テキスト復号化器モデル関数の定義
この例では、テキスト復号化器モデル関数の定義方法を示します。
深層学習のコンテキストでは、復号化器は、潜在ベクトルを何らかのサンプル空間にマッピングする深層学習ネットワークの一部です。さまざまなタスクにベクトルの復号化を使用できます。以下に例を示します。
符号化されたベクトルを使用して再帰型ネットワークを初期化するテキスト生成。
符号化されたベクトルをコンテキスト ベクトルとして使用する sequence-to-sequence 変換。
符号化されたベクトルをコンテキスト ベクトルとして使用するイメージ キャプション。
データの読み込み
符号化されたデータを sonnetsEncoded.mat から読み込みます。この MAT ファイルには、単語符号化、シーケンス X のミニバッチ、対応する符号化されたデータ Z (テキスト符号化器モデル関数の定義の例で使用した符号化器によって出力されたもの) が含まれます。
s = load("sonnetsEncoded.mat");
enc = s.enc;
X = s.X;
Z = s.Z;
[latentDimension,miniBatchSize] = size(Z,1:2);モデル パラメーターの初期化
復号化器の目的は、いくらかの初期入力データとネットワークの状態から、シーケンスを生成することです。
次のモデルのパラメーターを初期化します。
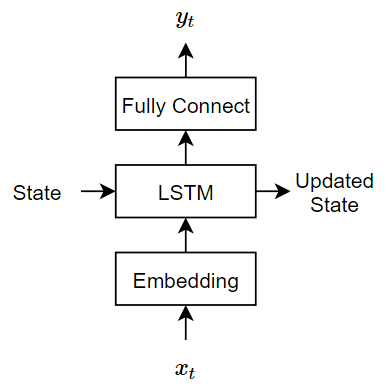
復号化器は、符号化器の出力を初期化した LSTM を使用して入力を再構成します。タイム ステップごとに、復号化器は次のタイム ステップを予測し、次のタイム ステップ予測の出力を使用します。符号化器と復号化器の両方で同じ埋め込みを使用します。
このモデルでは、次の 3 つの操作を行います。
埋め込みでは、範囲 1 ~
vocabularySizeで単語インデックスを次元embeddingDimensionのベクトルにマッピングします。ここで、vocabularySizeは符号化ボキャブラリの単語数、embeddingDimensionは埋め込みによって学習されたコンポーネントの数です。LSTM 演算では、単一の単語ベクトルを入力として受け取り、1 x
numHiddenUnitsのベクトルを出力します。ここで、numHiddenUnitsは LSTM 演算での隠れユニットの数です。LSTM ネットワークの初期状態 (最初のタイム ステップの状態) は符号化されたベクトルであるため、隠れユニットの数は符号化器の潜在次元と一致しなければなりません。全結合演算では、入力と、バイアスを加算した重み行列を乗算し、サイズ
vocabularySizeのベクトルを出力します。
パラメーターの次元を指定します。埋め込みサイズは、復号化器と一致しなければなりません。
embeddingDimension = 100; vocabularySize = enc.NumWords; numHiddenUnits = latentDimension;
パラメーターの struct を作成します。
parameters = struct;
関数 initializeGaussian を使用し、ガウスで埋め込みの重みを初期化します。この関数は、この例にサポート ファイルとして添付されています。平均値を 0、標準偏差を 0.01 に指定します。詳細については、ガウスによる初期化を参照してください。
sz = [embeddingDimension vocabularySize]; mu = 0; sigma = 0.01; parameters.emb.Weights = initializeGaussian(sz,mu,sigma);
復号化器の LSTM 演算に関する学習可能なパラメーターを初期化します。
関数
initializeGlorotを使用し、Glorot 初期化子で入力の重みを初期化します。この関数は、この例にサポート ファイルとして添付されています。詳細については、Glorot の初期化を参照してください。関数
initializeOrthogonalを使用し、直交初期化子で再帰重みを初期化します。この関数は、この例にサポート ファイルとして添付されています。詳細については、直交初期化を参照してください。関数
initializeUnitForgetGateを使用し、ユニット忘却ゲート初期化子でバイアスを初期化します。この関数は、この例にサポート ファイルとして添付されています。詳細については、ユニット忘却ゲートによる初期化を参照してください。
学習可能なパラメーターのサイズは、入力のサイズによって異なります。LSTM 演算への入力は埋め込み演算からの単語ベクトルのシーケンスであるため、入力チャネルの数は embeddingDimension になります。
入力重み行列のサイズは
4*numHiddenUnitsxinputSizeです。ここで、inputSizeは入力データの次元です。再帰重み行列のサイズは
4*numHiddenUnitsxnumHiddenUnitsです。バイアス ベクトルのサイズは
4*numHiddenUnitsx 1 です。
sz = [4*numHiddenUnits embeddingDimension]; numOut = 4*numHiddenUnits; numIn = embeddingDimension; parameters.lstmDecoder.InputWeights = initializeGlorot(sz,numOut,numIn); parameters.lstmDecoder.RecurrentWeights = initializeOrthogonal([4*numHiddenUnits numHiddenUnits]); parameters.lstmDecoder.Bias = initializeUnitForgetGate(numHiddenUnits);
符号化器の全結合演算に関する学習可能なパラメーターを初期化します。
Glorot 初期化子を使用して重みを初期化します。
関数
initializeZerosを使用し、ゼロでバイアスを初期化します。この関数は、この例にサポート ファイルとして添付されています。詳細については、ゼロでの初期化を参照してください。
学習可能なパラメーターのサイズは、入力のサイズによって異なります。全結合演算への入力は LSTM 演算の出力であるため、入力チャネルの数は numHiddenUnits になります。全結合演算でサイズ latentDimension のベクトルを出力するには、出力サイズを latentDimension に指定します。
重み行列のサイズは
outputSizexinputSizeです。ここで、outputSizeとinputSizeは、出力と入力の次元にそれぞれ対応します。バイアス ベクトルのサイズは
outputSizex 1 です。
全結合演算でサイズ vocabularySize のベクトルを出力するには、出力サイズを vocabularySize に指定します。
sz = [vocabularySize numHiddenUnits]; mu = 0; sigma = 1; parameters.fcDecoder.Weights = initializeGaussian(sz,mu,sigma); parameters.fcDecoder.Bias = initializeZeros([vocabularySize 1]);
モデル復号化器関数の定義
この例の復号化器モデル関数の節にリストされている関数 modelDecoder を作成し、復号化器モデルの出力を計算します。関数 modelDecoder は、モデル パラメーターおよびシーケンス長を単語インデックスの入力シーケンスとして受け取り、対応する潜在特徴ベクトルを返します。
モデル損失関数でのモデル関数の使用
カスタム学習ループを使用して深層学習モデルの学習を行う場合、学習可能なパラメーターについての損失および損失の勾配を計算しなければなりません。この計算は、モデル関数のフォワード パスの出力によって異なります。
復号化器でテキスト データを生成するための一般的なアプローチは次の 2 つです。
閉ループ — タイム ステップごとに、前の予測を入力として使用して予測を行います。
開ループ — タイム ステップごとに、外部ソースからの入力 (学習ターゲットなど) を使用して予測を行います。
閉ループ生成
閉ループ生成では、モデルが一度に 1 タイム ステップずつデータを生成し、前の予測を次の予測の入力として使用します。開ループ生成とは異なり、このプロセスでは予測間の入力を必要としません。また、このプロセスは、監視のないシナリオに最適です。例としては、出力テキストを 1 回で生成する言語翻訳モデルが挙げられます。
符号化器出力 Z を使用し、LSTM ネットワークの隠れ状態を初期化します。
state = struct;
state.HiddenState = Z;
state.CellState = zeros(size(Z),'like',Z);最初のタイム ステップでは、開始トークンの配列を復号化器用の入力として使用します。簡単にするために、学習データの最初のタイム ステップから、開始トークンの配列を抽出します。
decoderInput = X(:,:,1);
復号化器出力を事前に割り当て、サイズ numClasses x miniBatchSize x sequenceLength で dlX と同じデータ型となるようにします。ここで、sequenceLength は生成に必要な長さ (学習ターゲットの長さなど) です。この例では、シーケンス長に 16 を指定します。
sequenceLength = 16; Y = zeros(vocabularySize,miniBatchSize,sequenceLength,"like",X); Y = dlarray(Y,"CBT");
タイム ステップごとに、関数 modelDecoder を使用してシーケンスの次のタイム ステップを予測します。各予測の後に、複合化器出力の最大値に対応するインデックスを見つけ、そのインデックスを次のタイム ステップの複合化器入力として使用します。
for t = 1:sequenceLength [Y(:,:,t), state] = modelDecoder(parameters,decoderInput,state); [~,idx] = max(Y(:,:,t)); decoderInput = idx; end
出力は vocabularySize x miniBatchSize x sequenceLength の配列です。
size(Y)
ans = 1×3
3595 32 16
このコードの抜粋は、モデル勾配関数内で閉ループ生成を実行する例を示しています。
function [loss,gradients] = modelLoss(parameters,X,sequenceLengths) % Encode input. Z = modelEncoder(parameters,X,sequenceLengths); % Initialize LSTM state. state = struct; state.HiddenState = Z; state.CellState = zeros(size(Z),"like",Z); % Initialize decoder input. decoderInput = X(:,:,1); % Closed loop prediction. sequenceLength = size(X,3); Y = zeros(numClasses,miniBatchSize,sequenceLength,"like",X); for t = 1:sequenceLength [Y(:,:,t), state] = modelDecoder(parameters,decoderInput,state); [~,idx] = max(Y(:,:,t)); decoderInput = idx; end % Calculate loss. % ... % Calculate gradients. % ... end
開ループ生成: 教師強制
閉ループ生成で学習を行う際、シーケンスの各ステップで最も有力な単語を予測することが、準最適の結果につながる可能性があります。たとえば、イメージ キャプション ワークフローにおいて、復号化器に象のイメージが与えられて、キャプションの最初の単語が "a" と予測された場合、英語のテキストに "a elephant" というフレーズが出現する可能性は極端に低いため、次の単語として "elephant" が予測される可能性は大幅に低くなります。
ネットワークの収束を高速化するために、"教師強制" を使用することができます。これは、ターゲット値を前の予測ではなく復号化器への入力として使用する方法です。教師強制は、ネットワークがシーケンスの以前のタイム ステップを正しく生成するのを待たずに、シーケンスの以降のタイム ステップから特性をネットワークに学習させるのに役立ちます。
教師強制を実行するには、関数 modelEncoder を、ターゲット シーケンスを入力として直接使用します。
符号化器出力 Z を使用し、LSTM ネットワークの隠れ状態を初期化します。
state = struct;
state.HiddenState = Z;
state.CellState = zeros(size(Z),"like",Z);ターゲット シーケンスを入力として使用し、予測を行います。
Y = modelDecoder(parameters,X,state);
出力は vocabularySize x miniBatchSize x sequenceLength の配列です。ここで、sequenceLength は入力シーケンスの長さです。
size(Y)
ans = 1×3
3595 32 14
このコードの抜粋は、モデル勾配関数内で教師強制を実行する例を示しています。
function [loss,gradients] = modelLoss(parameters,X,sequenceLengths) % Encode input. Z = modelEncoder(parameters,X); % Initialize LSTM state. state = struct; state.HiddenState = Z; state.CellState = zeros(size(Z),"like",Z); % Teacher forcing. Y = modelDecoder(parameters,X,state); % Calculate loss. % ... % Calculate gradients. % ... end
復号化器モデル関数
関数 modelDecoder は、モデル パラメーター、単語インデックスのシーケンス、ネットワークの状態を入力として受け取り、復号化されたシーケンスを返します。
関数 lstm は "ステートフル" (時系列が入力として与えられたとき、関数が各タイム ステップ間の状態を伝播および更新する) であり、関数 embed および fullyconnect は既定で時間分散型である (時系列が入力として与えられたとき、関数が各タイム ステップに対して個別に演算を行う) ため、関数 modelDecoder はシーケンスと単一のタイム ステップ入力の両方をサポートしています。
function [Y,state] = modelDecoder(parameters,X,state) % Embedding. weights = parameters.emb.Weights; X = embed(X,weights); % LSTM. inputWeights = parameters.lstmDecoder.InputWeights; recurrentWeights = parameters.lstmDecoder.RecurrentWeights; bias = parameters.lstmDecoder.Bias; hiddenState = state.HiddenState; cellState = state.CellState; [Y,hiddenState,cellState] = lstm(X,hiddenState,cellState, ... inputWeights,recurrentWeights,bias); state.HiddenState = hiddenState; state.CellState = cellState; % Fully connect. weights = parameters.fcDecoder.Weights; bias = parameters.fcDecoder.Bias; Y = fullyconnect(Y,weights,bias); end
参考
dlfeval | dlgradient | dlarray