このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
実験マネージャーを使用した回帰モデルの調整
この例では、実験マネージャーを使用して機械学習回帰モデルを最適化する方法を示します。目標は、交差検証損失が最小になる carbig データ セット用の回帰モデルを作成することです。最初に、回帰学習器アプリを使用して、利用可能なすべての回帰モデルに学習データで学習させます。その後、最適なモデルを実験マネージャーにエクスポートして改良します。
実験マネージャーで、既定の設定を使用して交差検証損失を最小化します (つまり、交差検証の平方根平均二乗誤差を最小化します)。損失の改善に役立つオプションを調べ、より詳しい実験を実行します。たとえば、一部のハイパーパラメーターの最適な値への固定、モデル調整プロセスへの有用なハイパーパラメーターの追加、ハイパーパラメーターの検索範囲の調整、学習データの調整、可視化のカスタマイズを行います。最終結果は、テスト セットの性能が向上したモデルです。
回帰学習器から実験マネージャーにどのような場合にモデルをエクスポートするかの詳細については、回帰学習器から実験マネージャーへのモデルのインポートを参照してください。
データの読み込みと分割
MATLAB® コマンド ウィンドウで、
carbigデータ セットを読み込みます。このデータ セットには、1970 年代と 1980 年代初期に製造された自動車の測定値が格納されています。load carbig目標は、自動車のガロンあたりの走行マイル数を自動車の他の測定値に基づいて予測する回帰モデルを作成することです。
米国製かどうかに基づいて、自動車を分類します。
Origin = categorical(cellstr(Origin)); Origin = mergecats(Origin,["France","Japan","Germany", ... "Sweden","Italy","England"],"NotUSA");
Acceleration、Displacementなどの予測子変数と応答変数MPG(ガロンあたりの走行マイル数) が格納された table を作成します。cars = table(Acceleration,Displacement,Horsepower, ... Model_Year,Origin,Weight,MPG);carsから table に欠損値がある行を削除します。cars = rmmissing(cars);
データを 2 つのセットに分割します。観測値の約 80% を回帰学習器でのモデルの学習に使用し、観測値の約 20% を最終的なテスト セット用に確保します。
cvpartitionを使用してデータを分割します。rng(0,"twister") % For reproducibility c = cvpartition(height(cars),"Holdout",0.2); trainingIndices = training(c); testIndices = test(c); carsTrain = cars(trainingIndices,:); carsTest = cars(testIndices,:);
回帰学習器でのモデルの学習
Parallel Computing Toolbox™ がある場合は、回帰学習器アプリでモデルに並列に学習させることができます。モデルを並列に学習させた方がモデルを順番に学習させるよりも一般に速くなります。Parallel Computing Toolbox がない場合は、スキップして次の手順に進んでください。
アプリを開く前に、関数
parpoolを使用してプロセス ワーカーの並列プールを起動します。parpool("Processes")スレッド ワーカーではなくプロセス ワーカーの並列プールを起動しておけば、この後に実験マネージャーで確実に同じプールを使用できます。
メモ
実験マネージャーでは、スレッド プールを使用した並列計算はサポートされません。
回帰学習器を開きます。[アプリ] タブをクリックしてから、[アプリ] セクションの右にある矢印をクリックしてアプリ ギャラリーを開きます。[機械学習および深層学習] グループの [回帰学習器] をクリックします。
[学習] タブで、[ファイル] セクションの [新規セッション] をクリックし、[ワークスペースから] を選択します。
[ワークスペースからの新規セッション] ダイアログ ボックスで、[データ セット変数] のリストから table
[carsTrain]を選択します。応答変数と予測子変数が選択されます。既定の応答変数は[MPG]です。[検証] セクションで、5 分割交差検証ではなく 3 分割交差検証を使用するように指定します。
[テスト] セクションで、[テスト データ セットの確保] チェック ボックスをクリックします。インポートされたデータの
25パーセントをテスト セットとして指定します。オプションはそのままで続行するため、[セッションの開始] をクリックします。
開いている [応答プロット] で予測子を視覚的に検査します。[X 軸] セクションで、[X] のリストから各予測子を選択します。
[Displacement]、[Horsepower]、[Weight]など、同様のトレンドを示す予測子がいくつかあるため注意してください。モデルに学習させる前に、主成分分析 (PCA) を使用して予測子空間の次元を減らします。PCA は、数値予測子を線形的に変換することにより冗長な次元を削除します。[学習] タブの [オプション] セクションで [PCA] をクリックします。
[既定の PCA オプション] ダイアログ ボックスで、PCA を有効にするチェック ボックスをクリックします。成分の削除基準として
[成分数の指定]を選択し、数値成分の数として4を指定します。[保存して適用] をクリックします。最適なモデルを得るために、事前設定されたすべてのモデルに学習させます。[学習] タブの [モデル] セクションで矢印をクリックしてギャラリーを開きます。[開始] グループで [すべて] をクリックします。[学習] セクションで、[すべてを学習] をクリックして [すべてを学習] を選択します。事前設定された各モデル タイプの学習が既定の複雑な木のモデルと共に 1 つずつ行われ、モデルが [モデル] ペインに表示されます。
最良の結果を見つけるには、検証平方根平均二乗誤差 (RMSE) に基づいて学習済みモデルを並べ替えます。[モデル] ペインで [並べ替え] リストを開き、
[RMSE (検証)]を選択します。
メモ
検証により、結果に無作為性が導入されます。実際のモデルの検証結果は、この例に示されている結果と異なる場合があります。
最適なモデルの性能の評価
RMSE が最も低いモデルについて、予測された応答と真の応答をプロットして、異なる応答値について回帰モデルがどの程度適切に予測を行うかを調べます。この例では、[モデル] ペインで Matern 5/2 GPR モデルを選択します。[学習] タブの [プロットと結果] セクションで矢印をクリックしてギャラリーを開き、[検証結果] グループの [予測と実際 (検証)] をクリックします。
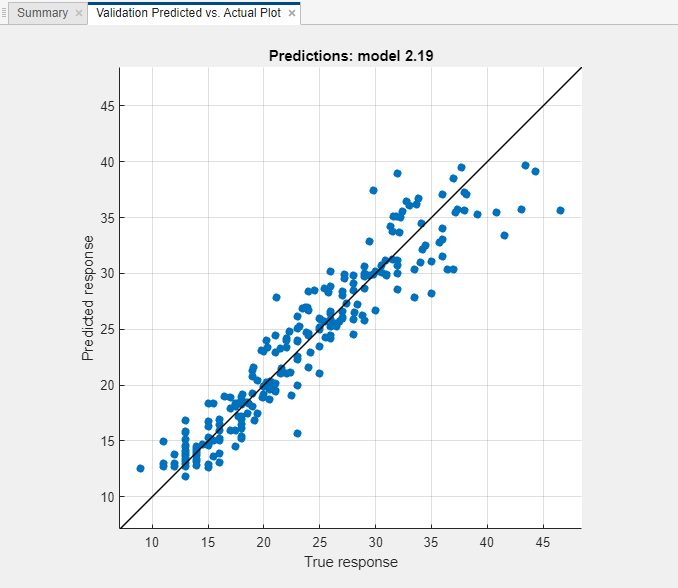
全体に、GPR (ガウス過程回帰) モデルの性能は良好です。ほとんどの予測が対角線の近くにあります。
残差プロットを表示します。[学習] タブの [プロットと結果] セクションで矢印をクリックしてギャラリーを開き、[検証結果] グループの [残差 (検証)] をクリックします。残差プロットには、真の応答と予測された応答の差が表示されます。

残差が 0 を挟んでほぼ対称になっています。
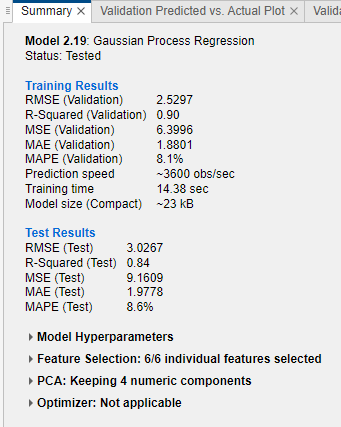
モデルのテスト セット性能を確認します。[テスト] タブの [テスト] セクションで [選択項目をテスト] をクリックします。学習データと検証データを含むデータ セット全体で学習させたモデルのテスト セットの性能が計算されます。
モデルの検証 RMSE とテスト RMSE を比較します。モデルの [概要] タブで、[学習結果] の [RMSE (検証)] の値と [テスト結果] の [RMSE (テスト)] の値を比較します。この例では、テスト セットに対するモデルの性能が検証 RMSE で過大に推定されています。
実験マネージャーへのモデルのエクスポート
モデルの予測性能を改善できるか試すために、モデルを実験マネージャーにエクスポートします。[学習] タブで、[エクスポート] セクションの [モデルのエクスポート] をクリックし、[実験の作成] を選択します。[実験の作成] ダイアログ ボックスが開きます。

[実験の作成] ダイアログ ボックスで [実験の作成] をクリックします。アプリで実験マネージャーと新しいダイアログ ボックスが開きます。

ダイアログ ボックスで、実験のプロジェクトとして新規または既存のいずれかを選択します。この例では、新しいプロジェクトを作成し、[プロジェクト フォルダー名を指定] ダイアログ ボックスでファイル名を
TrainGPRModelProjectと指定します。
既定のハイパーパラメーターでの実験の実行
実験を逐次的または並列に実行します。
メモ
Parallel Computing Toolbox がある場合は、時間の節約のために実験を並列に実行します。[実験マネージャー] タブの [実行] セクションで、[モード] リストから
[同時]を選択します。それ以外の場合は、[モード] の既定のオプションである
[逐次]を使用します。
[実験マネージャー] タブの [実行] セクションで、[実行] をクリックします。
実験マネージャーで、実験の結果を表示する新しいタブが開きます。アプリでは、[Experiment1] タブにある [ハイパーパラメーター] のテーブルの指定に従って、試行ごとに異なる組み合わせのハイパーパラメーター値を使用してモデルの学習が行われます。
アプリで実験が実行された後、その結果を確認します。結果のテーブルで、[ValidationRMSE] 列の矢印をクリックし、[昇順に並べ替え] を選択します。

既定では [Sigma] ハイパーパラメーターと [Standardize] ハイパーパラメーターがアプリで調整されることに注意してください。
RMSE が最も低いモデルの予測と実際のプロットを確認します。[実験マネージャー] タブの [結果の確認] セクションで [予測と実際 (検証)] をクリックします。アプリの [可視化] ペインにモデルのプロットが表示されます。
プロットを見やすくするために、[可視化] ペインを [実験ブラウザー] ペインの下にドラッグします。

このモデルでは、予測された値が真の応答値の近くにあります。ただし、ガロンあたりの走行マイル数が 40 ~ 50 の値については、モデルで応答が過小に評価される傾向があります。
ハイパーパラメーターとハイパーパラメーター値の調整
このデータ セットには、学習前に数値予測子を標準化することが最適であるように見えます。より優れたモデルが得られるか試すために、
Standardizeハイパーパラメーターの値をtrueと指定して実験をもう一度実行します。[Experiment1] タブをクリックします。[ハイパーパラメーター] のテーブルでStandardizeハイパーパラメーターの行を選択します。次に、[削除] をクリックします。学習関数ファイルを開きます。[学習関数] セクションで [編集] をクリックします。アプリで
Experiment1_training1.mlxファイルが開きます。関数
fitrgpが使用されているコード行をファイルで検索します。この関数は、GPR モデルの作成に使用されます。名前と値の引数を使用して予測子データを標準化します。ここでは、fitrgpの 4 つの呼び出しについて、'Standardize',trueを追加して次のように調整します。regressionGP = fitrgp(predictors, response, ... paramNameValuePairs{:}, 'KernelParameters', kernelParameters, ... 'Standardize', true);
regressionGP = fitrgp(predictors, response, ... paramNameValuePairs{:}, 'Standardize', true);
regressionGP = fitrgp(trainingPredictors, trainingResponse, ... paramNameValuePairs{:}, 'KernelParameters', kernelParameters, ... 'Standardize', true);
regressionGP = fitrgp(trainingPredictors, trainingResponse, ... paramNameValuePairs{:}, 'Standardize', true);
コードの変更を保存し、ファイルを閉じます。
[実験マネージャー] タブの [実行] セクションで、[実行] をクリックします。
実験で評価されるモデルをさらに変えるために、モデル調整プロセスにハイパーパラメーターを追加します。[Experiment1] タブの [ハイパーパラメーター] セクションで、[追加] の横にある矢印をクリックして [推奨リストから追加] を選択します。
[推奨リストから追加] ダイアログ ボックスで、
BasisFunction、KernelFunction、およびKernelScaleの各ハイパーパラメーターを選択し、[追加] をクリックします。学習データ セットにカテゴリカル予測子が含まれるため、値
pureQuadraticは基底関数のリストから削除する必要があります。[ハイパーパラメーター] セクションで、BasisFunctionの範囲を["constant","none","linear"]として指定します。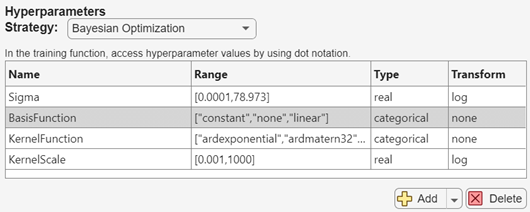
モデルで調整できるハイパーパラメーターの詳細については、回帰学習器から実験マネージャーへのモデルのインポートを参照してください。
より良い結果を得るために、複数のハイパーパラメーターを調整するときは試行回数を増やします。[Experiment1] タブの [ベイズ最適化オプション] セクションで、最大試行回数として
60を指定します。
[実験マネージャー] タブの [実行] セクションで、[実行] をクリックします。
学習データの指定
実験をもう一度実行する前に、
carsTrainのすべての観測値を使用するように指定します。学習データを回帰学習器にインポートするときに一部の観測値をテスト用に確保したため、これまでの実験では、いずれもcarsTrainデータ セットの観測値を 75% しか使用していません。実験ファイルを格納する
TrainGPRModelProjectフォルダーにcarsTrainデータ セットをファイルfullTrainingData.matとして保存します。これを行うには、MATLAB ワークスペースで変数名carsTrainを右クリックし、[名前を付けて保存] をクリックします。ダイアログ ボックスでファイル名と場所を指定し、[保存] をクリックします。[Experiment1] タブの [学習関数] セクションで [編集] をクリックします。
Experiment1_training1.mlxファイルでloadコマンドを検索します。コードを次のように調整して、carsTrainデータ セット全体をモデルの学習に使用するように指定します。% Load training data fileData = load("fullTrainingData.mat"); trainingData = fileData.carsTrain;
[Experiment1] タブの [説明] セクションで、観測値の数を table
carsTrainの行数に相当する314に変更します。[実験マネージャー] タブの [実行] セクションで、[実行] をクリックします。
残差プロットの追加
実験マネージャーの各試行で返す可視化を追加できます。ここでは、残差プロットを作成するように指定します。[Experiment1] タブの [学習関数] セクションで [編集] をクリックします。
Experiment1_training1.mlxファイルで関数plotを検索します。その周囲のコードで、学習させた各モデルについての検証の予測と実際のプロットが作成されます。次のコードを入力して残差プロットを作成します。残差プロットのコードは必ず関数trainRegressionModelの定義内に含めてください。% Create validation residuals plot residuals = validationResponse - validationPredictions; f = figure("Name","Residuals (Validation)"); resAxes = axes(f); hold(resAxes,"on") plot(resAxes,validationResponse,residuals,"ko", ... "MarkerFaceColor","#D95319") yline(resAxes,0) xlabel(resAxes,"True response") ylabel(resAxes,"Residuals (MPG)") title(resAxes,"Predictions: GPR")
[実験マネージャー] タブの [実行] セクションで、[実行] をクリックします。
結果のテーブルで、[ValidationRMSE] 列の矢印をクリックし、[昇順に並べ替え] を選択します。

RMSE が最も低いモデルの予測と実際のプロットと残差プロットを確認します。[実験マネージャー] タブの [結果の確認] セクションで [予測と実際 (検証)] をクリックします。アプリの [可視化] ペインにモデルのプロットが表示されます。

[実験マネージャー] タブの [結果の確認] セクションで [残差 (検証)] をクリックします。アプリの [可視化] ペインにモデルのプロットが表示されます。

両方のプロットから、モデルの性能が全般に良好であることがわかります。
最終モデルのエクスポートと使用
実験マネージャーで学習させたモデルを MATLAB ワークスペースにエクスポートできます。最後に実行された実験から得られた最適なモデルを選択します。[実験マネージャー] タブで、[エクスポート] セクションの [エクスポート] をクリックし、[学習の出力] を選択します。
[エクスポート] ダイアログ ボックスで、ワークスペース変数名を
finalGPRModelに変更して [OK] をクリックします。新しい変数がワークスペースに表示されます。
エクスポートした
finalGPRModel構造体を使用して、新しいデータによる予測を行います。構造体は、回帰学習器アプリからエクスポートした学習済みモデルを使用する場合と同じように使用できます。詳細については、エクスポートしたモデルを使用した新しいデータについての予測を参照してください。ここでは、
carsTestのテスト データの応答値を予測します。testPredictedY = finalGPRModel.predictFcn(carsTest);
予測された応答値を使用してテスト RMSE を計算します。
testRSME = sqrt((1/length(testPredictedY))* ... sum((carsTest.MPG - testPredictedY).^2))testRSME = 2.6647テスト RMSE は、実験マネージャーで計算された検証 RMSE (
2.6894) とほぼ同等です。また、この調整後のモデルのテスト RMSE の方が、回帰学習器での Matern 5/2 GPR モデルのテスト RMSE (3.0267) よりも小さくなっています。ただし、調整後のモデルではcarsTestの観測値をテスト データとして使用しているのに対し、回帰学習器のモデルではcarsTrainの観測値のサブセットをテスト データとして使用している点に注意してください。真のテスト データの応答と予測された応答を使用して、予測と実際のプロットと残差プロットを作成します。
figure line([min(carsTest.MPG) max(carsTest.MPG)], ... [min(carsTest.MPG) max(carsTest.MPG)], ..., "Color","black","LineWidth",2); hold on plot(carsTest.MPG,testPredictedY,"ko", ... "MarkerFaceColor","#0072BD"); hold off xlabel("True response") ylabel("Predicted response")

figure residuals = carsTest.MPG - testPredictedY; plot(carsTest.MPG,residuals,"ko", ... "MarkerFaceColor","#D95319") hold on yline(0) hold off xlabel("True response") ylabel("Residuals (MPG)")
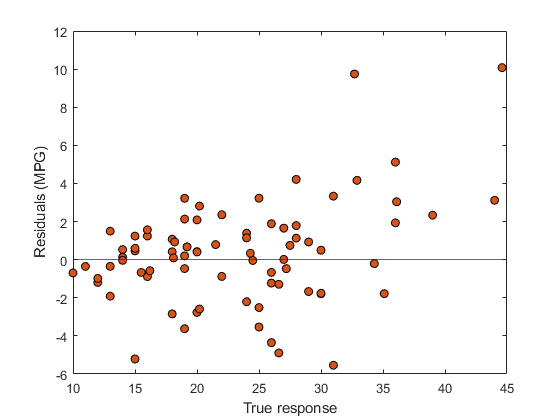
両方のプロットから、テスト セットにおけるモデルの性能が良好であることがわかります。
参考
アプリ
関数
トピック
- 回帰学習器から実験マネージャーへのモデルのインポート
- 新しいデータによる予測のための回帰モデルのエクスポート
- 実験の管理 (Deep Learning Toolbox)