このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
行優先のレイアウトのコード設計
コード生成の範囲外では、MATLAB® は既定で列優先のレイアウトを使用します。配列レイアウトの指定は、自己完結した MATLAB コードに影響を与えません。生成コードまたは MATLAB Function ブロックの効率をテストするには、別々のバージョンを作成して、それぞれ行優先のレイアウトと列優先のレイアウトを指定します。そして、そのパフォーマンスを比較します。
配列レイアウトに関連して起こり得る効率低下を回避するように、MATLAB コードを設計できます。効率の低下は、以下によって発生する可能性があります。
行優先のレイアウトと列優先のレイアウトの変換
行優先のデータの 1 次元または線形インデックス操作
行優先のデータの変形または並べ替え
配列レイアウト変換は、同一のコードまたはモデル内に行優先のレイアウトの指定と列優先のレイアウトの指定を混在させたとき、または、行優先で保存されたデータに線形インデックスを使用したときに必要です。列優先を使用し、かつ行優先を使用する MATLAB Function ブロックを含むモデルのシミュレーションまたはコード生成を行う場合、必要に応じてソフトウェアは、入力データを行優先に変換し、出力データを列優先に変換して戻します。また、その逆も行います。
効率の低下は、選択された配列レイアウトへの最適化が十分になされていない関数やアルゴリズムによって起こることがあります。もし、別のレイアウトの方が関数やアルゴリズムの効率が向上するならば、coder.rowMajor または coder.columnMajor 呼び出しによって別の関数に埋め込むことで、そのレイアウトを強制できます。
配列レイアウトによって起こる可能性のある効率低下の理解
coder.ceval を使用して、行優先のレイアウトと列優先のレイアウトのデータを受け渡す、myMixedFn2 のコードを考えます。
function [B, C] = myMixedFn2(x,y) %#codegen % specify type of return arguments for ceval calls A = zeros(size(x)); B = zeros(size(x)); C = zeros(size(x)); % include external C functions that use row-major & column-major coder.cinclude('addMatrixRM.h'); coder.updateBuildInfo('addSourceFiles', 'addMatrixRM.c'); coder.cinclude('addMatrixCM.h'); coder.updateBuildInfo('addSourceFiles', 'addMatrixCM.c'); % call C function that uses column-major order coder.ceval('-layout:columnMajor','addMatrixCM', ... coder.rref(x),coder.rref(y),coder.wref(A)); % compute B for i = 1:numel(A) B(i) = A(i) + 7; end % call C function that uses row-major order coder.ceval('-layout:rowMajor','addMatrixRM', ... coder.rref(y),coder.rref(B),coder.wref(C)); end
外部ファイルは次のとおりです。
構成オブジェクト、cfg を宣言します。-rowmajor オプションを使用して、行優先のレイアウトを使用するコードを生成します。
cfg = coder.config('lib'); cfg.HighlightPotentialRowMajorIssues = true; codegen myMixedFn2 -args {ones(20,10),ones(20,10)} -config cfg -launchreport -rowmajor
ハイライトされる問題が、[コードの洞察] タブの [潜在的な行優先の問題] セクションにあるコード生成レポートに表示されます。
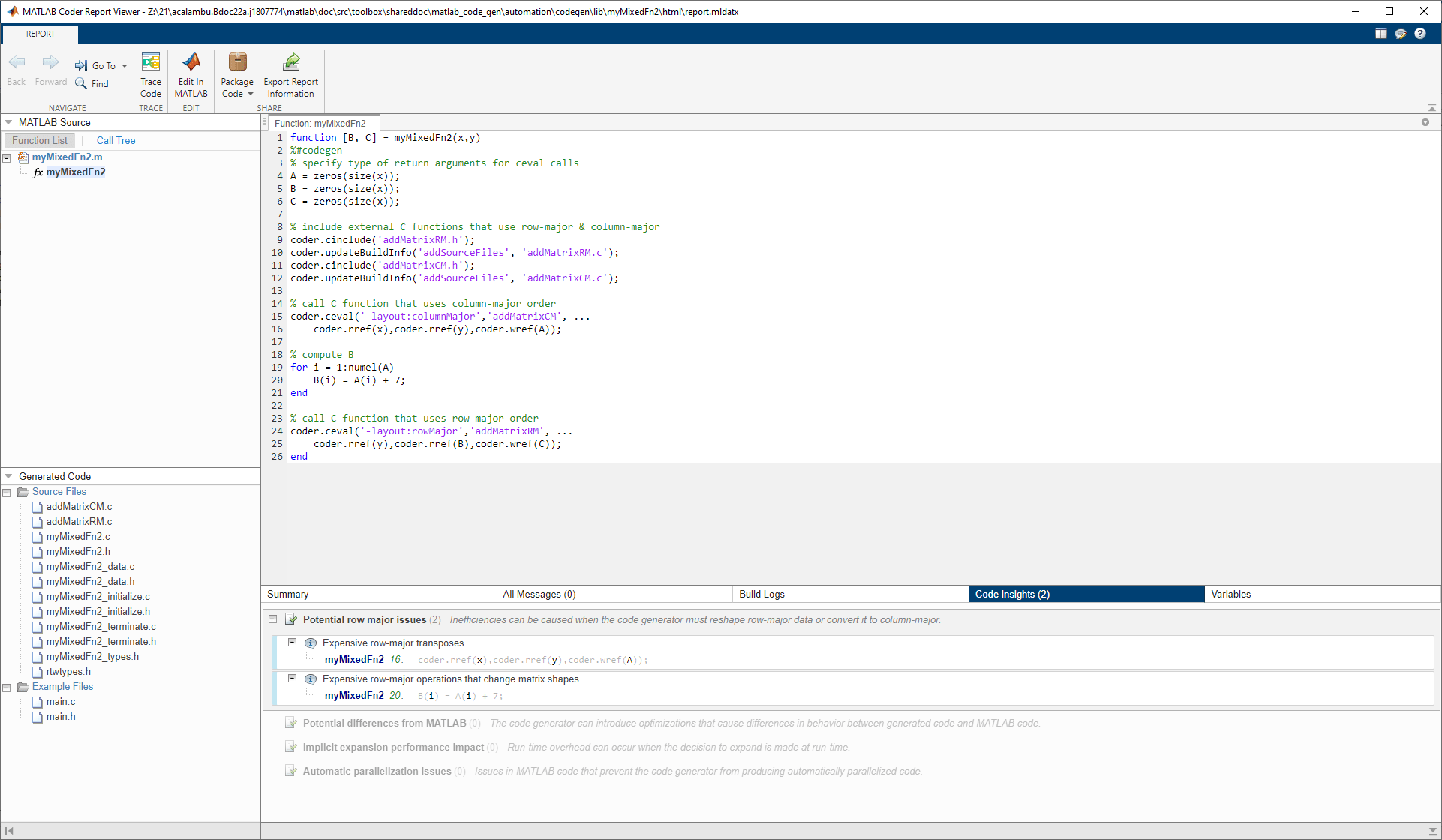
ここでは、以下の理由によって配列レイアウトの効率低下が起こっています。
コード ジェネレーターが入力変数
xとyを、addMatrixCMに受け渡す前に、列優先のレイアウトに変換しなければなりません。生成されたコードに転置を挿入しなければなりません。myMixedFn2は行優先のレイアウトを使用するため、コード ジェネレーターは、出力変数Aを転置して行優先のレイアウトに戻さなければなりません。for ループが、列優先のデータを要する線形インデックス操作を使用しています。変数
AとBが行優先のレイアウトで格納されているため、コード ジェネレーターは線形インデックス操作を再計算しなければなりません。
列優先のレイアウトを使用する線形インデックス操作
コード ジェネレーターは、線形インデックス操作について MATLAB の列優先のセマンティクスに従います。MATLAB の線形インデックス操作の詳細については、配列インデックス付けを参照してください。
行優先のデータに線形インデックス操作を使用するには、コード ジェネレーターはまずデータ表現を列優先のレイアウトで再計算しなければなりません。この追加処理により、パフォーマンスが低速化することがあります。コードの効率を向上するため、行優先のデータについては線形インデックス操作の使用を避けるか、線形インデックス操作を使用するコードでは列優先のレイアウトを使用してください。
たとえば、入力として行列を受け入れ、スカラー値を出力する、関数 sumShiftedProducts を考えます。この関数は、各行列要素の隣接する要素との積を総計するために、線形インデックス操作を使用します。この演算の出力値は、入力要素が格納される順番によって決まります。
function mySum = sumShiftedProducts(A) %#codegen mySum = 0; % create linear vector of A elements B = A(:); % multiply B by B with elements shifted by one, and take sum mySum = sum( B.*circshift(B,1) ); end
MATLAB Coder™ で、行優先のレイアウトを使用するコードを生成するには、以下を入力します。
codegen -config:mex sumShiftedProducts -args {ones(2,3)} -launchreport -rowmajor
入力の例として、以下の行列を考えます。
D = reshape(1:6,3,2)'
これにより、以下が得られます。
D =
1 2 3
4 5 6
この行列を生成されたコードの入力として受け渡す場合、A の要素は以下の順番で格納されます。
1 2 3 4 5 6
逆に、ベクトル B は、線形インデックス操作で得られるため、以下の順番で格納されます。
1 4 2 5 3 6
コード ジェネレーターは、A の行優先のレイアウトを B の列優先のレイアウトにデータを並べ替える、変形演算を挿入しなければなりません。この追加の演算により、行優先のレイアウトの関数の効率が低下します。効率低下の度合いは、配列のサイズが大きいほど大きくなります。線形インデックス操作では常に列優先のレイアウトが使用されるため、sumShiftedProducts で生成されたコードは、行優先のレイアウトで生成しても、列優先のレイアウトで生成しても、同じ出力結果となります。
一般的に、インデックスや添字を計算する関数は線形インデックス操作も使用していることが多く、列優先のレイアウトで格納されたデータに対応する結果を生成します。このような関数には、以下があります。
参考
coder.ceval | coder.columnMajor | coder.rowMajor | coder.isRowMajor | coder.isColumnMajor