sequence-to-sequence LSTM ネットワーク向けのコード生成
この例では、長短期記憶 (LSTM) ネットワーク用の CUDA® コードを生成する方法を説明します。この例では、入力 timeseries の各ステップでの予測を行う MEX アプリケーションを生成します。次の 2 つの方法について説明します。1 つは標準の LSTM ネットワークを使用する方法、もう 1 つは同じ LSTM ネットワークのステートフルな動作を利用する方法です。この例では、身体に装着したスマートフォンから得られた加速度計のセンサー データを使用して、装着者のアクティビティについての予測を行います。ユーザーの動きは 5 つのカテゴリのうちの 1 つに分類されます。カテゴリは、ダンス中、ランニング中、着席中、起立中、歩行中です。この例では事前学習済みの LSTM ネットワークを使用します。学習の詳細については、Deep Learning Toolbox™ からの深層学習を使用したシーケンスの分類の例を参照してください。
サードパーティの前提条件
必要
この例では、CUDA MEX を生成します。以下のサードパーティ要件が適用されます。
CUDA 対応 NVIDIA® GPU および互換性のあるドライバー。
オプション
スタティック ライブラリ、ダイナミック ライブラリ、または実行可能ファイルなどの MEX 以外のビルドについて、この例では以下の要件も適用されます。
NVIDIA Toolkit。
コンパイラおよびライブラリの環境変数。詳細については、サードパーティ ハードウェア (GPU Coder)と前提条件となる製品の設定 (GPU Coder)を参照してください。
GPU 環境の検証
関数coder.checkGpuInstall (GPU Coder)を使用して、この例を実行するのに必要なコンパイラおよびライブラリが正しく設定されていることを検証します。
envCfg = coder.gpuEnvConfig('host');
envCfg.DeepCodegen = 1;
envCfg.Quiet = 1;
coder.checkGpuInstall(envCfg);
エントリポイント関数 lstmnet_predict
sequence-to-sequence LSTM ネットワークでは、データ シーケンスの個々のタイム ステップで異なる予測を行うことができます。エントリポイント関数 lstmnet_predict.m は、入力シーケンスを受け取り、予測用の学習済み LSTM ネットワークに渡します。特に、この関数は "深層学習を使用した sequence-to-sequence 分類" の例で学習させた LSTM ネットワークを使用します。dlarray オブジェクトはエントリポイント関数内で作成され、関数への入力と出力のデータ型はプリミティブ型になります。このエントリポイント関数は、dlnetwork オブジェクトを lstmnet.mat ファイルから永続変数に読み込み、以降の予測呼び出しではその永続オブジェクトを再利用します。詳細については、dlarray 用のコード生成 (GPU Coder)を参照してください。
ネットワーク アーキテクチャの対話的な可視化とネットワーク層についての詳細情報を表示するには、関数analyzeNetworkを使用します。
type('lstmnet_predict.m')function out = lstmnet_predict(in) %#codegen
% Copyright 2019-2024 The MathWorks, Inc.
dlIn = dlarray(in,'CT');
persistent dlnet;
if isempty(dlnet)
dlnet = coder.loadDeepLearningNetwork('lstmnet.mat');
end
dlOut = predict(dlnet,dlIn);
out = extractdata(dlOut);
end
CUDA MEX の生成
エントリポイント関数 lstmnet_predict.m 用の CUDA MEX を生成するには、GPU の構成オブジェクトを作成し、ターゲットを MEX にするよう指定します。ターゲット言語を C++ に設定します。ターゲット ライブラリを none として指定する深層学習構成オブジェクトを作成します。この深層学習構成オブジェクトを GPU 構成オブジェクトに追加します。
cfg = coder.gpuConfig('mex'); cfg.DeepLearningConfig = coder.DeepLearningConfig('TargetLibrary','none');
コンパイル時に、GPU Coder™ はエントリポイント関数のすべての入力についてデータ型を把握していなければなりません。関数coder.typeof (MATLAB Coder)を使用して、入力引数の型とサイズをcodegen (MATLAB Coder)コマンドに指定します。この例では、入力は特徴次元値 3 と可変のシーケンス長をもつ double のデータ型です。シーケンス長を可変サイズとして指定することで、任意の長さの入力シーケンスについての予測を実行できるようになります。
matrixInput = coder.typeof(single(0),[3 Inf],[false true]);
codegen コマンドを実行します。
codegen -config cfg lstmnet_predict -args {matrixInput} -report
Code generation successful: View report
生成された MEX のテスト データについての実行
HumanActivityValidate MAT ファイルには、生成コードをテストできるセンサーの読み取り値のサンプル timeseries を含む変数 XValidate が格納されます。MAT ファイルを読み込み、展開のためにデータを single にキャストします。最初の観測値について lstmnet_predict_mex を呼び出します。
load HumanActivityValidate XValidate = cellfun(@single, XValidate, 'UniformOutput', false); YPred1 = lstmnet_predict_mex(XValidate{1});
YPred1 は、53888 のタイム ステップのそれぞれについての 5 つのクラスの確率を含む 5 行 53888 列の数値行列です。各タイム ステップについて、最大確率のインデックスを計算して、予測されたクラスを見つけます。
[~, maxIndex] = max(YPred1, [], 1);
最大確率のインデックスを対応するラベルに関連付けます。最初の 10 個のラベルを表示します。その結果から、ネットワークはその人が最初の 10 のタイム ステップの間、座っていると予測したことがわかります。
labels = categorical({'Dancing', 'Running', 'Sitting', 'Standing', 'Walking'});
predictedLabels1 = labels(maxIndex);
disp(predictedLabels1(1:10)') Sitting
Sitting
Sitting
Sitting
Sitting
Sitting
Sitting
Sitting
Sitting
Sitting
予測とテスト データとの比較
プロットを使用して MEX の出力データをテスト データと比較します。
figure plot(predictedLabels1,'.-'); hold on plot(YValidate{1}); hold off xlabel("Time Step") ylabel("Activity") title("Predicted Activities") legend(["Predicted" "Test Data"])
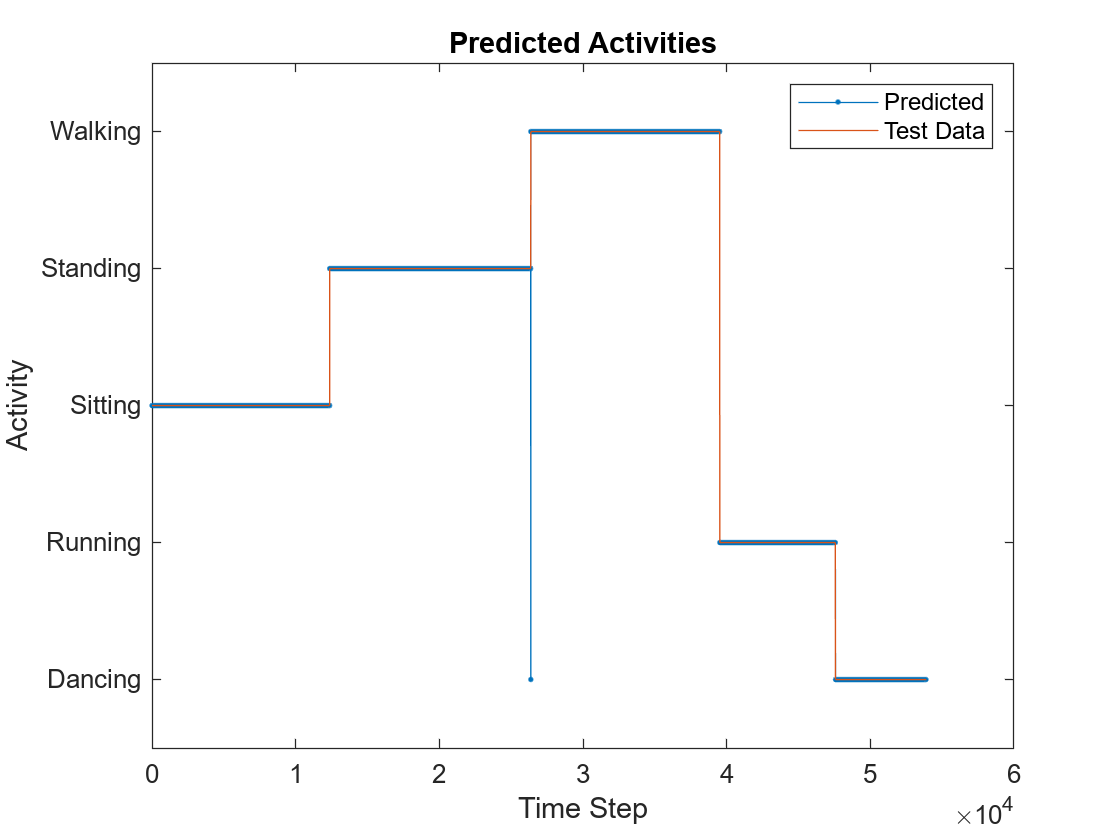
異なるシーケンス長をもつ観測値についての生成された MEX の呼び出し
異なるシーケンス長をもつ 2 番目の観測値について lstmnet_predict_mex を呼び出します。この例では、XValidate{2} はシーケンス長が 64480 である一方、XValidate{1} はシーケンス長が 53888 でした。シーケンス長の次元を可変サイズに指定したため、生成コードは予測を正しく処理します。
YPred2 = lstmnet_predict_mex(XValidate{2});
[~, maxIndex] = max(YPred2, [], 1);
predictedLabels2 = labels(maxIndex);
disp(predictedLabels2(1:10)') Sitting
Sitting
Sitting
Sitting
Sitting
Sitting
Sitting
Sitting
Sitting
Sitting
ステートフルな LSTM を使用した MEX の生成
timeseries 全体を渡して 1 ステップで予測する代わりに、dlnetwork の状態を更新して 1 タイムステップずつストリーミングすることにより、入力についての予測を実行できます。関数predictを使用することにより、更新されたネットワーク状態とともに出力予測を生成することができます。この関数 lstmnet_predict_and_update は、単一のタイムステップ入力を受け取り、以降の入力が同じサンプルに続くタイムステップとして扱われるようにネットワークの状態を更新します。すべてのタイム ステップを一度に渡した場合、結果の出力は、すべてのタイム ステップが単一の入力として渡された場合と同じになります。
type('lstmnet_predict_and_update.m')function out = lstmnet_predict_and_update(in) %#codegen
% Copyright 2019-2024 The MathWorks, Inc.
dlIn = dlarray(in,'CT');
persistent dlnet;
if isempty(dlnet)
dlnet = coder.loadDeepLearningNetwork('lstmnet.mat');
end
[dlOut, updatedState] = predict(dlnet, dlIn);
dlnet.State = updatedState;
out = extractdata(dlOut);
end
この新しい設計ファイルで codegen を実行します。呼び出しごとに単一のタイム ステップを受け取るため、matrixInput を指定して、可変シーケンス長の代わりに、シーケンス次元を 1 に固定します。
cfg = coder.gpuConfig('mex'); cfg.DeepLearningConfig = coder.DeepLearningConfig('TargetLibrary','none'); matrixInput = coder.typeof(single(0),[3 1]); codegen -config cfg lstmnet_predict_and_update -args {matrixInput} -report
Code generation successful: View report
最初の検証サンプルの最初のタイム ステップについて生成された MEX を実行します。
firstSample = XValidate{1};
firstTimestep = firstSample(:,1);
YPredStateful = lstmnet_predict_and_update_mex(firstTimestep);
[~, maxIndex] = max(YPredStateful, [], 1);
predictedLabelsStateful1 = labels(maxIndex)predictedLabelsStateful1 = categorical
Sitting
出力ラベルをグラウンド トゥルースと比較します。
YValidate{1}(1)ans = categorical
Sitting