事前学習済みのネットワークを使用したイメージの特徴の抽出
この例では、事前学習済みの畳み込みニューラル ネットワークから学習済みのイメージの特徴を抽出し、これらの特徴を使用してイメージ分類器に学習させる方法を説明します。特徴抽出は、事前学習済みの深いネットワークの表現能力を活用できる最も簡単で時間のかからない方法です。たとえば、抽出した特徴に対して fitcecoc (Statistics and Machine Learning Toolbox™) を使用してサポート ベクター マシン (SVM) に学習させることができます。特徴抽出が必要とするものはデータを一巡する 1 つのパスのみであるため、ネットワークの学習を加速するための GPU がない場合、これは適切な開始点となります。
データの読み込み
サンプル イメージを解凍してイメージ データストアとして読み込みます。imageDatastore は、フォルダー名に基づいてイメージに自動的にラベルを付け、データを ImageDatastore オブジェクトとして格納します。イメージ データストアを使用すると、メモリに収まらないデータを含む大きなイメージ データを格納できます。データを 70% の学習データと 30% のテスト データに分割します。
unzip('MerchData.zip'); imds = imageDatastore('MerchData','IncludeSubfolders',true,'LabelSource','foldernames'); [imdsTrain,imdsTest] = splitEachLabel(imds,0.7,'randomized');
このとき、この非常に小さなデータ セットには、55 個の学習イメージと 20 個の検証イメージが格納されています。いくつかのサンプル イメージを表示します。
numTrainImages = numel(imdsTrain.Labels); idx = randperm(numTrainImages,16); figure for i = 1:16 subplot(4,4,i) I = readimage(imdsTrain,idx(i)); imshow(I) end

事前学習済みのネットワークの読み込み
事前学習済みの ResNet-18 ネットワークを読み込みます。Deep Learning Toolbox Model for ResNet-18 Network サポート パッケージがインストールされていない場合、ダウンロード用リンクが表示されます。ResNet-18 は、100 万個を超えるイメージについて学習済みであり、イメージを 1,000 個のオブジェクト カテゴリ (キーボード、マウス、鉛筆、多くの動物など) に分類できます。結果として、このモデルは広範囲のイメージに対する豊富な特徴表現を学習しています。
net = resnet18
net =
DAGNetwork with properties:
Layers: [71×1 nnet.cnn.layer.Layer]
Connections: [78×2 table]
InputNames: {'data'}
OutputNames: {'ClassificationLayer_predictions'}
ネットワーク アーキテクチャを解析します。最初の層であるイメージ入力層には、サイズが 224 x 224 x 3 の入力イメージが必要です。ここで、3 はカラー チャネルの数です。
inputSize = net.Layers(1).InputSize; analyzeNetwork(net)
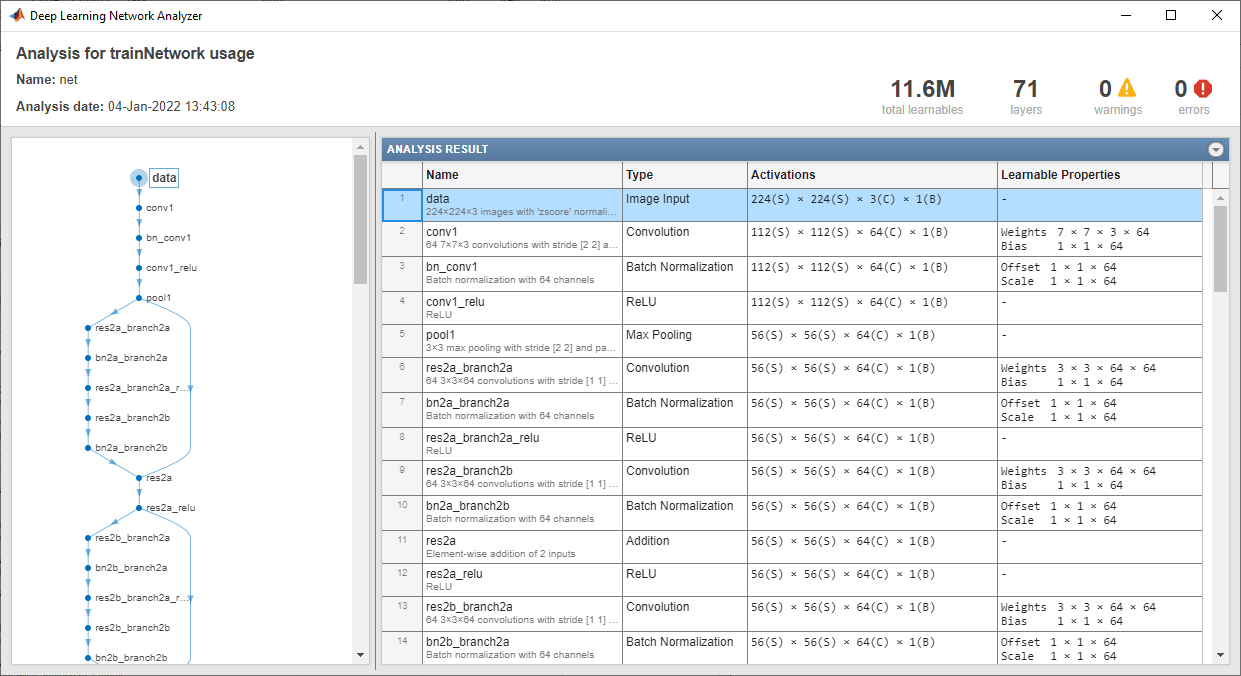
イメージの特徴の抽出
ネットワークにはサイズが 224 x 224 x 3 の入力イメージが必要ですが、イメージ データストアにあるイメージのサイズは異なります。学習およびテスト イメージのサイズをネットワークへの入力前に自動的に変更するには、拡張イメージ データストアを作成して、目的のイメージ サイズを指定し、これらのデータストアを activations の入力引数として使用します。
augimdsTrain = augmentedImageDatastore(inputSize(1:2),imdsTrain); augimdsTest = augmentedImageDatastore(inputSize(1:2),imdsTest);
ネットワークは、入力イメージの階層表現を構築します。深い層には、初期の層の低レベルの特徴を使用して構築された、より高レベルの特徴が含まれます。学習イメージとテスト イメージの特徴表現を取得するには、ネットワークの最後のグローバル プーリング層 activations で 'pool5', を使用します。グローバル プーリング層は、すべての空間位置に対して入力の特徴をプーリングします。合計で 512 個の特徴が得られます。
layer = 'pool5'; featuresTrain = activations(net,augimdsTrain,layer,'OutputAs','rows'); featuresTest = activations(net,augimdsTest,layer,'OutputAs','rows'); whos featuresTrain
Name Size Bytes Class Attributes featuresTrain 55x512 112640 single
学習データおよびテスト データからクラス ラベルを抽出します。
YTrain = imdsTrain.Labels; YTest = imdsTest.Labels;
イメージ分類器の当てはめ
学習イメージから抽出された特徴を予測子変数として使用し、fitcecoc (Statistics and Machine Learning Toolbox) を使用してマルチクラス サポート ベクター マシン (SVM) を当てはめます。
classifier = fitcecoc(featuresTrain,YTrain);
テスト イメージの分類
テスト イメージから抽出された特徴を使用する学習済みの SVM モデルで、テスト イメージを分類します。
YPred = predict(classifier,featuresTest);
4 個のサンプル テスト イメージと、その予測ラベルを表示します。
idx = [1 5 10 15]; figure for i = 1:numel(idx) subplot(2,2,i) I = readimage(imdsTest,idx(i)); label = YPred(idx(i)); imshow(I) title(char(label)) end

テスト セットに対する分類精度を計算します。精度とは、ネットワークによって予測が正しく行われるラベルの割合です。
accuracy = mean(YPred == YTest)
accuracy = 1
浅い特徴での分類器の学習
ネットワークの初期の層から特徴を抽出し、これらの特徴について分類器に学習させることもできます。通常、初期の層ではより少数の浅い特徴が抽出され、空間分解能が高く、活性化の合計数が大きくなります。'res3b_relu' 層から特徴を抽出します。これは 128 個の特徴を出力する最後の層であり、活性化の空間サイズは 28 行 28 列になります。
layer = 'res3b_relu'; featuresTrain = activations(net,augimdsTrain,layer); featuresTest = activations(net,augimdsTest,layer); whos featuresTrain
Name Size Bytes Class Attributes featuresTrain 28x28x128x55 22077440 single
この例の最初の部分で使用した抽出された特徴は、グローバル プーリング層によってすべての空間位置に対してプーリングされています。初期の層で特徴を抽出する際に同じ結果を得るには、すべての空間位置に対して活性化を手動で平均化します。N-by-C (N は観測値の数で C は特徴の数) の形式で特徴を取得するには、大きさが 1 の次元を削除し転置します。
featuresTrain = squeeze(mean(featuresTrain,[1 2]))';
featuresTest = squeeze(mean(featuresTest,[1 2]))';
whos featuresTrainName Size Bytes Class Attributes featuresTrain 55x128 28160 single
浅い特徴について SVM 分類器に学習させます。テスト精度を計算します。
classifier = fitcecoc(featuresTrain,YTrain); YPred = predict(classifier,featuresTest); accuracy = mean(YPred == YTest)
accuracy = 0.9500
学習済みの SVM はいずれも精度が高くなります。特徴抽出を使用しても十分な精度が得られない場合、代わりに転移学習を試してください。例については、新しいイメージを分類するためのニューラル ネットワークの再学習を参照してください。事前学習済みのネットワークの一覧と比較については、事前学習済みの深層ニューラル ネットワークを参照してください。
参考
fitcecoc (Statistics and Machine Learning Toolbox) | imagePretrainedNetwork