Parallel Computing Toolbox を使用した BER シミュレーションの高速化
この例では、Parallel Computing Toolbox™ を使用してシンプルな QPSK ビット エラー レート (BER) シミュレーションを高速化します。システムは、QPSK 変調器、QPSK 復調器、AWGN チャネルおよびビット エラー レート カウンターから構成されます。
シミュレーション パラメーターを設定します。
EbNoVec = 5:8; % Eb/No values in dB totalErrors = 200; % Number of bit errors needed for each Eb/No value totalBits = 1e7; % Total number of bits transmitted for each Eb/No value
helper_qpsk_sim_with_awgn 関数によって生成されるデータを格納するために使用する配列にメモリを割り当てます。
[numErrors, numBits] = deal(zeros(length(EbNoVec),1));
シミュレーションを実行し、実行時間を判別します。プロセッサを 1 つだけ使用して、ベースライン性能を見極めます。結果として、通常の for ループが使用されていることがわかります。
tic for idx = 1:length(EbNoVec) errorStats = helper_qpsk_sim_with_awgn(EbNoVec,idx, ... totalErrors,totalBits); numErrors(idx) = errorStats(idx,2); numBits(idx) = errorStats(idx,3); end simBaselineTime = toc;
BER を計算します。
ber1 = numErrors ./ numBits;
Parallel Computing Toolbox が使用可能な場合のシミュレーションを再び実行します。ワーカーのプールを作成します。
pool = gcp; assert(~isempty(pool), ['Cannot create parallel pool. '... 'Try creating the pool manually using ''parpool'' command.'])
Starting parallel pool (parpool) using the 'Processes' profile ... 17-Jan-2025 15:54:13: Job Queued. Waiting for parallel pool job with ID 1 to start ... Connected to parallel pool with 6 workers.
使用可能なワーカーの数を pool の NumWorkers プロパティから求めます。前のメソッドで最大性能への改善が行われたので、このシミュレーションでは、それぞれのワーカーに 1 つの 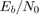 点を割り当てるのではなく、 値の範囲をそれぞれのワーカーにおいて実行します。
点を割り当てるのではなく、 値の範囲をそれぞれのワーカーにおいて実行します。
numWorkers = pool.NumWorkers;
入れ子にされた parfor ループで使用するための EbNoVec の長さを決定します。変数が適切に分類されるように、parfor に入れ子にされる for ループの範囲は定数または変数で定義しておかなければなりません。
lenEbNoVec = length(EbNoVec);
helper_qpsk_sim_with_awgn 関数によって生成されるデータを格納するために使用する配列にメモリを割り当てます。
[numErrors,numBits] = deal(zeros(length(EbNoVec),numWorkers));
シミュレーションを実行し、実行時間を判別します。
tic parfor n = 1:numWorkers for idx = 1:lenEbNoVec errorStats = helper_qpsk_sim_with_awgn(EbNoVec,idx, ... totalErrors/numWorkers,totalBits/numWorkers); numErrors(idx,n) = errorStats(idx,2); numBits(idx,n) = errorStats(idx,3); end end simParallelTime = toc;
BER を計算します。この場合、複数のプロセッサの結果を組み合わせて集計 BER を導き出さなければなりません。
ber2 = sum(numErrors,2) ./ sum(numBits,2);
BER 値を比較して、ワーカーの数に関係なく同じ結果が得られることを確認します。
semilogy(EbNoVec',ber1,'-*',EbNoVec',ber2,'-^') legend('Single Processor','Multiple Processors','location','best') xlabel('Eb/No (dB)') ylabel('BER') grid
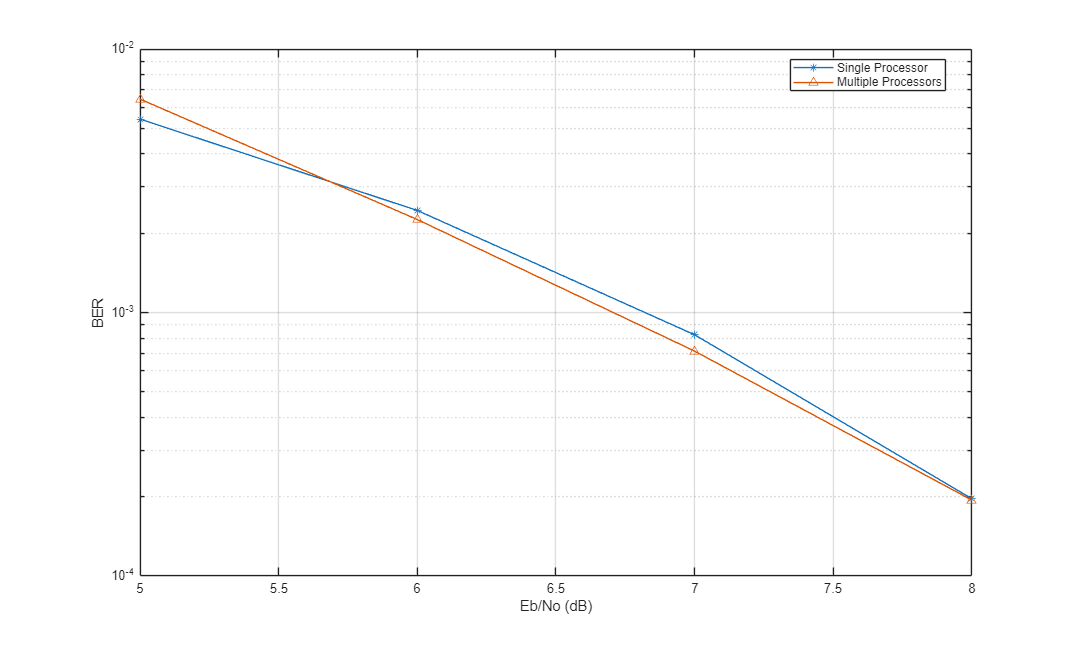
乱数のシードが異なるので、BER 曲線はどの分散でも基本的には同じであるということがわかります。
各メソッドの実行時間を比較します。
fprintf(['\nSimulation time = %4.1f sec for one worker\n', ... 'Simulation time = %4.1f sec for multiple workers\n'], ... simBaselineTime,simParallelTime) fprintf('Number of processors for parfor = %d\n', numWorkers)
Simulation time = 313.8 sec for one worker Simulation time = 78.1 sec for multiple workers Number of processors for parfor = 6
参考
parfor | gcp (Parallel Computing Toolbox)