このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
GPU を使用した SISO 単一搬送波リンク シミュレーションの高速化
この例では、MATLAB® Communications Toolbox™ ソフトウェアの System object を使用して、ビット エラー レート (BER) シミュレーションを高速化するために使用できる 4 つの手法の比較を説明します。畳み込み符号化に基づき、小規模なシステムによる MATLAB® Coder™ 製品を使用したコード生成の効果、Parallel Computing Toolbox™ 製品の parfor を使用した並列ループ実行、コード生成と parfor の組み合わせ、GPU ベースの System object を示します。
この例で取り上げる System object は、Communications Toolbox 製品で利用できます。この例を実行するには、MATLAB Coder のライセンス、Parallel Computing Toolbox のライセンスおよび十分な性能の GPU が必要です。
システム設計とシミュレーション パラメーター
この例では、単純な畳み込み符号化システムを使用してシミュレーションを高速化する方法を示します。システムでは、randi を使用してランダム メッセージ ビットが生成されます。送信機はレート 1/2 畳み込み符号化器を使用してこれらのビットを符号化し、QPSK 変調スキームを適用してから、シンボルを送信します。シンボルは、信号の破損が発生する AWGN チャネルを通過します。受信機で QPSK 復調が行われ、破損したビットはビタビ アルゴリズムによって復号化されます。最後に、ビット エラー レートが計算されます。このシステムで使用する System object は、以下のとおりです。
comm.ConvolutionalEncoder - 畳み込み符号化
comm.ViterbiDecoder - ビタビ復号化
トランシーバーのコードは以下にあります。
viterbiTransceiverCPU.mviterbiTransceiverGPU.m
ビット エラー レート曲線に沿った各点が、上記の送受信コードの多数の反復による結果を表します。適度な時間で正確な結果を得るために、シミュレーションは S/N 比 (SNR) ごとに 200 個以上のビット エラーと、多くても 5000 までのデータ パケットを収集します。パケットは 2000 メッセージ ビットを表します。SNR の範囲は、1 dB から 5 dB です。
iterCntThreshold = 5000; minErrThreshold = 200; msgL = 2000; snrdb = 1:5;
初期化
関数 transceiver を 1 回呼び出し、設定時間とオブジェクト作成オーバーヘッドを抽出します。オブジェクトは各関数の永続変数に保存されます。
errs = zeros(length(snrdb),1); iters = zeros(length(snrdb),1); berplot = cell(1,5); numframes = 500; % GPU version runs 500 frames in parallel. viterbiTransceiverCPU(-10,1,1); viterbiTransceiverGPU(-10,1,1,numframes); N=1; % N tracks which simulation variant is run
ワークフロー
この例のワークフローは以下のとおりです。
System object のベースライン シミュレーションを実行
MATLAB Coder を使用して、シミュレーション用の MEX 関数を生成
parfor を使用して、ビット エラー レート シミュレーションを並列実行
生成された MEX 関数を parfor と組み合わせ
GPU ベースの System object を使用
fprintf(1,'Bit Error Rate Acceleration Analysis Example\n\n');
Bit Error Rate Acceleration Analysis Example
ベースラインのシミュレーション
さまざまな高速化方法の基準点を確定するために、System object のみを使用してビット エラー レートを生成します。このコンポーネントのコードは viterbiTransceiverCPU.m に含まれています。
fprintf(1,'***Baseline - Standard System object simulation***\n'); % Create random stream for each snrdb simulation s = RandStream.create('mrg32k3a','NumStreams',1,... 'CellOutput',true,'NormalTransform','Inversion'); RandStream.setGlobalStream(s{1}); ts = tic; for ii=1:numel(snrdb) fprintf(1,'Iteration number %d, SNR (dB) = %d\n',ii,snrdb(ii)); [errs(ii),iters(ii)] = viterbiTransceiverCPU( ... snrdb(ii),minErrThreshold,iterCntThreshold); end ber = errs./ (msgL* iters); baseTime=toc(ts); berplot{N} = ber; desc{N} = 'baseline'; reportResultsCommSysGPU(N,baseTime,baseTime,'Baseline');
***Baseline - Standard System object simulation*** Iteration number 1, SNR (dB) = 1 Iteration number 2, SNR (dB) = 2 Iteration number 3, SNR (dB) = 3 Iteration number 4, SNR (dB) = 4 Iteration number 5, SNR (dB) = 5 ---------------------------------------------------------------------------------------------- Versions of the Transceiver | Elapsed Time (sec)| Acceleration Ratio 1. Baseline | 33.5735 | 1.0000 ----------------------------------------------------------------------------------------------
コード生成
MATLAB Coder を使用して、あらかじめコンパイルされた MATLAB コードと一致する最適化された C コードと MEX ファイルを生成できます。関数 viterbiTransceiverCPU は MATLAB コード生成サブセットに適合するため、修正せずに MEX 関数にコンパイルできます。
例のこの部分を実行するには、MATLAB Coder ライセンスが必要です。
fprintf(1,'\n***Baseline + codegen***\n'); N=N+1; % Increase simulation counter % Create the coder object and turn off checks which will cause low % performance. fprintf(1,'Generating Code ...'); config_obj = coder.config('MEX'); config_obj.EnableDebugging = false; config_obj.IntegrityChecks = false; config_obj.ResponsivenessChecks = false; config_obj.EchoExpressions = false; % Generate a MEX file codegen('viterbiTransceiverCPU.m','-config','config_obj','-args', ... {snrdb(1),minErrThreshold,iterCntThreshold} ) fprintf(1,' Done.\n'); % Run once to eliminate startup overhead. viterbiTransceiverCPU_mex(-10,1,1); s = RandStream.getGlobalStream; reset(s); % Use the generated MEX function viterbiTransceiverCPU_mex in the % simulation loop. ts = tic; for ii=1:numel(snrdb) fprintf(1,'Iteration number %d, SNR (dB) = %d\n',ii,snrdb(ii)); [errs(ii),iters(ii)] = viterbiTransceiverCPU_mex( ... snrdb(ii),minErrThreshold,iterCntThreshold); end ber = errs./ (msgL* iters); trialtime=toc(ts); berplot{N} = ber; desc{N} = 'codegen'; reportResultsCommSysGPU(N,trialtime,baseTime,'Baseline + codegen');
***Baseline + codegen*** Generating Code ...Code generation successful. Done. Iteration number 1, SNR (dB) = 1 Iteration number 2, SNR (dB) = 2 Iteration number 3, SNR (dB) = 3 Iteration number 4, SNR (dB) = 4 Iteration number 5, SNR (dB) = 5 ---------------------------------------------------------------------------------------------- Versions of the Transceiver | Elapsed Time (sec)| Acceleration Ratio 1. Baseline | 33.5735 | 1.0000 2. Baseline + codegen | 23.9754 | 1.4003 ----------------------------------------------------------------------------------------------
Parfor - パラレル ループ実行
MATLAB は parfor を使用して、すべての SNR 値に対して送受信コードを並列実行します。これには、並列プールを開き、parfor ループを追加する必要があります。
例のこの部分を実行するには、Parallel Computing Toolbox のライセンスが必要です。
fprintf(1,'\n***Baseline + parfor***\n'); fprintf(1,'Accessing multiple CPU cores ...\n'); if isempty(gcp('nocreate')) pool = parpool; poolWasOpen = false; else pool = gcp; poolWasOpen = true; end nW=pool.NumWorkers; N=N+1; % Increase simulation counter snrN = numel(snrdb); mT = minErrThreshold / nW; iT = iterCntThreshold / nW; errN = zeros(nW,snrN); itrN = zeros(nW,snrN); % Replicate snrdb snrdb_rep=repmat(snrdb,nW,1); % Create an independent stream for each worker s = RandStream.create('mrg32k3a','NumStreams',nW,... 'CellOutput',true,'NormalTransform','Inversion'); % Pre-run parfor jj=1:nW RandStream.setGlobalStream(s{jj}); viterbiTransceiverCPU(-10,1,1); end fprintf(1,'Start parfor job ... '); ts = tic; parfor jj=1:nW for ii=1:snrN [err, itr] = viterbiTransceiverCPU(snrdb_rep(jj,ii),mT,iT); errN(jj,ii) = err; itrN(jj,ii) = itr; end end ber = sum(errN)./ (msgL*sum(itrN)); trialtime=toc(ts); fprintf(1,'Done.\n'); berplot{N} = ber; desc{N} = 'parfor'; reportResultsCommSysGPU(N,trialtime,baseTime,'Baseline + parfor');
***Baseline + parfor*** Accessing multiple CPU cores ... Starting parallel pool (parpool) using the 'Processes' profile ... Connected to parallel pool with 4 workers. Start parfor job ... Done. ---------------------------------------------------------------------------------------------- Versions of the Transceiver | Elapsed Time (sec)| Acceleration Ratio 1. Baseline | 33.5735 | 1.0000 2. Baseline + codegen | 23.9754 | 1.4003 3. Baseline + parfor | 17.0594 | 1.9680 ----------------------------------------------------------------------------------------------
Parfor とコード生成
最後の 2 つの方法を組み合わせることで、さらに高速化することができます。コンパイルされた MEX 関数は、parfor ループ内部で実行できます。
例のこの部分を実行するには、MATLAB Coder のライセンスと Parallel Computing Toolbox のライセンスが必要です。
fprintf(1,'\n***Baseline + codegen + parfor***\n'); N=N+1; % Increase simulation counter % Pre-run parfor jj=1:nW RandStream.setGlobalStream(s{jj}); viterbiTransceiverCPU_mex(1,1,1); % use the same mex file end fprintf(1,'Start parfor job ... '); ts = tic; parfor jj=1:nW for ii=1:snrN [err, itr] = viterbiTransceiverCPU_mex(snrdb_rep(jj,ii),mT,iT); errN(jj,ii) = err; itrN(jj,ii) = itr; end end ber = sum(errN)./ (msgL*sum(itrN)); trialtime=toc(ts); fprintf(1,'Done.\n'); berplot{N} = ber; desc{N} = 'codegen + parfor'; reportResultsCommSysGPU(N,trialtime,baseTime, ... 'Baseline + codegen + parfor');
***Baseline + codegen + parfor*** Start parfor job ... Done. ---------------------------------------------------------------------------------------------- Versions of the Transceiver | Elapsed Time (sec)| Acceleration Ratio 1. Baseline | 33.5735 | 1.0000 2. Baseline + codegen | 23.9754 | 1.4003 3. Baseline + parfor | 17.0594 | 1.9680 4. Baseline + codegen + parfor | 8.6619 | 3.8760 ----------------------------------------------------------------------------------------------
GPU
viterbiTransceiverGPU 関数が使用する System object は GPU での実行時に利用できます。GPU ベース バージョン:
comm.gpu.ConvolutionalEncoder - 畳み込み符号化
comm.gpu.PSKModulator - QPSK 変調
comm.gpu.PSKDemodulator - QPSK 復調 (approx LLR)
comm.gpu.ViterbiDecoder - ビタビ復号化
大量データの一括処理には、GPU が最も効果的です。GPU ベースの System object は 1 回の step メソッドの呼び出しで複数のフレームを処理できます。変数 numframes は呼び出しごとに処理されるフレーム数を表します。並列処理が viterbiTransceiverCPU の呼び出し単位ではなく、オブジェクト単位であるという点を除き、これは parfor に類似しています。
例のこの部分を実行するには、Parallel Computing Toolbox ライセンスとサポートされている GPU デバイスが必要です。サポートされているデバイスについては、GPU 計算の要件 (Parallel Computing Toolbox)を参照してください。
fprintf(1,'\n***GPU***\n'); N=N+1; %Increase simulation counter try dev = parallel.gpu.GPUDevice.current; fprintf(... 'GPU detected (%s, %d multiprocessors, Compute Capability %s)\n',... dev.Name,dev.MultiprocessorCount,dev.ComputeCapability); sg = parallel.gpu.RandStream.create('mrg32k3a', ... 'NumStreams',1,'NormalTransform','Inversion'); parallel.gpu.RandStream.setGlobalStream(sg); ts = tic; for ii=1:numel(snrdb) fprintf(1,'Iteration number %d, SNR (dB) = %d\n',ii, snrdb(ii)); [errs(ii),iters(ii)] =viterbiTransceiverGPU( ... snrdb(ii),minErrThreshold,iterCntThreshold,numframes); end ber = errs./ (msgL* iters); trialtime=toc(ts); berplot{N} = ber; desc{N} = 'GPU'; reportResultsCommSysGPU(N,trialtime,baseTime,'Baseline + GPU'); fprintf(1,' Done.\n'); catch %#ok<CTCH> % Report that the appropriate GPU was not found. fprintf(1, ['Could not find an appropriate GPU or could not ', ... 'execute GPU code.\n']); end
***GPU*** GPU detected (GRID V100D-2Q, 80 multiprocessors, Compute Capability 7.0) Iteration number 1, SNR (dB) = 1 Iteration number 2, SNR (dB) = 2 Iteration number 3, SNR (dB) = 3 Iteration number 4, SNR (dB) = 4 Iteration number 5, SNR (dB) = 5 ---------------------------------------------------------------------------------------------- Versions of the Transceiver | Elapsed Time (sec)| Acceleration Ratio 1. Baseline | 33.5735 | 1.0000 2. Baseline + codegen | 23.9754 | 1.4003 3. Baseline + parfor | 17.0594 | 1.9680 4. Baseline + codegen + parfor | 8.6619 | 3.8760 5. Baseline + GPU | 0.8145 | 41.2208 ---------------------------------------------------------------------------------------------- Done.
解析
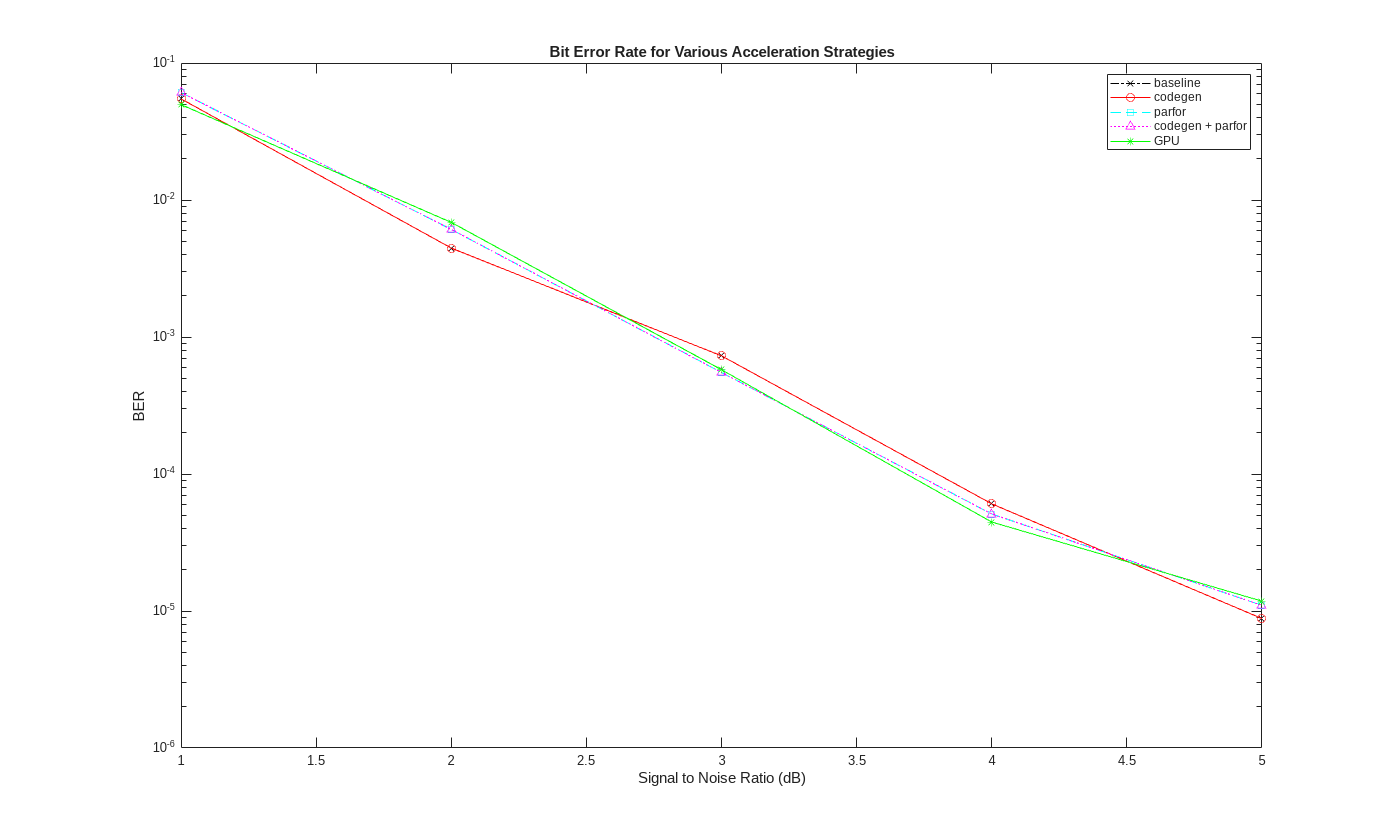
これらの試行結果を比較すると、すべてのシミュレーション高速化方法の中で GPU が圧倒的に速いことが明らかです。このパフォーマンス向上を実現するには、シミュレーション コードをごくわずかに変更するだけです。それにもかかわらず、以下のプロットが示すように、ビット エラー レート性能は失われません。曲線における微小な差異は、異なる乱数生成アルゴリズムや、曲線上の同じ点における異なるデータの品質を平均化したことの影響です。
lines = {'kx-.','ro-','cs--','m^:','g*-'};
for ii=1:numel(desc)
semilogy(snrdb,berplot{ii},lines{ii});
hold on;
end
hold off;
title('Bit Error Rate for Various Acceleration Strategies');
xlabel('Signal to Noise Ratio (dB)');
ylabel('BER');
legend(desc{:});

クリーンアップ
並列プールを元の状態にします。
if ~poolWasOpen delete(gcp); end
Parallel pool using the 'Processes' profile is shutting down.