このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
信号ラベラー
対象となる信号の属性、領域および点へのラベル付け
説明
信号ラベラー アプリは、解析のため、または機械学習と深層学習のアプリケーションで使用するために信号のラベル付けが可能な対話型のツールです。信号ラベラーを使用して、次のことができます。
対象となる信号の属性、領域および点へのラベル付け
スペクトログラムの時間-周波数関心領域へのラベル付け (R2025a 以降)
logical、categorical、numerical、または string の値が付いたラベルの使用
信号ピークまたは有界信号領域の自動ラベル付け
カスタム ラベル付け関数の適用
オーディオ信号のインポート、ラベル付け、再生
周波数および時間-周波数ビューを使用した、時間領域でのラベル付け支援
時間ビューを使用した、時間-周波数領域でのラベル付け支援 (R2025a 以降)
信号、スペクトログラム、ラベル マスクを含むデータ セットの作成 (R2025a 以降)
ラベルまたはサブラベルの追加、編集、および削除
信号とラベルの選択されたサブセットの表示
信号ラベラーは、データを labeledSignalSet オブジェクトとして保存します。labeledSignalSet オブジェクトを MATLAB® または診断特徴デザイナー (Predictive Maintenance Toolbox)にエクスポートできます。データ セットをファイルとして作成して、ネットワークや分類器に学習させたり、データを解析して統計をレポートしたりできます。
詳細については、信号ラベラー アプリの使用を参照してください。
オーディオ信号のインポート、再生、ラベル付けを行うには、Audio Toolbox™ のライセンスが必要です。
MATLAB Online ではオーディオ再生はサポートされていません。
ラベル付けされた信号セットを診断特徴デザイナーにエクスポートするには、Predictive Maintenance Toolbox™ のライセンスが必要です。
信号ラベラーは特徴抽出モードをサポートしていませんが、現在はアプリとして利用可能です。信号の特徴を抽出するには、MATLAB ツールストリップまたはコマンド ウィンドウから信号特徴抽出器を開きます。

信号ラベラー アプリを開く
MATLAB ツールストリップ: [アプリ] タブの [信号処理と通信] でアプリのアイコンをクリックします。
MATLAB コマンド プロンプト:
signalLabelerと入力します。
例
この例では、[ダッシュボード] を使用して、ラベル付けの進行状況を追跡し、ラベルの品質を評価する方法を示します。このモードでは、ラベル付けされているメンバーの数をすばやく確認し、データ セット内のラベル値と持続時間の分布を検査できます。この手順により、機械学習のための完全かつ正確なデータ セットを容易に取得できるようになります。
データのダウンロードと準備
関数 QTdownload を使用して、一般に公開されている QT データベース [1] [2] から新しい一時ディレクトリ folder に心電図 (ECG) 信号をダウンロードします。この関数のコードは、この例の終わりにあります。
folder = QTdownload;
各ファイルには、ECG 信号 ecgSignal、領域ラベル signalRegionLabels のテーブル、およびサンプル レート変数 Fs が格納されます。信号のサンプル レートはすべて 250 Hz です。領域ラベルは次の 3 つの心拍形態に対応しています。
P 波
QRS 群
T 波
folder を示す信号データストアを作成します。信号変数名 ecgSignal と サンプル レート変数 Fs を指定します。
sds = signalDatastore(folder,SignalVariableNames="ecgSignal", ... SampleRateVariableName="Fs");
最初の 20 ファイルを含むデータストアのサブセットを作成します。このサブセットを labeledSignalSet オブジェクトのソースとして使用します。
subsds = subset(sds,1:20); lss = labeledSignalSet(subsds);
関心領域のラベル付け
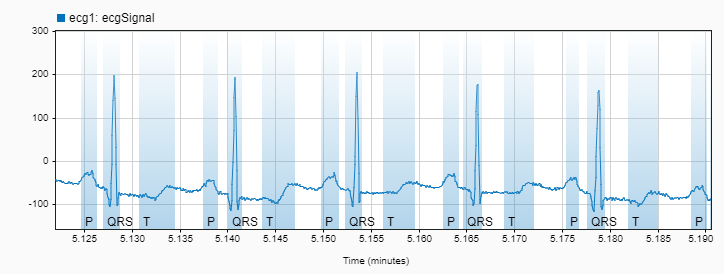
"信号ラベラー" アプリを開き、ラベル付き信号セットをワークスペースからインポートします。データ セットの最初の信号をプロットします。[表示] タブでパナーを選択し、信号の狭い領域が見やすくなるように拡大します。

[ラベラー] タブで、P、QRS、および T カテゴリのカテゴリカル関心領域 (ROI) ラベルを定義します。ラベル BeatMorphologies に名前を付けます。
カスタムのラベル付け関数 labelECGregions を作成し、3 種類の関心領域の位置を特定してラベルを付けます。カスタム関数のコードは、後ほどこの例で示します。この関数は、現在のフォルダーか MATLAB パス上に保存するか、[値の自動処理] ギャラリーの Add Custom Function を選択してアプリに追加することができます。詳細については、カスタム ラベル付け関数を参照してください。
[ラベルの定義] ブラウザー内で BeatMorphologies を選択し、[値の自動処理] ギャラリーから関数 labelECGregions を選択します。Auto-Label を選択してから Auto-Label and Inspect Plotted を選択します。[実行] をクリックします。[表示] タブで、ラベル付き信号の領域を拡大し、パナーを使用して時間を操作します。ラベル付けが十分な場合は、[ラベルの保存] をクリックしてラベルを受け入れ、[自動ラベル付け] タブを閉じます。ラベルとその位置の値は [ラベル付き信号セットのメンバー] ブラウザーで確認できます。
ラベル付けの進行状況と統計の可視化
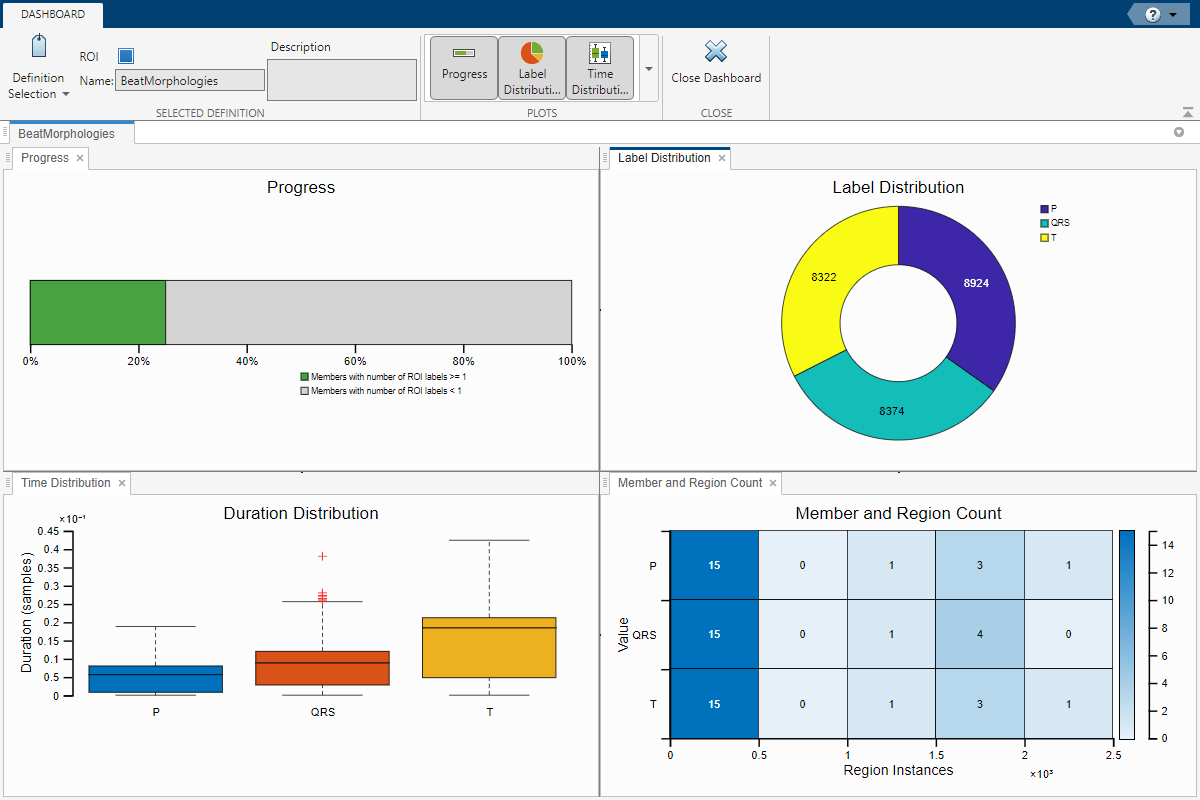
[ラベラー] タブのツールストリップで [ダッシュボード] を選択します。進行状況バーを見ると、メンバーの 5% が少なくとも 1 つのROI ラベルでラベル付けされていることが分かります。これは、データ セット内のメンバーの 1/20 に相当します。ラベル分布の円グラフは、選択したラベルの定義のカテゴリごとのインスタンスの数を示しています。

ダッシュボードを閉じてラベル付けを継続します。Auto-Label を選択してから Auto-Label All Signals を選択し、リストの次の 4 つの信号をラベル付けします。ラベル付けする信号名の隣のボックスをオンにしてから、[OK] をクリックします。
[ダッシュボード] を再度選択します。進行状況バーを見ると、メンバーの 25% がラベル付けされたことが分かります。各カテゴリ (P、QRS、または T) の分布が想定どおりであることを確認します。Label Distribution 円グラフから、各カテゴリがすべてのラベルのインスタンスの約 1/3 で構成されていることが分かります。[プロット] ギャラリーから Time Distribution ヒストグラム チャートを選択し、P 波、T 波および QRS 群の平均持続時間と、外れ値を表示します。T 波の持続時間は、P 波と QRS 群より長いことに注意してください。
Member Count チャートを表示して、メンバー全体のラベルの分布とインスタンスの数をより明確に可視化します。データ セット内のほとんどのメンバーで、P、QRS、および T の各領域のインスタンス数は 0 ~ 500 です。
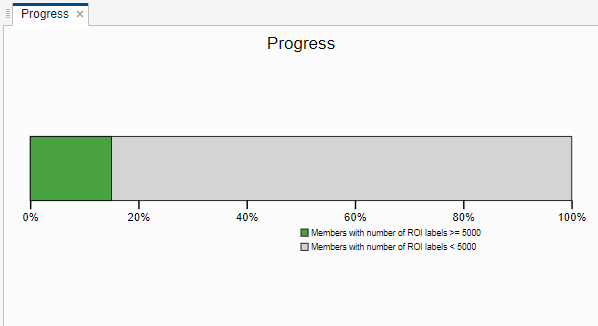
進行状況バーのプロットをクリックし、ラベル数が 5000 以上のメンバーのみをカウントするようにツールストリップで Threshold を調整します。これで、5 つのラベル付きメンバーのうち、3 つのみがカウントに含まれるようになります。ラベル付きのメンバーとラベルなしのメンバーをラベル付け要件に基づいてより適切に区別できるように、カウントしきい値を調整します。
関数 labelECGregions
関数 labelECGregions は事前学習済みの深層学習ネットワークを使用して、ECG 信号の P、QRS、および T の心拍形態を特定します。
function [labelVals,labelLocs] = labelECGregions(x,t,parentLabelVal,parentLabelLoc,varargin) labelVals = cell(2,1); labelLocs = cell(2,1); if nargin < 5 Fs = 250; else Fs = varargin{1}; end % Download the pretrained network netfil = matlab.internal.examples.downloadSupportFile("SPT", ... "data/QTDatabaseECGSegmentationNetworks.zip"); %#ok<*UNRCH> unzip(netfil,fullfile(tempdir,"ECGnet")) load(fullfile(tempdir,"ECGnet","trainedNetworks.mat")) for kj = 1:size(x,2) sig = x(:,kj)'; predTest = classify(rawNet,sig,MiniBatchSize=50); msk = signalMask(predTest); msk.SpecifySelectedCategories = true; msk.SelectedCategories = find(msk.Categories ~= "n/a"); labels = roimask(msk); labelVals{kj} = labels.Value; labelLocs{kj} = labels.ROILimits/Fs; end labelVals = vertcat(labelVals{:}); labelLocs = cell2mat(labelLocs); end
関数 QTdownload
データ ファイルは https://www.mathworks.com/supportfiles/SPT/data/QTDatabaseECGData.zip からダウンロードできます。または、unzip 関数を使用して、210 個の MAT ファイルが含まれたフォルダーを一時ディレクトリに作成することもできます。
function folder = QTdownload localfile = matlab.internal.examples.downloadSupportFile("SPT", ... "data/QTDatabaseECGData1.zip"); unzip(localfile,tempdir) folder = fullfile(tempdir,"QTDataset"); end
参考文献
[1] Goldberger, Ary L., Luis A. N. Amaral, Leon Glass, Jeffery M. Hausdorff, Plamen Ch. Ivanov, Roger G. Mark, Joseph E. Mietus, George B. Moody, Chung-Kang Peng, and H. Eugene Stanley. "PhysioBank, PhysioToolkit, and PhysioNet: Components of a New Research Resource for Complex Physiologic Signals." Circulation. Vol. 101, No. 23, 2000, pp. e215–e220. [Circulation Electronic Pages; http://circ.ahajournals.org/content/101/23/e215.full].
[2] Laguna, Pablo, Roger G. Mark, Ary L. Goldberger, and George B. Moody. "A Database for Evaluation of Algorithms for Measurement of QT and Other Waveform Intervals in the ECG." Computers in Cardiology. Vol.24, 1997, pp. 673–676.