Speech Enhancement with Gain in Frequency Domain
Remove background noise from a speech signal in the frequency domain by applying a selective gain on the signal.
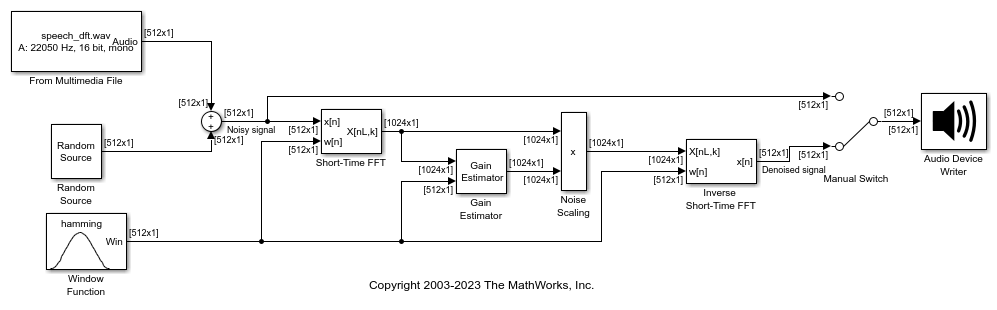
Start by computing the short-time FFT (STFT) of a noisy signal, then apply noise suppression gain on the STFT data to denoise the signal, and then convert the denoised signal back into time domain using the inverse short-time FFT technique. You can play this processed signal to an audio device using the Audio Device Writer block. By toggling the manual switch, you can choose to play either the original noisy signal or the denoised signal.
Open the exSpeechEnhancementUsingSTSA.slx model. The input is a single-channel noisy speech signal with a sample rate of 22050 Hz. The wide broadband noise added to the signal is a zero-mean white Gaussian noise with a variance of 0.0025. The signal contains 512 samples in each frame.
Run the model. The Short-Time FFT block computes the STFT of the noisy signal. The block uses a Hamming window of length 512 taps as the analysis window. The output of the Short-Time FFT block goes to a Gain Estimator block that estimates the gain for noise suppression. Applying this gain to the STFT output lifts the subbands and frames that are less noisy and weighs down on those that are more noisy. The Inverse Short-Time FFT block then reconstructs the time-domain version of the signal. You can play this denoised signal to an audio device using the Audio Device Writer block.
See Also
Short-Time FFT | Inverse Short-Time FFT | From Multimedia File | Random Source | Audio Device Writer