データ有効 (Valid)、バック プレッシャー (Ready)、データの境界 (TLAST) などの制御信号が含まれます。
AXI4-Stream IP コア生成機能では、少なくとも Data 信号と Valid 信号を DUT でモデル化する必要があります。Data 信号は、インターフェイスを超えて送信するプライマリ ペイロードです。Valid 信号は、Data 信号が有効であることを示します。その他の制御信号はオプションです。
メモ: IP コアを生成するには、"Data" と "Valid" は簡易ストリーミング プロトコルに従います。完全な AXI4-Stream プロトコルをモデル化する必要はありません。HDL Coder は、簡易ストリーミング プロトコルを完全な AXI4-Stream プロトコルに変換するために、HDL IP コアのストリーミング インターフェイス モジュールを自動的に生成します。以下の図に示すように、プロトコルでは、"Data" 信号が有効なときには常に、"Valid" 信号もアサートされなければなりません。

sfir_fixed アルゴリズムを簡易ストリーミング プロトコルにマッピングするために、"Valid" 信号を追加する必要があります。"Valid" 信号をモデルに追加するには、次のモデリング パターンを使用します。
アルゴリズム サブシステムを Enabled Subsystem に変換します。
入力制御端子
Valid_Inと出力制御端子Valid_Outを追加します。Valid_Inを使用して、アルゴリズム サブシステムのイネーブル端子とValid_Outを駆動します。

このパターンでは、入力ストリーミング チャネルと出力ストリーミング チャネルの両方が、簡易ストリーミング プロトコルに従います。
モデル例を開きます。
open_system('hdlcoder_sfir_fixed_stream');
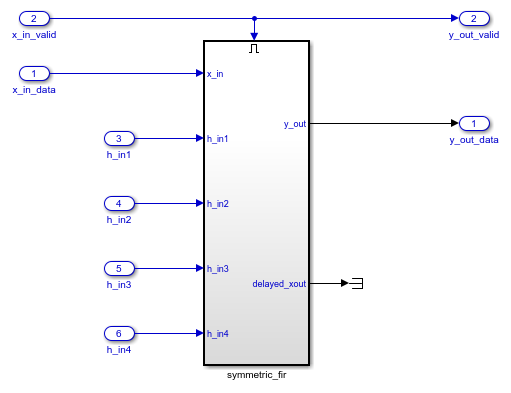
サブシステム DUT は、FPGA ファブリックをターゲットにするハードウェア サブシステムです。このサブシステム内で、symmetric_fir サブシステムはフィルター アルゴリズムを表します。入力端子 x_in_data と x_in_valid および出力端子 y_out_data と y_out_valid は、フィルターのデータ パス端子です。h_in1 などのその他の入力端子は、フィルター パラメーターを調整する制御端子です。
モデルは、簡易ストリーミング プロトコルのモデリング パターンに従います。symmetric_fir サブシステムは、Enabled Subsystem です。入力制御信号 x_in_valid は symmetric_fir サブシステムのイネーブル端子を制御し、出力制御信号 y_out_valid の駆動も行います。
AXI4-Stream IP コアの生成を使用すると、他のストリーミング制御信号をオプションでモデル化できます。たとえば、バック プレッシャー信号 Ready をモデル化できます。AXI4-Stream インターフェイスはマスター/スレーブ モードで通信します。このモードでは、マスター デバイスがデータをスレーブ デバイスに送信します。Ready 信号は、スレーブ デバイスからマスター デバイスへの、スレーブ デバイスが新しいデータを受け入れるかどうかを示すバック プレッシャー信号です。次の図に示すように、スレーブ デバイスが新しいデータを受け入れることができるときに "Ready" 信号がアサートされます。スレーブ デバイスが新しいデータを受け入れられなくなったときに、Ready 信号をデアサートする必要があります。マスター デバイスが Ready 信号のデアサートを認識した時点から最大 1 サンプル後にデータ転送が停止されます。この 1 サンプルの許容は、プロトコルに組み込まれます。
メモ: 次の図は、簡易ストリーミング プロトコルに従った "Data" 信号、"Valid" 信号、"Ready" 信号の間の関係を示しています。IP Core Generation ワークフローを実行すると、コード ジェネレーターによってストリーミング インターフェイス モジュールが HDL IP コアで追加され、それにより簡易プロトコルが完全なストリーミング プロトコルに変換されます。
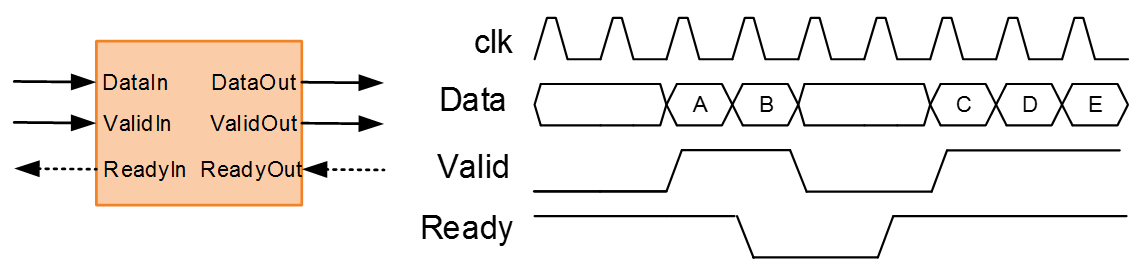
FIFO ブロックを使用して着信ストリーミング データのフレームを収集するときに、"Ready" 信号を使用できます。このデータは次にアルゴリズムで処理されます。データ処理中は、Ready 信号をデアサートしてデータがさらに着信しないようにします。
AXI4-Stream インターフェイスを使用した HDL IP コアの生成
次に、HDL ワークフロー アドバイザーを起動し、Zynq ハードウェア ソフトウェア協調設計ワークフローを使用して、この設計を Zynq ハードウェアに展開します。詳しい手順については、Simulink モデルからの IP コアの生成入門の例を参照してください。
1. hdlsetuptoolpathコマンドを使用して Xilinx Vivado 合成ツール パスを設定します。コマンドを実行するときに独自の Vivado インストール パスを使用します。
hdlsetuptoolpath('ToolName', 'Xilinx Vivado', 'ToolPath', vivadopath)2. DUT サブシステム hdlcoder_sfir_fixed_stream/DUT から HDL ワークフロー アドバイザーを起動します。このモデル例では、ターゲット インターフェイスの設定は既に保存されているため、タスク 1.1 と 1.2 の設定は自動的に読み込まれます。モデルのターゲット インターフェイス設定の保存の詳細については、Save IP Core Generation and Target Hardware Settings in Modelの例を参照してください。
タスク 1.1 では、[ターゲット ワークフロー] については [IP Core Generation] が選択され、[ターゲット プラットフォーム] については [Zedboard] が選択されます。タスク 1.2 では、[リファレンス設計] については [Default system with AXI4-Stream interface] が選択され、次の図に示すように [ターゲット プラットフォーム インターフェイス テーブル] が読み込まれます。データ パス端子 x_in_data、x_in_valid、y_out_data、および y_out_valid は AXI4-Stream インターフェイスにマッピングされ、h_in1 などの制御パラメーター端子は AXI4-Lite インターフェイスにマッピングされます。

AXI4-Stream インターフェイスはマスター/スレーブ モードで通信します。このモードでは、マスター デバイスがデータをスレーブ デバイスに送信します。したがって、データ端子が入力端子である場合、これを AXI4-Stream スレーブ インターフェイスに割り当て、データ端子が出力端子である場合、これを AXI4-Stream マスター インターフェイスに割り当てます。
3. タスク 3.2 [RTL コードと IP コアの生成] を右クリックして、[選択したタスクまで実行] を選択し、IP コアを生成します。生成された IP コア レポート内の IP コアについては、レジスタ アドレス マッピングおよびその他のドキュメントを参照してください。
AXI4-Stream 互換のリファレンス設計への IP の統合
次に、HDL ワークフロー アドバイザーで、[組み込みシステムの統合] タスクを実行して、生成された HDL IP コアを Zynq ハードウェアに展開します。
1. タスク 4.1 [プロジェクトを作成] を実行します。このタスクでは、生成された IP コアが [Default system with AXI4-Stream interface] リファレンス設計に挿入されます。このリファレンス設計には、FPGA ファブリック データ ストリーミングへのプロセッサを処理するための Xilinx AXI DMA IP が含まれます。最初の図に示すように、または IP コア レポートでは、データは ARM プロセッシング システムから、DMA コントローラーと AXI4-Stream インターフェイスを介して、生成された HDL FIR フィルター IP コアに送信されます。次に、フィルター IP コアの出力はプロセッシング システムに送り返されます。
2. 必要に応じて、[結果] ペインのリンクをクリックして、生成された Vivado プロジェクトを開きます。Vivado ツールで、[Open Block Design] をクリックして Zynq 設計図を表示します。これには、生成された HDL IP コア、AXI DMA コントローラーおよびプロセッサが含まれます。
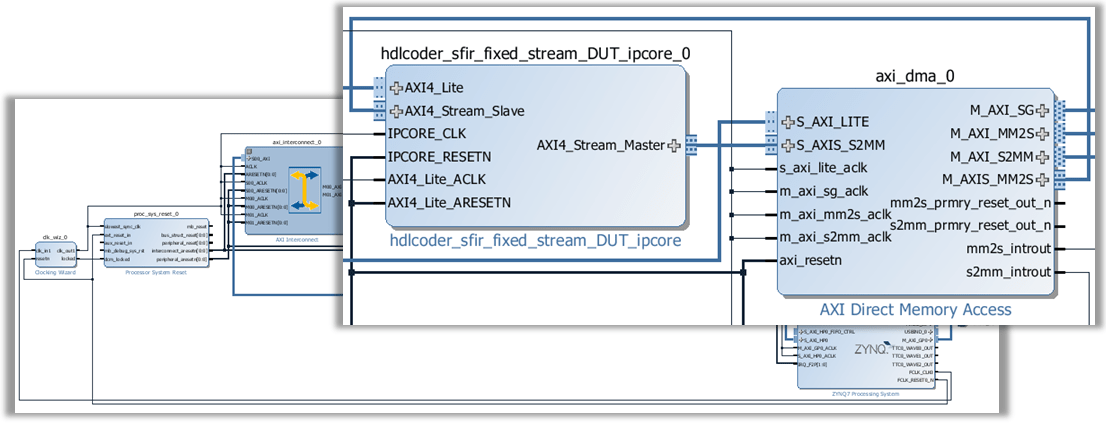
3. HDL ワークフロー アドバイザーで、残りのタスクを実行してソフトウェア インターフェイス モデルを生成し、FPGA ビットストリームを作成およびダウンロードします。
AXI4-Stream ドライバー ブロックを使用した ARM 実行可能ファイルの生成
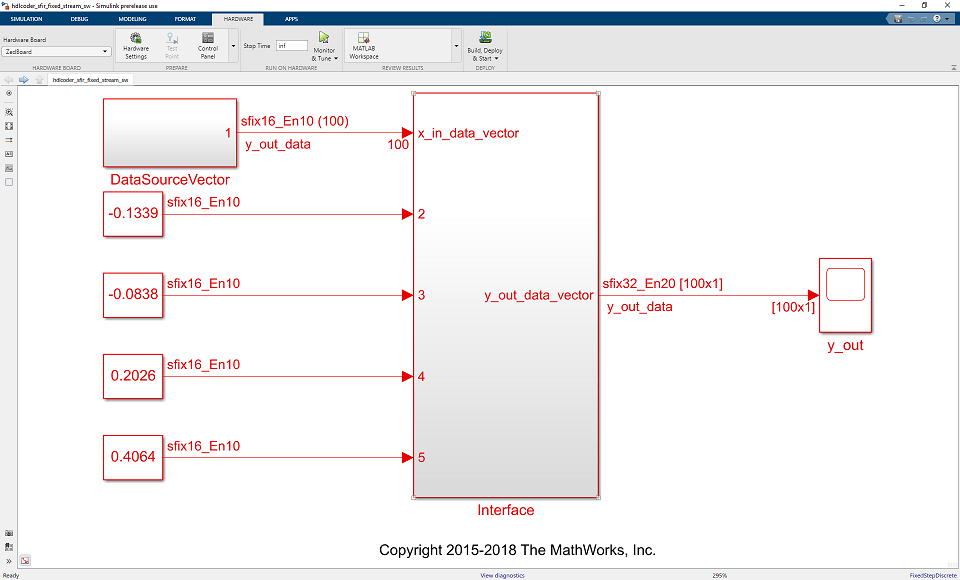
次の図に示すように、ソフトウェア インターフェイス モデルはタスク 4.2 [ソフトウェア インターフェイス モデルを生成] で生成されます。
ソフトウェア インターフェイス モデルで AXI4-Lite ドライバーは自動的に生成されますが、AXI4-Stream ドライバー ブロックは自動的に生成できません。その理由は、AXI4-Stream ドライバー ブロックは、ソフトウェア側ではベクトル端子に接続されると想定されますが、x_in_data DUT 端子はスカラー端子であるためです。
1. ソフトウェア インターフェイス モデルからコードを生成する前に、次を実行します。
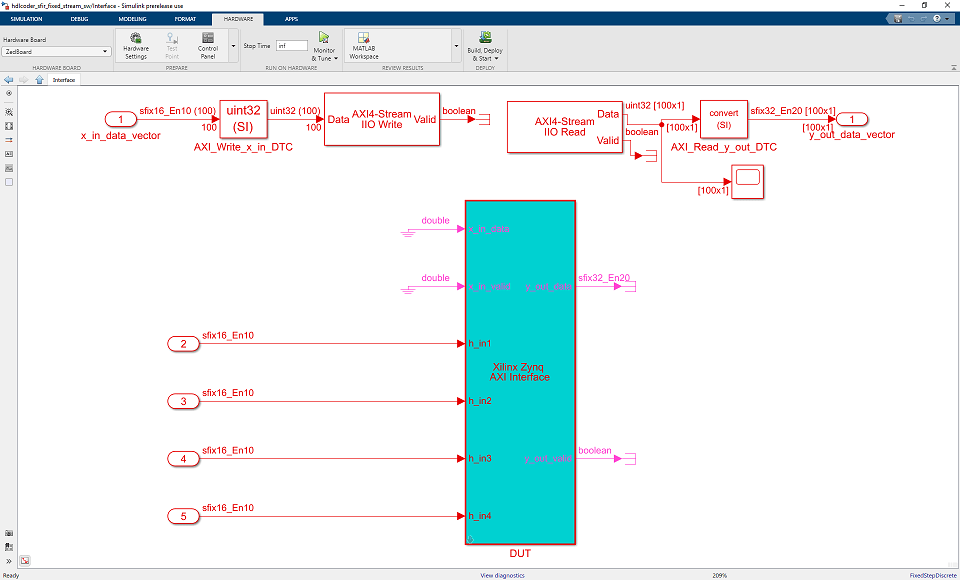
a. [Simulink ライブラリ ブラウザー]、[Embedded Coder Support Package for Xilinx Zynq Platform] ライブラリから AXI4-Stream IIO Read ドライバー ブロックと AXI4-Stream IIO Write ドライバー ブロックを追加します。
b. ベクトル データ ソースを使用して x_in_data 端子を駆動します。
c. x_in_data 端子をドライバー ブロックに接続します。
d. AXI4-Stream IIO Write ブロックをダブルクリックして [タイムアウト] を [inf] ではなく [0] に設定します。これを以下に示します。

e. AXI4-Stream IIO Write ブロックの優先順位を 1 に設定して、読み取りの前に書き込みが発生するようにします。優先順位を設定するには、ブロックを右クリックしてプロパティを開き、優先順位を 1 に設定します。これを以下に示します。

f. AXI4-Stream IIO Read ブロックをダブルクリックして、[フレーム サイズ] を [100]、[サンプル時間] を [Ts]、[タイムアウト] を [10] に設定します。これを以下に示します。

g. AXI4-Stream IIO Read ブロックの優先順位を設定する必要はありません。Write ブロックの優先順位を 1 に設定するだけで、書き込みが読み取りの前に発生することになります。
この例では、更新されたソフトウェア インターフェイス モデル hdlcoder_sfir_fixed_stream_sw が提供されます。このモデルでは 100 個のデータ要素をもつベクトル データ ソースが使用され、AXI4-Stream DMA ドライバー ブロックに接続されます。これは、プロセッサのサンプル時間ごとに、DMA コントローラーは、AXI4-Stream インターフェイスを介して HDL IP コアに対して 100 個の 32 ビット データ サンプルをストリーミングし、100 個の 32 ビット ストリーミング データ サンプルを受信することを意味します。
2. エクスターナル モードのソフトウェア インターフェイス モデルを構成してビルドします。
a. 生成されたモデルで、[ハードウェア] ペインをクリックして [ハードウェア設定] に移動し、[コンフィギュレーション パラメーター] ダイアログ ボックスを開きます。
b. [ソルバー] を選択して [終了時間] を [inf] に設定します。
c. [ハードウェア] ペインから [監視と調整] ボタンをクリックします。
d. モデル ツールストリップで [実行] ボタンをクリックします。Embedded Coder は、モデルを構築し、ARM 実行可能ファイルを ZedBoard ハードウェアにダウンロードして、これを実行し、モデルを ZedBoard ハードウェアで実行しているこの実行可能ファイルに接続します。
3. これで、設計のハードウェア部分とソフトウェア部分が Zynq ハードウェアで実行されます。ARM プロセッサは、DMA コントローラーと AXI4-Stream インターフェイスを介してソース データを FPGA IP に送信します。ARM プロセッサは、FPGA IP からフィルター結果データを受信し、エクスターナル モードを介して結果データを Simulink に送信します。時間スコープ y_out で、Zynq ハードウェアからの FIR フィルター IP コアの出力を確認します。

4. ソフトウェア インターフェイス モデルの FIR フィルター パラメーターを調整して、パラメーターの調整に従って FIR フィルターの出力がどのように変化するかを観察します。パラメーター値は、エクスターナル モードと AXI4-Lite インターフェイスを介して Zynq ハードウェアに送信されます。

