このページは前リリースの情報です。該当の英語のページはこのリリースで削除されています。
動画処理システムのマルチコア シミュレーション
この例では、Simulink® のデータフロー実行領域を使用して、動画処理システムを複数のコア上で実行する方法を説明します。
はじめに
データフロー実行領域により、計算量の多いシステムの設計で複数のコアを使用できます。この例では、サブシステムの実行領域としてのデータフローでモデルのシミュレーション パフォーマンスを改善する方法を説明します。データフローと、複数のスレッドを使用して Simulink モデルを実行する詳細については、Multicore Execution Using Dataflow Domain (DSP System Toolbox)を参照してください。
ビデオ内のオブジェクトのカウント
この例では、基本的なモルフォロジー演算子を使ってビデオ ストリームから情報を抽出する方法を説明します。ここでは、モデルによって各ビデオ フレームにあるホチキスの針の数をカウントします。このモデルは Top-hat ブロックを使用して不均一な明るさを排除してから、Autothreshold ブロックを使用してバイナリ イメージに変換します。その後 Blob Analysis ブロックを使用して、針の数をカウントしてそれぞれの針の重心を計算します。Draw Markers ブロックと Insert Text ブロックを使用して針をマークし、ビデオ フレームで検出された針の数を書き込みます。

Dataflow Subsystem の設定
この例では、Simulink でデータフロー領域を使用し、デスクトップ上の複数のコアを利用してシミュレーション パフォーマンスを向上させます。このモデルの dataflow subsystem の [領域] パラメーターは、Dataflow として設定されます。これを表示するには、サブシステムを選択してからプロパティ インスペクターにアクセスします。プロパティ インスペクターにアクセスするには、Simulink ツールストリップの [モデル化] タブの [設計] ギャラリーで [プロパティ インスペクター] を選択するか、[シミュレーション] タブの [準備] ギャラリーで [プロパティ インスペクター] を選択します。
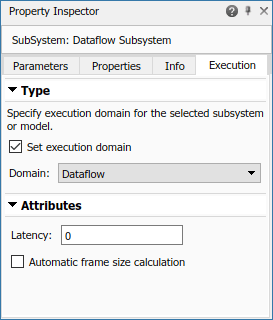
データフロー領域は、モデルを複数のスレッドに自動的に分割し、パフォーマンスを向上させます。[領域] パラメーターを Dataflow に設定すると、[マルチコア] タブの解析を使用してモデルを解析し、パフォーマンスを向上させることができます。モデルにデータフロー領域がある場合は、ツールストリップで [マルチコア] タブを利用できます。[マルチコア] タブの詳細については、Perform Multicore Analysis for Dataflow (DSP System Toolbox)を参照してください。

Dataflow Subsystem の同時実行の解析
この例では、シミュレーション パフォーマンス解析のために [マルチコア] タブ モードが Simulation Profiling に設定されています。
最適なシミュレーション パフォーマンスのためには、モデル設定を最適化することを推奨します。推奨されたモデル設定を受け入れるには、[マルチコア] タブで [最適化] をクリックします。または、[最適化] ボタンの下にあるドロップダウン メニューを使用して、設定を個別に変更することもできます。この例では、既に最適なモデル設定になっています。
[マルチコア] タブで、[解析の実行] ボタンをクリックして、シミュレーション パフォーマンスのデータフロー領域の解析を開始します。解析の終了後、[データフロー解析レポート] ウィンドウに Dataflow Subsystem がシミュレーション中に使用するスレッド数が表示されます。
モデルを解析した後は、モデル内のブロック間のデータ依存関係によってブロックが同時に実行されないため、[データフロー解析レポート] ウィンドウに 1 つのスレッドが表示されます。データ依存のブロックをパイプライン化することによって、dataflow subsystem は、データ スループットを上げるために同時実行を増やすことができます。[データフロー解析レポート] ウィンドウには、パイプライン遅延の推奨数が [同時実行性を高めるための提案] として表示されます。推奨レイテンシの値は最高のパフォーマンスを得られるように計算されます。
次の図は、dataflow subsystem の推奨レイテンシが 2 である [データフロー解析レポート] ウィンドウを示しています。
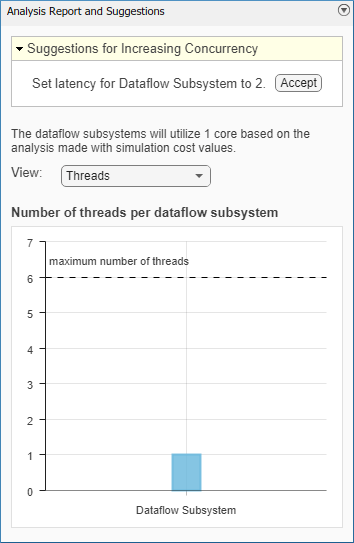
[承諾] ボタンをクリックして、Dataflow Subsystem の推奨レイテンシを使用します。この値は、[レイテンシ] パラメーターとして [プロパティ インスペクター] で直接入力することもできます。Simulink では、Dataflow Subsystem の出力端子で ![]() タグを使用してレイテンシ パラメーターの値が表示されます。
タグを使用してレイテンシ パラメーターの値が表示されます。
[データフロー解析レポート] ウィンドウにスレッド数が 2 と表示されました。これは、dataflow subsystem 内部のブロックが 2 つのスレッドを使用してシミュレーションを並列実行していることを意味します。[スレッドの強調表示] は、[スレッド強調表示の凡例] に示すように、スレッドの割り当てに基づいてブロックを色で強調表示します。[パイプライン遅延の表示] は、![]() タグを使用して、Dataflow Subsystem 内でパイプライン遅延が挿入された場所を示します。
タグを使用して、Dataflow Subsystem 内でパイプライン遅延が挿入された場所を示します。
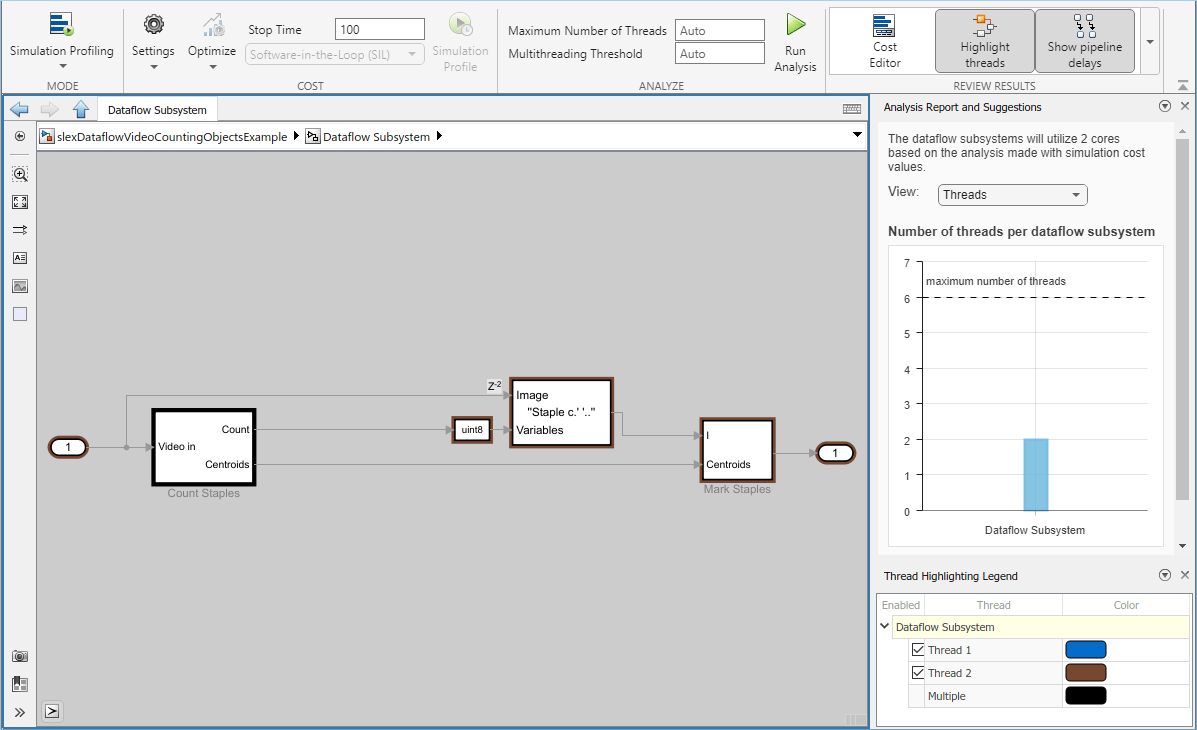
マルチコア シミュレーションのパフォーマンス
データフローを使用する場合と使用しない場合でモデル実行にかかる実行時間を比較して、データフロー領域の使用によるパフォーマンスの改善を測定します。実行時間は sim コマンドを使用して測定されます。これによりモデルのシミュレーション実行時間が返されます。実行時間の測定中、主として dataflow subsystem にかかる時間を測定するために、Video Viewer ブロックはコメント化されています。これらの数字と解析は、Intel® Xeon® CPU W-2133 @ 3.6 GHz、6 コア、12 スレッドのプロセッサを使用する Windows® デスクトップ コンピューターで得られたものです。
Simulation execution time for multithreaded model = 7.56s Simulation execution time for single-threaded model = 13.58s Actual speedup with dataflow: 1.8x
まとめ
この例では、データフロー領域を使用するマルチスレッドによって、デスクトップで複数のコアを使用して動画処理モデルのパフォーマンスを向上できる方法を示します。