このページは機械翻訳を使用して翻訳されました。最新版の英語を参照するには、ここをクリックします。
分布近似によるヒストグラムのプロット
この例では、ThingSpeak ™チャネルのデータに分布を適合させる方法を示します。マサチューセッツ州の高速道路の交通密度データのヒストグラムと分布への適合を同時に生成します。
カーカウンタ ThingSpeakチャネルからデータを読み取る
車両カウンター ThingSpeakチャネルは、Raspberry Pi™ とウェブカメラを使用して、交通量の多い高速道路上の車両をカウントします。Raspberry Pi 上で車のカウントアルゴリズムが実行され、15 秒ごとにカウントされた車の密度が ThingSpeak に送信されます。フィールド 1 と 2 には、それぞれ東行きと西行きの交通データが含まれています。
data = thingSpeakRead(38629,'NumDays',1,'Fields',[1,2],'outputFormat','table');
データをフィルタリングする
分布を適合する前に、データをフィルタリングしてゼロを削除します。
data_without_zeros = data.DensityOfEastboundCars(data.DensityOfEastboundCars > 0);
ヒストグラムをプロットして分布を近似する
東行きの交通データをヒストグラムとして可視化し、normal、poisson、gamma、kernel などの分布を適合させます。データを可視化すると、基礎となる分布の形状を理解するのに役立ちます。ノンパラメトリックカーネル平滑化分布を適合します。
number_of_bins = 20; histfit(data_without_zeros,number_of_bins,'kernel'); xlabel('Bins for density of cars every 15 seconds'); title('Fitting Kernel Function on Distribution of Eastbound Cars in the Past Day');
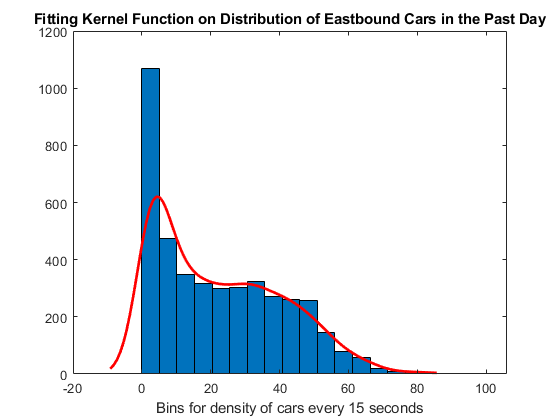
ヒストグラムとフィッティングにより、分布が右に偏っていることがわかります。
参考
関数
histfit(Statistics and Machine Learning Toolbox) |thingSpeakRead