このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
浅層ニューラル ネットワークによるパターン認識
関数近似に加えて、ニューラル ネットワークはパターン認識にも適しています。
たとえば、細胞の大きさの均一性、細胞塊の厚さ、有糸分裂などに基づいて、腫瘍を良性または悪性に分類する必要があるとします。9 個の特徴をもつ 699 個のサンプル ケースがあり、それぞれ良性と悪性が正しく分類されています。
関数近似の場合と同様に、この問題を解くには 2 つの方法があります。
ニューラル ネット パターン認識アプリを使用したパターン認識の説明に従って、ニューラル ネット パターン認識アプリを使用。
コマンド ライン関数を使用したパターン認識の説明に従って、コマンド ライン関数を使用。
通常、はじめにアプリを使用し、次にアプリを使用してコマンド ライン スクリプトを自動的に生成することをお勧めします。どちらの方法を使用する場合にも、まずデータセットを選択することによって問題を定義します。それぞれのニューラル ネットワーク アプリから多くの標本データ セットにアクセスし、これらを使用してツールボックスを試すことができます (浅層ニューラル ネットワーク用の標本データセットを参照してください)。特定の問題を解く必要がある場合、独自のデータをワークスペースに読み込むことができます。次の節では、データ形式について説明します。
メモ
深層学習ニューラル ネットワークの構築、可視化、および学習を対話的に行うには、ディープ ネットワーク デザイナー アプリを使用します。詳細については、ディープ ネットワーク デザイナー入門を参照してください。
問題の定義
パターン認識問題を定義するには、一連の入力ベクトル (予測子) を行列の列として配置します。次に、別の応答ベクトルを、観測値が割り当てられているクラスを示すように配置します。
クラスが 2 つしかない場合、それぞれの応答は 2 つの要素 (0 または 1) をもち、対応する観測値がどちらのクラスに属するかを示します。たとえば、2 つのクラスの分類問題は次のように定義できます。
predictors = [7 10 3 1 6; 5 8 1 1 6; 6 7 1 1 6]; responses = [0 0 1 1 0; 1 1 0 0 1];
予測子が N 個の異なるクラスに分類される場合、応答の要素数は N 個になります。各応答について、1 つの要素が 1 になり、他の要素は 0 になります。たとえば、5 x 5 x 5 の立方体の頂点を 3 つのクラスに分割する分類問題は、次のように定義します。
1 つのクラスに原点 (最初の入力ベクトル) が含まれる
2 番目のクラスに原点から最も離れた頂点 (最後の入力ベクトル) が含まれる
3 番目のクラスにその他のすべての点が含まれる
predictors = [0 0 0 0 5 5 5 5; 0 0 5 5 0 0 5 5; 0 5 0 5 0 5 0 5]; responses = [1 0 0 0 0 0 0 0; 0 1 1 1 1 1 1 0; 0 0 0 0 0 0 0 1];
次の節では、ニューラル ネット パターン認識アプリを使用して、パターンを認識するようにネットワークに学習させる方法を説明します。この例では、ツールボックスに用意されているサンプル データ セットを使用します。
ニューラル ネット パターン認識アプリを使用したパターン認識
この例では、"ニューラル ネット パターン認識" アプリを使用して、パターンを分類するように浅層ニューラル ネットワークに学習させる方法を説明します。
nprtool を使用して、"ニューラル ネット パターン認識" アプリを開きます。
nprtool
データの選択
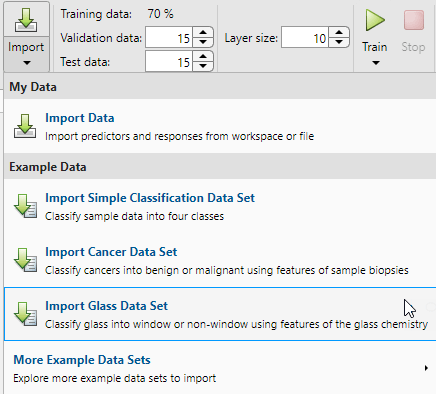
"ニューラル ネット パターン認識" アプリには、ニューラル ネットワークの学習を始めるのに役立つサンプル データが用意されています。
サンプルのガラス分類データをインポートするには、[インポート]、[ガラス データセットのインポート] を選択します。このデータ セットを使用し、ガラスの化学的特性に基づいてガラスを窓または窓以外に分類するように、ニューラル ネットワークに学習させることができます。ファイルまたはワークスペースから自分のデータをインポートする場合は、予測子と応答、および観測値が行と列のどちらで与えられるかを指定しなければなりません。
インポートしたデータに関する情報は、[モデルの概要] に表示されます。このデータ セットには、それぞれ 9 個の特徴をもつ 214 個の観測値が含まれています。各観測値は、2 つのクラス (窓と窓以外) のいずれかに分類されます。

データを学習セット、検証セット、テスト セットに分割します。既定の設定はそのままにします。データを以下のように分割します。
学習用に 70% を使用。
ネットワークが汎化されていることを検証し、過適合の発生前に学習を停止するために 15% を使用。
ネットワークの汎化の独立したテスト用に 15% を使用。
データ分割の詳細については、ニューラル ネットワークの最適な学習のためのデータの分割を参照してください。
ネットワークの作成
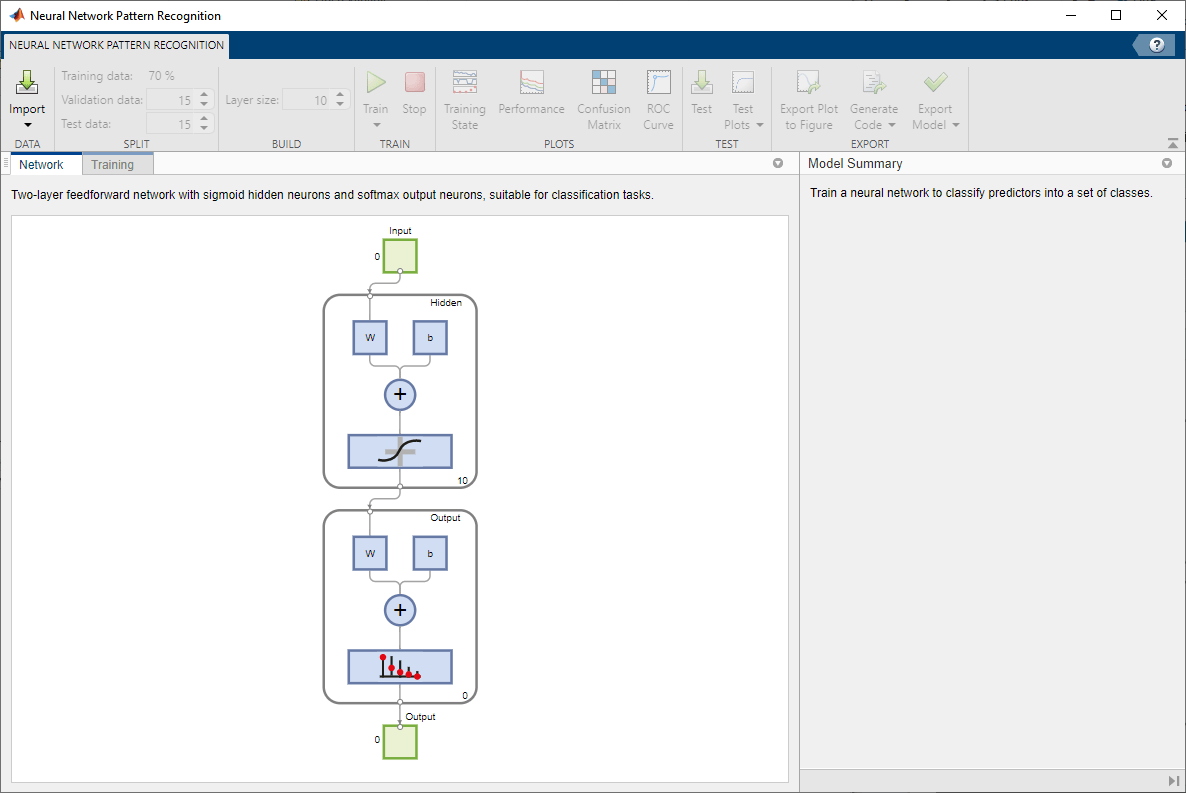
このネットワークは、隠れ層にシグモイド伝達関数、出力層にソフトマックス伝達関数を使用した 2 層フィードフォワード ネットワークです。隠れ層のサイズは、隠れニューロンの数と一致します。既定の層のサイズは 10 です。ネットワーク アーキテクチャは [ネットワーク] ペインで確認できます。出力ニューロンの数は 2 に設定されます。これは、応答データで指定されたクラスの数と同じです。

ネットワークの学習
ネットワークの学習を行うには、[学習] をクリックします。
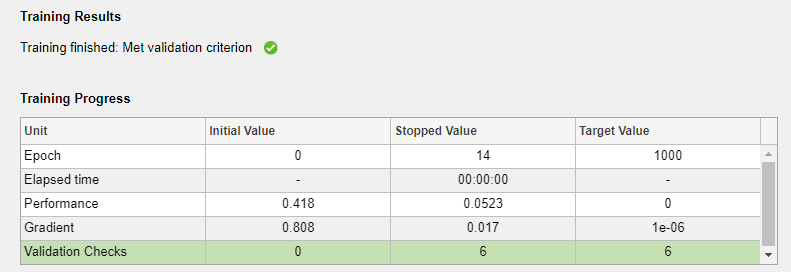
[学習] ペインで学習の進行状況を確認できます。いずれかの停止条件が満たされるまで学習が続行されます。この例では、6 回の反復の間に検証誤差が連続して増加するまで ("検証基準に適合" するまで) 学習が続行されます。
結果の解析
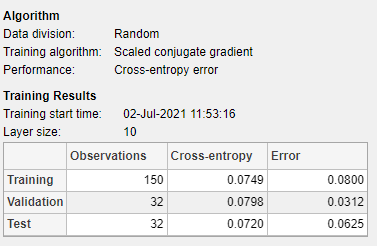
[モデルの概要] に、学習アルゴリズムの情報および各データ セットに対する学習結果が表示されます。
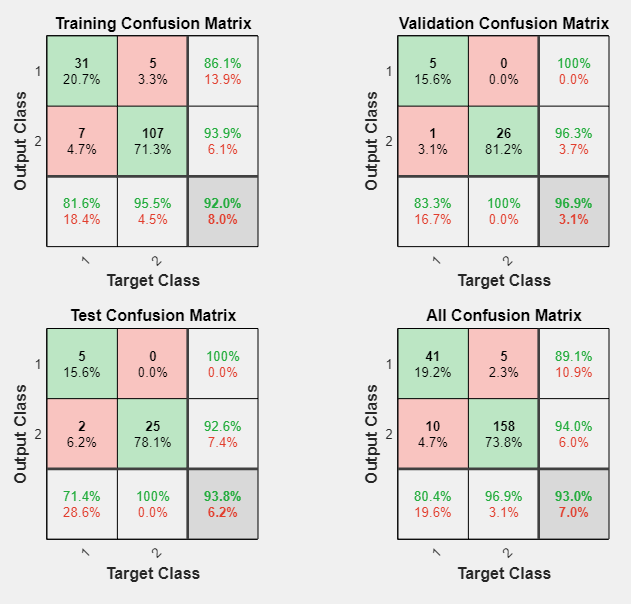
プロットを生成すると、結果をさらに詳しく解析できます。混同行列をプロットするには、[プロット] セクションで [混同行列] をクリックします。緑色の正方形で表示されている正しい分類の数が多く (対角線上)、赤色の正方形で表示されている正しくない分類の数が少ないため (対角線外)、ネットワークの出力は非常に正確です。
ネットワーク性能をさらに検証するには、ROC 曲線を確認します。[プロット] セクションで [ROC 曲線] をクリックします。
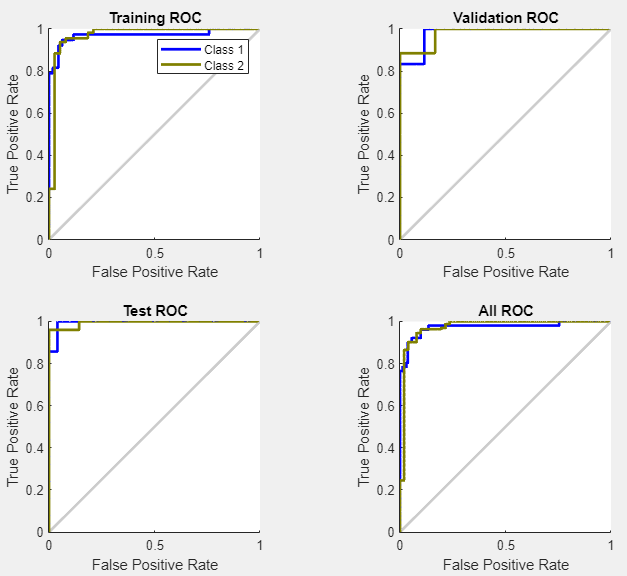
各軸の色付きの線は ROC 曲線を表します。ROC 曲線は、しきい値が変化する場合の、偽陽性率 (1 - 特異度) に対する真陽性率 (感度) のプロットです。テストに問題がなければ、左上隅に点が表示されます。これは、100% の感度と 100% の特異度を示します。この問題については、ネットワーク性能は非常に良好です。
ネットワーク性能に満足できない場合、次のいずれかを行うことができます。
ネットワークに再度学習させる。
隠れニューロンの数を増やす。
より大規模な学習データ セットを使用する。
学習セットでの性能は良好であるにもかかわらず、テスト セットでの性能が低い場合は、モデルが過適合となっている可能性があります。ニューロンの数を減らすことによって過適合を軽減できます。
追加のテスト セットでネットワーク性能を評価することもできます。ネットワークを評価するための追加のテスト データを読み込むには、[テスト] セクションで [テスト] をクリックします。[モデルの概要] に、追加のテスト結果が表示されます。プロットを生成して追加のテスト結果を解析することもできます。
コードの生成
[コード生成]、[単純な学習スクリプトを生成] を選択して MATLAB コードを作成することにより、コマンド ラインで以前に実行したステップを再現できます。MATLAB コードの作成は、ツールボックスのコマンド ライン機能を使用して学習プロセスをカスタマイズする方法を学ぶ必要がある場合に便利です。コマンド ライン関数を使用したパターン認識では、生成されるスクリプトについてさらに詳しく説明します。
ネットワークのエクスポート
学習済みネットワークをワークスペースまたは Simulink® にエクスポートできます。MATLAB Compiler™ などの MATLAB コード生成ツールを使用してネットワークを展開することもできます。学習済みネットワークとその結果をエクスポートするには、[モデルのエクスポート]、[ワークスペースにエクスポート] を選択します。
コマンド ライン関数を使用したパターン認識
ツールボックスのコマンド ライン機能の使用方法を学ぶ最も簡単な方法は、アプリからスクリプトを生成し、これらのスクリプトを変更してネットワークの学習をカスタマイズすることです。例として、前の節で ニューラル ネット パターン認識アプリを使用して作成した簡単なスクリプトを見てみましょう。
% Solve a Pattern Recognition Problem with a Neural Network % Script generated by Neural Pattern Recognition app % Created 22-Mar-2021 16:50:20 % % This script assumes these variables are defined: % % glassInputs - input data. % glassTargets - target data. x = glassInputs; t = glassTargets; % Choose a Training Function % For a list of all training functions type: help nntrain % 'trainlm' is usually fastest. % 'trainbr' takes longer but may be better for challenging problems. % 'trainscg' uses less memory. Suitable in low memory situations. trainFcn = 'trainscg'; % Scaled conjugate gradient backpropagation. % Create a Pattern Recognition Network hiddenLayerSize = 10; net = patternnet(hiddenLayerSize, trainFcn); % Setup Division of Data for Training, Validation, Testing net.divideParam.trainRatio = 70/100; net.divideParam.valRatio = 15/100; net.divideParam.testRatio = 15/100; % Train the Network [net,tr] = train(net,x,t); % Test the Network y = net(x); e = gsubtract(t,y); performance = perform(net,t,y) tind = vec2ind(t); yind = vec2ind(y); percentErrors = sum(tind ~= yind)/numel(tind); % View the Network view(net) % Plots % Uncomment these lines to enable various plots. %figure, plotperform(tr) %figure, plottrainstate(tr) %figure, ploterrhist(e) %figure, plotconfusion(t,y) %figure, plotroc(t,y)
スクリプトを保存してコマンド ラインから実行すると、前の学習セッションの結果を再現できます。スクリプトを編集して、学習プロセスをカスタマイズすることもできます。この場合、スクリプトの各ステップに従います。
データの選択
このスクリプトは、予測子ベクトルと応答ベクトルがワークスペースに読み込み済みであると仮定しています。データが読み込まれていない場合、次のように読み込むことができます。
load glass_datasetglassInputs と応答 glassTargets をワークスペースに読み込みます。このデータ セットは、ツールボックスに含まれる標本データ セットの 1 つです。使用可能なデータ セットの詳細については、浅層ニューラル ネットワーク用の標本データセットを参照してください。help nndatasets コマンドを入力することによって、使用可能なすべてのデータ セットの一覧を表示することもできます。独自の変数名を使用して、これらのデータ セットから変数を読み込むことができます。たとえば、次のコマンド
[x,t] = glass_dataset;
x に読み込み、ガラスの応答を配列 t に読み込みます。学習アルゴリズムの選択
学習アルゴリズムを定義します。
trainFcn = 'trainscg'; % Scaled conjugate gradient backpropagation.
ネットワークの作成
ネットワークを作成します。パターン認識 (分類) 問題の既定のネットワーク patternnet は、隠れ層に既定のシグモイド伝達関数、出力層にソフトマックス伝達関数を使用したフィードフォワード ネットワークです。このネットワークには、10 個のニューロンがある 1 つの隠れ層があります (既定)。
各入力ベクトルには 2 つの応答値 (クラス) が関連付けられているため、ネットワークの出力ニューロンは 2 個になります。各出力ニューロンは 1 つのクラスを表します。適切なクラスの入力ベクトルがネットワークに適用されている場合、対応するニューロンによって 1 が生成され、もう一方のニューロンによって 0 が出力されるはずです。
hiddenLayerSize = 10; net = patternnet(hiddenLayerSize, trainFcn);
メモ:
ニューロンの数を増やすと、必要な計算量が多くなります。数が多すぎる場合にはデータへの過適合が生じる可能性が高くなりますが、より複雑な問題をそのネットワークで解けるようになります。層の数を増やすと、必要な計算量が多くなりますが、複雑な問題をそのネットワークでより効率的に解けるようになる可能性があります。複数の隠れ層を使用するには、隠れ層のサイズを patternnet コマンドの配列の要素として入力します。
データの分割
データの分割を設定します。
net.divideParam.trainRatio = 70/100; net.divideParam.valRatio = 15/100; net.divideParam.testRatio = 15/100;
これらの設定では、予測子ベクトルおよび応答ベクトルはランダムに分割されます。70% は学習、15% は検証、および 15% はテストに使用されます。データ分割プロセスの詳細については、ニューラル ネットワークの最適な学習のためのデータの分割を参照してください。
ネットワークの学習
ネットワークに学習をさせます。
[net,tr] = train(net,x,t);
学習中は、学習の進行状況を示すウィンドウが開きます。停止ボタン  をクリックすると、任意の時点で学習を中断できます。
をクリックすると、任意の時点で学習を中断できます。
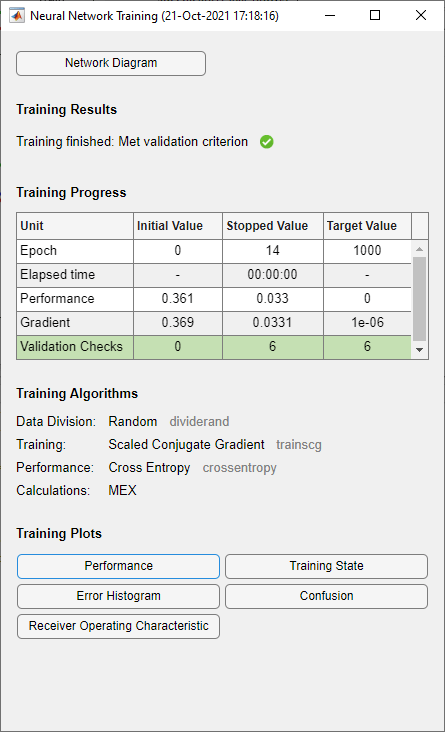
この学習は、6 回の反復の間に検証誤差が連続して増加したときに停止しています。学習の停止は、14 回目の反復で発生しています。
学習ウィンドウで [パフォーマンス] をクリックすると、次の図に示すように、学習誤差、検証誤差、およびテスト誤差のプロットが表示されます。
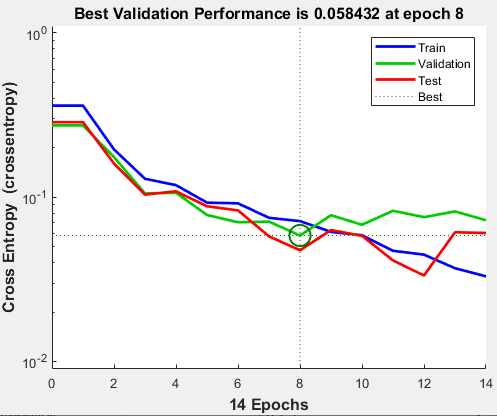
最終的な交差エントロピー誤差が小さいことを考慮すると、この例の結果は妥当であると言えます。
ネットワークのテスト
ネットワークをテストします。ネットワークの学習が終わったら、これを使用してネットワークの出力を計算できます。次のコードでは、ネットワークの出力、誤差、および全体的な性能が計算されます。
y = net(x); e = gsubtract(t,y); performance = perform(net,t,y)
performance =
0.0659誤分類された観測値の割合を計算することもできます。この例では、モデルの誤分類率が非常に低くなっています。
tind = vec2ind(t); yind = vec2ind(y); percentErrors = sum(tind ~= yind)/numel(tind)
percentErrors =
0.0514学習記録にあるテスト インデックスを使用することで、テスト セットのみでネットワーク性能を計算することも可能です
tInd = tr.testInd; tstOutputs = net(x(:,tInd)); tstPerform = perform(net,t(tInd),tstOutputs)
tstPerform =
2.0163
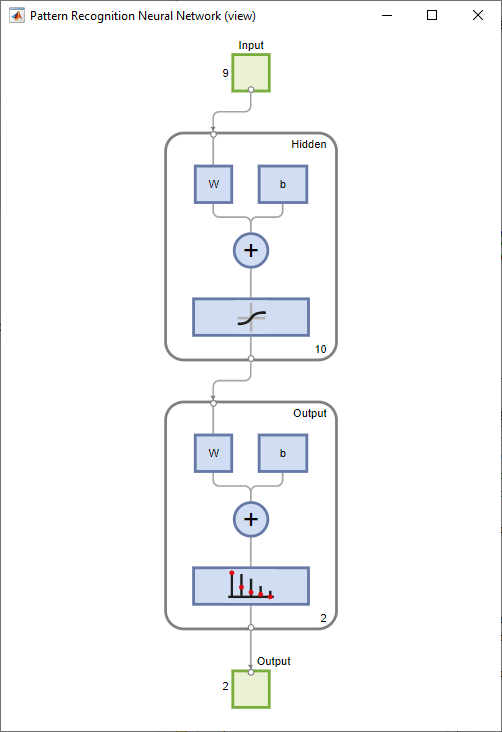
ネットワークの表示
ネットワーク図を表示します。
view(net)
結果の解析
関数 plotconfusion を使用して、混同行列をプロットします。学習ウィンドウで [混同] をクリックすることで、各データ セットの混同行列をプロットすることもできます。
figure, plotconfusion(t,y)
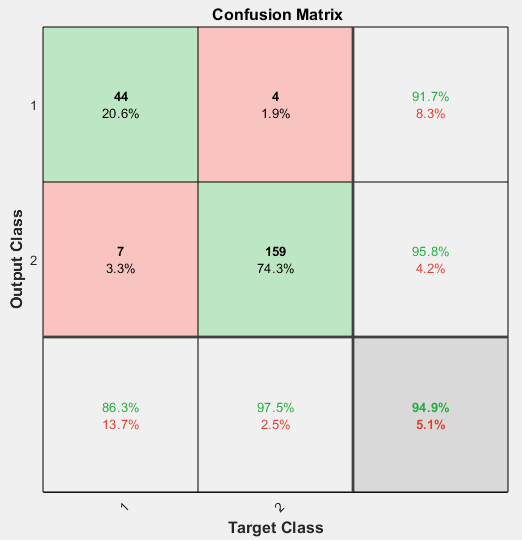
対角線上の緑のセルは正しく分類されたケースの数、対角線外の赤のセルは誤分類されたケースの数を示します。結果は、認識が非常に適切に行われていることを示しています。より正確な結果が必要な場合、次のいずれかの方法を試してください。
この場合、ネットワークの結果は満足のいくものであるため、ネットワークを新しい入力データに使用できます。
次のステップ
コマンド ライン操作に慣れるため、次のタスクを試してみましょう。
学習中にプロット ウィンドウ (混同プロットなど) を開き、アニメーションを見る。
plotroc、plottrainstateなどの関数を使用して、コマンド ラインからプロットする。
ニューラル ネットワークでは、学習を行うたびに異なる解が得られる可能性がありますが、これは初期の重みとバイアスの値がランダムであり、学習セット、検証セット、テスト セットへのデータの分割が異なるためです。このため、別のニューラル ネットワークが同じ問題について学習した場合、入力が同じでも出力が異なる場合があります。ニューラル ネットワークで高い精度が得られるようにするためには、何度か再学習を行います。
高い精度が必要な場合は、初期解を改善するための手法が他にいくつかあります。詳細については、浅層ニューラル ネットワークの汎化の改善と過適合の回避を参照してください。
参考
ニューラル ネット フィッティング | ニューラル ネット時系列 | ニューラル ネット パターン認識 | ニューラル ネット クラスタリング | ディープ ネットワーク デザイナー | trainscg
関連するトピック
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)